







Windows系统搭建Kafka集群(3-broker)
kafka名词介绍
- Message:消息,就是要发送的内容,一般包装成一个消息对象。
- Topic:通俗来讲的话就是放置“消息”的地方,也就是说消息投递的一个容器。假如把消息看作是信封的话,那么Topic就是一个邮箱。
- Partition && Log
Partition分区,可以理解为一个逻辑上的分区,像是我们电脑的磁盘 C,D,E盘一样。
Kafka为每个分区维护着一份日志Log文件。 - Producers(生产者)
和其他消息队列一样,生产者通常都是消息的产生方。
在Kafka中它决定消息发送到指定Topic的哪个分区上。 - Consumers(消费者)
消费者就是消息的使用着,在消费者端也有几个名词需要区分一下。
一般消息队列有两种模式的消费方式,分别是队列模式和订阅模式。
队列模式:一对一,就是一个消息只能被一个消费者消费,不能重复消费。一般情况队列支持存在多个消费者,但是对于一个消息,只会有一个消费者可以消费它。
订阅模式:一对多,一个消息可能被多次消费,消息生产者将消息发布到Topic中,只要是订阅改Topic的消费者都可以消费。
Zookeeper集群
搭建Kafka集群需要先搭建Zookeeper集群
参考 : Windows系统ZooKeeper集群环境搭建
Kafka broker集群
-
这里我们以在同一台服务器配置3套Kafka为例,将Kafka分别安装到3个目录中。如:




-
编辑server.properties
(1) 打开 kafka_A 服务器的server.properties文件,修改或增加如下配置:#唯一标识 broker.id=0 #kafka消息存放的路径 log.dirs=E:/kafka/kafka_A/kafka_2.13-2.5.0/kafka-logs host.name=192.168.2.76 #监听端口 port=9097 #对应3台Zookeeper的IP地址和端口 zookeeper.connect=192.168.2.76:2181,192.168.2.76:2182,192.168.2.76:2183 listeners=PLAINTEXT://192.168.2.76:9097 advertised.listeners=PLAINTEXT://192.168.2.76:9097(2) 打开 kafka_B 服务器的server.properties文件,修改或增加如下配置:
#唯一标识 broker.id=1 #kafka消息存放的路径 log.dirs=E:/kafka/kafka_B/kafka_2.13-2.5.0/kafka-logs host.name=192.168.2.76 #监听端口 port=9098 #对应3台Zookeeper的IP地址和端口 zookeeper.connect=192.168.2.76:2181,192.168.2.76:2182,192.168.2.76:2183 listeners=PLAINTEXT://192.168.2.76:9098 advertised.listeners=PLAINTEXT://192.168.2.76:9098(3) 打开 kafka_C 服务器的server.properties文件,修改或增加如下配置:
#唯一标识 broker.id=2 #kafka消息存放的路径 log.dirs=E:/kafka/kafka_C/kafka_2.13-2.5.0/kafka-logs host.name=192.168.2.76 #监听端口 port=9099 #对应3台Zookeeper的IP地址和端口 zookeeper.connect=192.168.2.76:2181,192.168.2.76:2182,192.168.2.76:2183 listeners=PLAINTEXT://192.168.2.76:9099 advertised.listeners=PLAINTEXT://192.168.2.76:9099 -
启动服务
定位到3个Kafka安装目录,以管理员身份运行CMD(用于启动3个Kafka服务),然后分别在3个窗口中输入.\bin\windows\kafka-server-start.bat .\config\server.properties命令来启动这3个Kafka服务



-
验证Kafka服务是否启动,如果open则代表启动成功
执行下面命令:nc -vz 192.168.2.76 9097 nc -vz 192.168.2.76 9098 nc -vz 192.168.2.76 9099
nc安装参考:Windows 下载安装 netcat(nc)命令
到此,Kafka的集群环境就搭建好了。
Kafka命令配置
由于是集群操作,以前的Kafka操作命令就有所改变,如:
创建主题:
单机模式:
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic TestTopic1
或
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic TestTopic1
集群模式:
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181,localhost:2182,localhost:2183 --replication-factor 1 --partitions 1 --topic TestTopic1
或
kafka-topics --create --zookeeper localhost:2181,localhost:2182,localhost:2183 --replication-factor 1 --partitions 1 --topic TestTopic1
查询主题:
单机模式:
.\bin\windows\kafka-topics.bat --zookeeper localhost:2181 --list
或
kafka-topics --zookeeper localhost:2181 --list
集群模式:
.\bin\windows\kafka-topics.bat --zookeeper localhost:2181,localhost:2182,localhost:2183 --list
或
kafka-topics --zookeeper localhost:2181,localhost:2182,localhost:2183 --list
其他命令(如设置用户读写权限、分组权限等)操作也类似。
Kafka集群测试
创建生产者命令:
.\bin\windows\kafka-console-producer.bat --broker-list 192.168.2.76:9097,192.168.2.76:9098,192.168.2.76:9099 --topic muTopic
创建消费者命令:
.\bin\windows\kafka-console-consumer.bat --bootstrap-server 192.168.2.76:9097,192.168.2.76:9098,192.168.2.76:9099 --topic muTopic
创建一个生产者两个消费者,执行结果如下图:

执行生产者和消费者命令报下面错误:
[2020-07-06 13:55:43,935] WARN [Producer clientId=console-producer] Connection to node -2 (localhost/127.0.0.1:9099) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
解决方案:
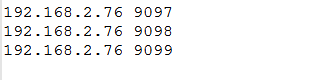
在C:\Windows\System32\drivers\etc目录下,修改hosts文件,新增下面命令:














 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









