






本文档为基于Hadoop和Spring Boot实现的深证A股个股日线数据分析Web系统的综合设计说明书。该系统旨在对股票数据进行保存、整理、分析和总结,并将分析结果在网站上进行可视化展示。系统以默认数据集中1766支股票从1999.12.09-2016.06.08的全部数据进行分析,绘制了深证指数的季K线图、季收盘价的走势图、季成交量柱状图、月涨跌幅热力图和成交量季度占比图。系统的大数据分析平台选择了Hadoop,利用MapReduce实现数据处理。后端使用了流行的Spring Boot框架,为上传文件和绘制可视化图表提供了接口服务。前端使用了Vue.js框架和Echarts,对处理完毕的数据进行可视化图表展示。本文档中详细介绍了该系统的需求分析、架构设计、MapReduce流程的设计、后端接口设计、前端图表设计以及系统的测试。详细代码可见gitee。
操作HDFS代码gitee仓库地址:
EHOH/Hadoop股票日线数据分析![]() https://gitee.com/EHOH/StockVolume完整后端代码gitee仓库地址:
https://gitee.com/EHOH/StockVolume完整后端代码gitee仓库地址:
bigdata: 大数据分析后端,hadoop部署于192.168.218.128,后端部署于10.34.31.145![]() https://gitee.com/GUET-wang-yilin/bigdata数据集下载地址:
https://gitee.com/GUET-wang-yilin/bigdata数据集下载地址:
深证A股个股日线数据_数据下载_免费数据下载_聚合数据 - 天聚地合![]() https://www.juhe.cn/market/product/id/10089
https://www.juhe.cn/market/product/id/10089
关键词:Hadoop;MapReduce;Spring Boot;Vue;Echarts。
1 需求分析
1.1 功能需求
k线图可以直观地展示股票价格随时间的变化趋势,有利于投资者了解价格的波动范围,便于评估市场对新信息的反应速度和效率,同是也是许多技术分析的指标。可以说每个股票数据分析都需要有k线图。
表1. 1 深证指数季度k线图数据类型
深证指数的开盘价需要取数据集的所有股票的开盘价的加权平均值进行计算。在本系统中,权重均选取为该股票当日的总市值。设Popen,i为第i支股票的开盘价,Mi为第i支股票的当日总市值,n是股票总数,可得深证指数的开盘价计算公式。
![]()
最高价、最低价和收盘价的计算与公式1.1类似。
收盘价走势图可以反应市场对股票的总体情绪。如果收盘价持续高于开盘价,可能表明买方控制市场;反之,则可能是卖方控制市场。通过收盘价走势图可以帮助投资者确认合适的止损点和目标价位,并进行评估投资回报。
表1. 2 深证指数季度收盘价走势图数据类型
该图需要的数据类型为k线图数据类型的子集,只需要进行数据筛选就能获得。
成交量柱状图的高度表示在特点时间段内成交的股票数量,可以反映市场供需关系。成交量图还可以反映市场的流通性,高成交量通常意味着市场流动性较好,交易更容易执行。
表1. 3 深证指数季度成交量柱状图数据类型
深证指数的成交量即为所有股票的成交量相加,设Vi为第i支股票的成交量,n为股票总数,可得深证指数的成交量计算公式。
![]()
热力图的纵轴为月份(1-12月),横轴为年份(1999-2016)。热力图通过不同颜色的色块直观展示股票每月的涨跌幅情况,帮助投资者快速把握市场的整体趋势和动态。
表1. 4深证指数每月涨跌幅热力图数据类型
深证指数的每月涨跌幅可以计算当月内每日涨跌幅的平均值来获得。设Pclone,今日为今日的收盘价,Pclone,前日为前一日的收盘价,可得当日涨跌幅计算公式。
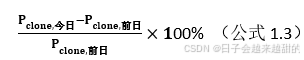
成交量季度占比图可以展示在不同季度内股票交易的活跃程度,帮助投资者理解市场参与度的变化趋势。通过观察成交量的季度变化,投资者可以识别资金流向,判断哪些季度吸引了更多的资金关注和参与。季度占比图提供了一个宏观视角帮助投资者从更宽广的时间框架评估投资机会。
表1. 5 深证指数季度成交量占比饼图数据类型
每季度的总成交量只需要从月中选出季度数据,再将求和即可得出。
1.2 技术选型
数据分析使用Hadoop平台实现。Hadoop的HDFS可以提供数据文件的上传和管理,而MapReduce可以使用java代码简单地编写数据处理逻辑,非常适合初学者学习和开发。
后端使用Spring Boot框架实现。Spring Boot提供了大量的自动配置,可以为开发接口节约时间。同时Spring Boot内嵌有Tomcat容器,十分便于开发测试。
可视化展示使用Vue和Echarts实现。Vue框架十分易于上手,并且生态系统丰富,配合Echarts可以容易地将数据转为图表展示。
2 系统体系结构设计
2.1 系统架构设计
本系统设计了三个层,分别为展示层、控制层和数据层。展示层负责与用户直接交互,展示数据和接收用户上传文件,使用Web应用实现。控制层负责提供接口接收用户上传的文件,并将文件上传至HDFS。待MapReduce将数据处理完毕后,将处理好的文件从HDFS获取,并封装成便于可视化的对象,提供接口给展示层访问。控制层使用Spring Boot实现,并通过Hadoop提供的FileSystem对象实例访问HDFS。数据层负责接收上传的文件、处理分析数据和存储数据,使用Hadoop平台实现,并通过MapReduce编程模型对数据集进行处理。
2.2 系统部署设计
本系统采用前后端分离开发。前端Web应用部署在Nginx代理的服务器上。后端SpringBoot应用部署在Ubuntu系统的服务器上。Hadoop集群采用伪分布式部署在Ubuntu系统的服务器上。前端与后端之间通过HTTP协议进行通信。后端与Hadoop集群通过FileSystem对象实例交互,进行数据的读写操作。
3.1 由多支股票数据计算深证指数的k线数据
输入CSV文件数据字段:日期(dateStr)、开盘价(openPriceStr)、最高价(highPriceStr)、最低价(lowPriceStr)、收盘价(closePriceStr)、总市值(totalMarketCapStr)。
protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split(",");
if (this.isHeader) {
