







在Java编程中,IO(输入输出)是重要的组成部分,Java应用常常需要从外界输入数据或者把数据输出到外界。
Java IO的核心用一句话概括:抽象类或接口之中的抽象方法会根据实例化子类的不同,会完成不同的功能。所有的IO操作都在java.io包之中进行定义,而且整个java.io包常用的七个类和一个接口:
(1)五个类:File、InputStream、OutputStream、BufferedInputStream、BufferedOutputStream、Reader、Wirter;
(2)一个接口:Serializable。
一、文件操作类File
在整个java.io包之中,File类是唯一的一个与文件本身操作有关的类,所谓的文件本身指的是:文件的创建、删除、重命名、取得文件大小、修改日期。
1、文件类对象实例化
如果要想使用File类操作文件的话,那么肯定要通过构造方法实例化File类对象,而实例化File类对象的过程之中主要使用以下两种构造方法:
(1)public File(String pathname);//主要在Java EE的开发之中
(2)public File(File parent, String child);//主要在Android开发之中
2、文件的基本操作
文件的基本操作,主要有两种功能:创建和删除
(1)创建文件:
public boolean createNewFile() throws IOException;
(2)删除文件:
public boolean delete();
范例:
import java.io.File;
public class TestDemo {
public static void main(String[] args) throws Exception {
File file = new File("D:\\demo.txt"); // 文件的路径
if (file.exists()) { // 文件存在
file.delete(); // 删除文件
} else { // 文件不存在
file.createNewFile(); // 创建新文件
}
}
}
本程序操作就表示文件如果存在则删除,如果不存在,则创建一个新的文件,此时基本功能是实现了,不过这个程序此时却存在问题:
(1)关于路径分隔符
在windows操作系统之中,使用“\”作为路径分隔符,而在linux系统下使用“/”作为路径的分隔符,而从实际的开发而言,大部分情况下都会在windows中做开发,而后将项目部署到linux下,那么此时,路径的分隔符都需要进行修改,这样实在是过于麻烦,为此在File类之中提供了一个常量:
public static final String separator
(按照Java的命名规范来讲,对于全局常量应该使用大写字母的方式定义,而此处使用的是小写,是由Java的发展历史所带来的问题)。
所以以上程序实例化File类对象修改为:
File file = new File("D:" + File.separator + "demo.txt"); // 文件的路径
(2)之前进行文件创建的时候都是在根路径下创建完成的,如果说现在要创建的文件有目录呢?
例如,现在要创建一个d:\hellodemo\my\test\demo.txt文件,而此时在执行程序的时候hellodemo目录不存在,这个时候执行的话就会出现错误提示:
Exception in thread “main” java.io.IOException: 系统找不到指定的路径。
因为现在目录不存在,所以不能创建,那么这个时候必须要首先判断要创建文件的父路径是否存在,如果不存在应该创建一个目录,之后再进行文件的创建,而要想完成这样的操作,需要以下几个方法的支持:
①找到一个指定文件的父路径:
public File getParentFile();
②创建目录:
public boolean mkdirs();
范例:
import java.io.File;
public class TestDemo {
public static void main(String[] args) throws Exception {
File file = new File("D:" + File.separator + "hellodemo"
+ File.separator + "my" + File.separator + "test"
+ File.separator + "demo.txt"); // 文件的路径
if (!file.getParentFile().exists()) { // 父路径不存在
file.getParentFile().mkdirs(); // 创建目录
}
if (file.exists()) { // 文件存在
file.delete(); // 删除文件
} else { // 文件不存在
file.createNewFile(); // 创建新文件
}
}
}
以后在任何的java.io.File类开发的过程之中,都一定要考虑文件目录的问题。
3、获取文件的基本信息
除了以上的常用的方法之外,在File类之中还可以通过以下的方法取得一些文件的基本信息:
(1)取得文件的名称:
public String getName();
(2)给定的路径是否是文件夹:
public boolean isDirectory();
(3)给定的路径是否是文件:
public boolean isFile();
(4)是否是隐藏文件:
public boolean isHidden();
(5)文件的最后一次修改日期:
public long lastModified();
(6)取得文件大小:
public long length();
是以字节为单位返回的。
二、字节流与字符流
使用File类执行的所有操作都是针对于文件本身,但是却没有针对于文件的内容,而要进行文件内容操作就需要通过Java之中提供的两组类完成:
(1)字节操作流:OutputStream、InputStream;
(2)字符操作流:Writer、Reader。