this.isHeader = false;
} else {
if (fields.length >= 21) {
String dateStr = fields[2].trim();
String openPriceStr = fields[4].trim();
String highPriceStr = fields[5].trim();
String lowPriceStr = fields[6].trim();
String closePriceStr = fields[7].trim();
String totalMarketCapStr = fields[16].trim();
try {
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
LocalDate date = LocalDate.parse(dateStr, formatter);
this.outputKey.set(date.toString());
this.outputValue.set(openPriceStr + "," + highPriceStr + "," + lowPriceStr + "," + closePriceStr + "," + totalMarketCapStr);
context.write(this.outputKey, this.outputValue);
} catch (NumberFormatException var14) {
System.out.println("Error parsing number: " + line);
}
}
}
}protected void reduce(Text key, Iterable<Text> values, org.apache.hadoop.mapreduce.Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
double totalOpenPrice = 0.0;
double totalHighPrice = 0.0;
double totalLowPrice = 0.0;
double totalClosePrice = 0.0;
double totalMarketCap = 0.0;
Iterator var = values.iterator();
while(var.hasNext()) {
Text value = (Text)var.next();
String[] parts = value.toString().split(",");
if (parts.length == 5) {
try {
double openPrice = Double.parseDouble(parts[0]);
double highPrice = Double.parseDouble(parts[1]);
double lowPrice = Double.parseDouble(parts[2]);
double closePrice = Double.parseDouble(parts[3]);
double marketCap = Double.parseDouble(parts[4]);
totalOpenPrice += openPrice * marketCap;
totalHighPrice += highPrice * marketCap;
totalLowPrice += lowPrice * marketCap;
totalClosePrice += closePrice * marketCap;
totalMarketCap += marketCap;
} catch (NumberFormatException var27) {
System.err.println("Error parsing number: " + value);
}
} else {
System.err.println("Invalid input format: " + value);
}
}
if (totalMarketCap != 0.0) {
double averageOpenPrice = totalOpenPrice / totalMarketCap;
double averageHighPrice = totalHighPrice / totalMarketCap;
double averageLowPrice = totalLowPrice / totalMarketCap;
double averageClosePrice = totalClosePrice / totalMarketCap;
context.write(key, new Text(String.format("%.2f\t%.2f\t%.2f\t%.2f", averageOpenPrice, averageHighPrice, averageLowPrice, averageClosePrice)));
} else {
System.err.println("Total market cap is zero for key: " + key);
}
}3.2 筛选深证指数季度k线数据
输入CSV文件数据字段:日期(dateStr)、开盘价(openPriceStr)、最高价(highPriceStr)、最低价(lowPriceStr)、收盘价(closePriceStr))。
protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t",2);
if (this.isHeader) {
this.isHeader = false;
} else {
if (fields.length <= 5) {
String dateStr = fields[0].trim();
LocalDate date = LocalDate.parse(dateStr, formatter);
int year = date.getYear();
int month = date.getMonthValue();
int quarter = (month-1) / 3 + 1;
int lastMonthOfQuarter = quarter * 3;
LocalDate quarterEnd = LocalDate.of(year,lastMonthOfQuarter, 1).with(TemporalAdjusters.lastDayOfMonth());
// 检查是否为季度末
if (date.equals(quarterEnd)) {
outputKey.set(quarterEnd.format(formatter));
outputValue.set(fields[1]);
context.write(outputKey, outputValue);
}
}
}
}protected void reduce(Text key, Iterable<Text> values, org.apache.hadoop.mapreduce.Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
List<String> valueList = new ArrayList<>();
for (Text value : values) {
valueList.add(value.toString());
}
if (valueList.size() >= 4) {
StringBuilder result = new StringBuilder();
for (int i = 0; i < 4; i++) {
result.append(valueList.get(i));
result.append("\t");
}
context.write(key, new Text(result.toString().trim()));
} else {
StringBuilder result = new StringBuilder();
for (String value : valueList) {
result.append(value);
result.append("\t");
}
context.write(key, new Text(result.toString().trim()));
}
}3.3 计算深证指数季度每成交总量
输入CSV文件数据字段:日期(dateStr)、开盘价(openPriceStr)、最高价(highPriceStr)、最低价(lowPriceStr)、收盘价(closePriceStr)、总市值(totalMarketCapStr)。
protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split(",");
if (this.isHeader) {
this.isHeader = false;
} else {
if (fields.length >= 21) {
String dateStr = fields[2].trim();
String volumeStr = fields[8].trim();
if (!volumeStr.equalsIgnoreCase("N/A")) {
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
LocalDate date = LocalDate.parse(dateStr, formatter);
int year = date.getYear();
int quarter = date.getMonthValue() / 4 + 1;
String yearQuarter = year + "Q" + quarter;
double volumeDouble = Double.parseDouble(volumeStr);
long volume = Math.round(volumeDouble);
this.outputKey.set(yearQuarter);
this.outputValue.set(volume);
context.write(this.outputKey, this.outputValue);
}
}
}
}protected void reduce(Text key, Iterable<LongWritable> values, org.apache.hadoop.mapreduce.Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long sum = 0L;
LongWritable val;
for(Iterator var6 = values.iterator(); var6.hasNext(); sum += val.get()) {
val = (LongWritable)var6.next();
}
this.result.set(sum);
context.write(key, this.result);
}3.4 计算深证指数月度平均涨跌幅
输入CSV文件数据字段:日期(dateStr)、开盘价(openPriceStr)、收盘价(closePriceStr)。
protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, DoubleWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
if (this.isHeader) {
this.isHeader = false;
} else {
if (fields.length == 5) {
String dateStr = fields[0].trim();
String openPriceStr = fields[1].trim();
String closePriceStr = fields[4].trim();
double openPrice = Double.parseDouble(openPriceStr);
double closePrice = Double.parseDouble(closePriceStr);
double changePercent = (closePrice - openPrice) / openPrice * 100.0;
// 将日期转换为月份
LocalDate date = LocalDate.parse(dateStr, formatter);
String monthStr = date.format(DateTimeFormatter.ofPattern("yyyy-MM"));
this.outputKey.set(monthStr);
this.outputValue.set(changePercent);
context.write(this.outputKey, this.outputValue);