但是不管是字节流还是字符流的操作,本身都表示资源操作,而执行所有的资源操作都会按照如下的几个步骤进行,下面以文件操作为例(对文件进行读、写操作):
(1)如果要操作的是文件,那么首先要通过File类对象找到一个要操作的文件路径(路径有可能存在,有可能不存在,如果不存在,则要创建路径);
(2)通过字节流或字符流的子类为字节流或字符流的对象实例化(向上转型);
(3)执行读 / 写操作;
(4) 最后一定要关闭操作的资源(数据流属于资源操作,资源操作必须关闭)
1、字节流
OutputStream和InputStream是字节流的两个顶层父类。让他们提供了输出流类和输入流类通用API,字节流一般用于读写二进制数据,如图像和声音数据。
[1]输出流:OutputStream
java.io.OutputStream主要的功能是进行字节数据的输出的,这个类的定义如下:
public abstract class OutputStream
extends Object
implements Closeable, Flushable
发现OutputStream类定义的时候实现了两个接口:Closeable、Flushable,这两个接口的定义如下:
(1)Closeable (JDK 1.5推出):
public interface Closeable extends AutoCloseable {
public void close() throws IOException;
}
(2)Flushable(JDK 1.5推出):
public interface Flushable {
public void flush() throws IOException;
}
对于OutputStream类而言发现其本身定义的是一个抽象类(abstract class),按照抽象类的使用原则来讲,需要定义抽象类的子类,而现在如果要执行的是文件操作,则可以使用FileOutputStream子类完成,如果按照面向对象的开发原则,子类要为抽象类进行对象的实例化,而后调用的方法以父类中定义的方法为主,而具体的实现找实例化这个父类的子类完成,也就是说在整个的操作之中,用户最关心的只有子类的构造方法:
(1)实例化FileOutputStream(新建数据):
public FileOutputStream(File file) throws FileNotFoundException;
(2)实例化FileOutputStream(追加数据):
public FileOutputStream(File file, boolean append)
throws FileNotFoundException
当取得了OutputStream类的实例化对象之后,下面肯定要进行输出操作,在OutputStream类之中定义了三个方法:
(1)输出单个字节数据:
public abstract void write(int b) throws IOException;
(2)输出一组字节数据:
public void write(byte[] b) throws IOException;
(3)输出部分字节数据:
public void write(byte[] b, int off, int len) throws IOException;
范例:使用OutputStream向文件之中输出数据,输出路径:d:\demo\test.txt
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class TestDemo {
public static void main(String[] args) throws Exception {
//第一步:定义文件路径
File file = new File("D:"+File.separator + "demo"+ File.separator + "test.txt");
if(!file.getParentFile().exists()){
file.getParentFile().mkdirs();
}
//第二步:实例化输出流
OutputStream output = new FileOutputStream(file);
String data = "hello world !\r\nhello world !\r\nhello world !\r\nhello world !";
// 第三步:输出数据,要将数据变为字节数组输出
output.write(data.getBytes());
//第四步:关闭资源
output.close();
}
}
运行结果:

在整个的文件输出过程之中可以发现,如果现在要输出的文件不存在,那么会出现自动创建文件的情况,并且如果重复执行以上的代码,会出现新的内容覆盖掉旧内容的操作,所以下面可以使用FileOutputStream类的另外一个构造方法进行数据的追加:
OutputStream output = new FileOutputStream(file, true);
如果说现在不想全部内容输出,也可以使用另外一个write()方法部分内容输出:
output.write(data.getBytes(), 0, 5);
运行结果:
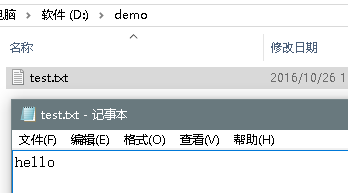
在OutputStream类之中所有的数据都是以字节数据为主的。
[2]输入流:InputStream
如果现在要从指定的数据源之中读取数据,使用InputStream,这个类的定义如下:
public abstract class InputStream
extends Object
implements Closeable
既然InputStream为抽象类,那么这个抽象类要使用就必须有子类,现在是通过文件读取内容,肯定使用FileInputStream子类进行操作,与OutputStream类的使用一样,对于FileInputStream也只关心构造方法:
public FileInputStream(File file) throws FileNotFoundException;
在InputStream类之中,定义了三个读取数据的操作方法:
(1)读取单个字节:
public abstract int read() throws IOException;
注意:每次执行read()方法都会读取一个数据源的指定数据,如果现在发现已经读取到了结尾返回-1;
(2)将读取的数据保存到字节数组中:
public int read(byte[] b) throws IOException;
注意:如果现在要读取的数据小于byte的数据,这个时候read()方法的返回值int返回的是数据个数,如果数据已经读完了,则这个时候的int返回的是-1;
(3)将读取的数据保存在部分字节数组中:
public int read(byte[] b, int off, int len) throws IOException;
范例:一次性全部读取数据进来
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public class TestDemo {
public static void main(String[] args) throws Exception {
//第一步:定义文件路径
File file = new File("D:" + File.separator + "demo" + File.separator + "test.txt"); // 定义文件路径
if (file.exists()) { // 文件存在则可以读取
//第二步:实例化输入流
InputStream input = new FileInputStream(file);
//第三步:读取数据到字节数组
byte data[] = new byte[1024]; // 假设要读的长度是1024
int len = input.read(data); // 读取数据,返回读取个数
//第四步:关闭资源
input.close();
System.out.println("读取的数据是:【" + new String(data, 0, len) + "】");
}
}
}
范例:单个字节读取
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public class TestDemo {
public static void main(String[] args) throws Exception {
File file = new File("D:" + File.separator + "demo" + File.separator + "test.txt"); // 定义文件路径
if (file.exists()) { // 文件存在则可以读取
InputStream input = new FileInputStream(file);
byte data[] = new byte[1024]; // 假设要读的长度是1024
int foot = 0; // 操作data数组的脚标
int temp = 0;
// 第一步:temp = input.read(),读取一个单个字节,并且将内容给temp变量
// 第二步:temp != -1,将接收到的temp的数值判断是否为-1,如果为-1则表示退出循环,如果不是,则保存数据
while ((temp = input.read()) != -1) {
data[foot++] = (byte) temp; // 保存读取进来的单个字节
}
input.close(); // 关闭
System.out.println("读取的数据是:【" + new String(data, 0, foot) + "】");
}
}
}
在今后开发中,都会使用以上的while循环方式进行数据的读取。
2、字符流
[1]字符输出流:Writer
Writer类也是一个专门用于数据输出的操作类,这个类定义:
public abstract class Writer
extends Object
implements Appendable, Closeable, Flushable
在Wirter类之中比OutputStream类最为方便的一点就是其可以直接使用String型数据输出,并且不再需要将其变为字节数组了。而Writer类本身也是一个抽象类,那么如果要使用依然要依靠它的子类,尤其是现在操作的是文件,使用FileWriter子类。
在Wirter类之中定义的write()方法都是以字符数据为主,但是在这些方法之中,只关心一个:输出一个字符串:
public void write(String str) throws IOException;
范例:使用Wirter类进行内容的输出
import java.io.File;
import java.io.FileWriter;
import java.io.Writer;
public class TestDemo {
public static void main(String[] args) throws Exception {
File file = new File("D:" + File.separator + "demo" + File.separator + "test.txt"); // 定义文件路径
if (!file.getParentFile().exists()) {
file.getParentFile().mkdirs();// 创建父目录
}
Writer out = new FileWriter(file);
String data = "Hello World .";
out.write(data); // 直接输出字符串
out.close(); // 关闭输出
}
}
运行结果:
从输出来讲,Wirter类的输出要比OutputStream类更加的方便。
[2]字符输入流:Reader
Reader是进行字符数据读取的操作类,其定义:
public abstract class Reader
extends Object
implements Readable, Closeable
在Writer类之中存在了直接输出一个字符串数据的方法,可是在Reader类之中并没有定义这样的方法,只是定义了三个按照字符读取的方法,为什么会这样?
因为在使用OutputStream输出数据的时候,其程序可以输出的大小一定是程序可以承受的数据大小,那么如果说使用InputStream读取的时候,可能被读取的数据非常的大,那么如果一次性全读进来了,就会出现问题,所以只能一个一个的进行读取。
在Reader类里也提供了一系列的read方法,其中一个:
读取内容到字符数组:
public int read (char[] cbuf) throws IOException;
1
注意:返回值表示读取的数据长度,如果已经读取到结尾。返回-1。
Reader依然是抽象类,那么如果从文件读取,依然使用FileReader类。
import java.io.File;
import java.io.FileReader;
import java.io.Reader;
public class TestDemo {
public static void main(String[] args) throws Exception {
File file = new File("D:" + File.separator + "demo" + File.separator + "test.txt"); // 定义文件路径
if (file.exists()) {
Reader in = new FileReader(file); // 字符输入流
char data[] = new char[1024]; // 开辟数组
int len = in.read(data); // 读取数据
in.close();
System.out.println("读取数据内容:【" + new String(data, 0, len) + "】");
}
}
}
三、 BufferedInputStream和BufferedOutputStream基本使用
BufferedInputStream
缓冲字节输入流,是一个高级流(处理流),与其他低级流配合使用。
构造方法
//创建一个 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。创建一个内部缓冲区数组并将其存储在 buf 中,该buf的大小默认为8192。
public BufferedInputStream(InputStream in);
//创建具有指定缓冲区大小的 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。创建一个长度为 size 的内部缓冲区数组并将其存储在 buf 中。
public BufferedInputStream(InputStream in,int size);
从构造方法中我们可以知道BufferedInputStream没有无参构造方法,它必须传入一个InputStream(一般是FileInputStream),来一起使用,以提高读写效率。
常用方法
//从该输入流中读取一个字节
public int read();
//从此字节输入流中给定偏移量处开始将各字节读取到指定的 byte 数组中。
public int read(byte[] b,int off,int len);
从文件中读入数据
import java.io.BufferedInputStream;
import java.io.FileInputStream;
/**
* BufferedInputStream:处理流(高级流),缓冲输入流
* @author Administrator
*
*/
public class BISDemo01 {
public static void main(String[] args){
try {
FileInputStream fis=new FileInputStream("BISDemo.txt");
BufferedInputStream bis=new BufferedInputStream(fis);
String content=null;
//自己定义一个缓冲区
byte[] buffer=new byte[10240];
int flag=0;
while((flag=bis.read(buffer))!=-1){
content+=new String(buffer, 0, flag);
}
System.out.println(content);
//关闭的时候只需要关闭最外层的流就行了
bis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
BufferedOutputStream的使用
BufferedOutputStream:缓冲字节输出流是一个高级流(处理流),与其他低级流配合使用。
构造方法
//创建一个新的缓冲输出流,以将数据写入指定的底层输出流。
public BufferedOutputStream(OutputStream out);
//创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流。
public BufferedOutputStream(OutputStream out,int size);
常用的方法
//向输出流中输出一个字节
public void write(int b);
//将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此缓冲的输出流。
public void write(byte[] b,int off,int len);
//刷新此缓冲的输出流。这迫使所有缓冲的输出字节被写出到底层输出流中。
public void flush();
向文件中写出数据
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
/**
* BufferedOutputStream:处理流(高级流),缓冲输出流
* @author Administrator
*
*/
public class BOSDemo01 {
public static void main(String[] args){
try {
FileOutputStream fos=new FileOutputStream("BOSDemo.txt");
BufferedOutputStream bos=new BufferedOutputStream(fos);
String content="我是缓冲输出流测试数据!";
bos.write(content.getBytes(),0,content.getBytes().length);
bos.flush();
bos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
使用缓冲输出流和缓冲输入流实现文件的复制
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
/**
* 使用缓冲输出流和缓冲输入流实现文件的复制
* @author Administrator
*
*/
public class SummaryBISAndBOS {
public static void main(String[] args){
/**
* 1.先将文件中的内容读入到缓冲输入流中
* 2.将输入流中的数据通过缓冲输出流写入到目标文件中
* 3.关闭输入流和输出流
*/
try {
long begin=System.currentTimeMillis();
FileInputStream fis=new FileInputStream("BISDemo.txt");
BufferedInputStream bis=new BufferedInputStream(fis);
FileOutputStream fos=new FileOutputStream("BOSDemo.txt");
BufferedOutputStream bos=new BufferedOutputStream(fos);
int size=0;
byte[] buffer=new byte[10240];
while((size=bis.read(buffer))!=-1){
bos.write(buffer, 0, size);
}
//刷新此缓冲的输出流,保证数据全部都能写出
bos.flush();
bis.close();
bos.close();
long end=System.currentTimeMillis();
System.out.println("使用缓冲输出流和缓冲输入流实现文件的复制完毕!耗时:"+(end-begin)+"毫秒");
} catch (Exception e) {
e.printStackTrace();
}
}
}
四、字节流与字符流的区别
通过以上的代码演示,现在可以发现,对于字节流和字符流可以完成类似的功能,那么在开发之中使用那一种呢?两者的区别:
字节流在进行IO操作的时候,直接针对的是操作的数据终端(例如:文件),而字符流操作的时候不是直接针对于终端,而是针对于缓存区(理解为内存)操作,而后由缓存取操作终端(例如:文件),属于间接操作,按照这样的方式,如果说在使用字节流的时候不关闭最后的输出流操作,也可以将所有的内容进行输出,而字符输出流的时候如果不关闭,则意味着缓冲区之中的内容不会被输出,当然,这个时候可以由用户自己去调用flush()方法进行强制性的手工清空:
import java.io.File;
import java.io.FileWriter;
import java.io.Writer;
public class TestDemo {
public static void main(String[] args) throws Exception {
File file = new File("D:" + File.separator + "demo"
+ File.separator + "test.txt"); // 定义文件路径
if (!file.getParentFile().exists()) {
file.getParentFile().mkdirs();// 创建父目录
}
Writer out = new FileWriter(file);
String data = "Hello World .";
out.write(data) ; // 直接输出字符串
out.flush() ; // 清空缓冲区
}
}
对于电脑磁盘或者是网络数据传输上,使用最多的数据类型都是字节数据,包括图片、音乐、各种可执行程序也都是字节数据,很明显,字节数据要比字符数据更加的广泛,但是在进行中文处理的过程之中,字符流又要比字节流方便许多,所以如果要使用的话,首先考虑的是字节流(还有一个原因是因为字节流和字符流的代码形式类似),如果有中文处理的问题,才会考虑使用字符流。
四、综合实例:文件拷贝
1、实现思路:
如果要想实现文件的复制那么肯定要使用的是字节流,因为文件有可能是图片,而对于这样的操作有两种实现方式:
(1)方式一:将要复制的文件内容全部读取到内存之中,而后将所有内容一次输出到目标文件之中;
(2)方式二:采用边读边写的方式一块一块的进行文件的拷贝。
很明显,使用方式二会更加的方便,因为如果要复制的文件很大,那么方式一是不可能在内存之中装如此只大的数据量,所以全部读取是不太可能的。
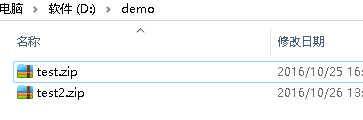
需要拷贝的文件如下,约47M:
2、拷贝程序:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
public class TestDemo {
public static void main(String[] args) throws Exception {
File inFile = new File("D:" + File.separator + "demo"
+ File.separator + "test.zip"); // 定义文件路径
File outFile = new File("D:" + File.separator + "demo"
+ File.separator + "test2.zip"); // 定义文件路径
long start = System.currentTimeMillis();
if (!inFile.exists()) { // 源文件不存在
System.out.println("源文件不存在!");
System.exit(1); // 程序退出
}
if(!outFile.getParentFile().exists()){
outFile.getParentFile().mkdirs();
}
InputStream input = new FileInputStream(inFile);
OutputStream output = new FileOutputStream(outFile);
int temp = 0;//保存每次读取的个数
byte data[] = new byte[4096]; // 每次读取4096字节
while ((temp = input.read(data)) != -1) { // 将每次读取进来的数据保存在字节数组里,并返回读取的个数
output.write(data, 0, temp); // 输出数组
}
long end = System.currentTimeMillis();
System.out.println("拷贝完成,所花费的时间:" + (end - start) + "毫秒");
input.close();
output.close();
}
}
运行结果:
拷贝完成,所花费的时间:125毫秒
查看文件:
InputStream : 是所有字节输入流的超类,一般使用它的子类:FileInputStream等,它能输出字节流;
InputStreamReader : 是字节流与字符流之间的桥梁,能将字节流输出为字符流,并且能为字节流指定字符集,可输出一个个的字符;
BufferedReader : 提供通用的缓冲方式文本读取,readLine读取一个文本行, 从字符输入流中读取文本,缓冲各个字符,从而提供字符、数组和行的高效读取。
在读取网络数据流的时候,可以通过先用InputStream获取字节流、InputStreamReader将字节流转化成字符流、BufferedReader将字符流以缓存形式输出的方式来快速获取网络数据流。















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