}
}
}protected void reduce(Text key, Iterable<DoubleWritable> values, org.apache.hadoop.mapreduce.Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context) throws IOException, InterruptedException {
List<Double> valueList = new ArrayList<>();
for (DoubleWritable value : values) {
valueList.add(value.get());
}
if (!valueList.isEmpty()) {
double sum = 0.0;
for (double value : valueList) {
sum += value;
}
double averageChangePercent = sum / valueList.size();
context.write(key, new DoubleWritable(averageChangePercent));
}
}4 后端接口设计
后端采用SpringBoot应用,通过调用hadoop相关API对HDFS进行文件上传、文件读取、文件删除操作,通过调用mapreduce接口完成对HDFS中资源文件的处理,并将计算结果上传至HDFS中指定结果文件目录。Mapreduce接口调用和HDFS的相关操作被封装为工具类HdfsUtils,提供了文件上传、文件读取、文件删除、执行mapreduce任务功能接口。
1. package com.bigdata.utils;
2.
3. import org.apache.hadoop.conf.Configuration;
4. import org.apache.hadoop.fs.FSDataOutputStream;
5. import org.apache.hadoop.fs.FileStatus;
6. import org.apache.hadoop.fs.FileSystem;
7. import org.apache.hadoop.fs.Path;
8. import org.apache.hadoop.io.DoubleWritable;
9. import org.apache.hadoop.io.LongWritable;
10. import org.apache.hadoop.io.Text;
11. import org.apache.hadoop.mapreduce.Job;
12. import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
13. import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
14. import org.springframework.web.multipart.MultipartFile;
15.
16. import java.io.*;
17. import java.net.URI;
18. import java.util.ArrayList;
19. import java.util.List;
20. import java.util.Objects;
21.
22. public class HdfsUtils {
23.
24. // hdfs地址
25. public static final String HDFS_PATH = "hdfs://192.168.218.128:9000";
26.
27. // 本地文件夹
28. public static final String LOCAL_DIR = "D:\\bigdata";
29.
30.
31. // 根路径 \\user\\hadoop\\
32. // 元数据文件夹
33. public static final String HDFS_DIR = "/user/hadoop/datasource";
34. // StockKline计算结果文件夹
35. public static final String STOCK_KLINE = "/user/hadoop/output/kline";
36. // StockKlineQ计算结果文件夹
37. public static final String STOCK_KLINE_Q = "/user/hadoop/output/klineQ";
38. // StockChg计算结果文件夹
39. public static final String STOCK_CHG = "/user/hadoop/output/chg";
40. // StockVolume计算结果文件夹
41. public static final String STOCK_VOLUME = "/user/hadoop/output/volume";
42.
43.
44. public static List<String> getStockKlineLines() {
45. return getLines(STOCK_KLINE);
46. }
47. public static List<String> getStockKlineQLines() {
48. return getLines(STOCK_KLINE_Q);
49. }
50. public static List<String> getStockChgLines() {
51. return getLines(STOCK_CHG);
52. }
53. public static List<String> getStockVolumeLines() {
54. return getLines(STOCK_VOLUME);
55. }
56.
57. /**
58. * 获取HDFS_DIR文件夹下的所有文件名称
59. *
60. * @return 文件名称列表
61. */
62. public static List<String> getFileNamesInHdfs() {
63. // 创建配置实例
64. Configuration conf = new Configuration();
65. conf.set("fs.defaultFS", HDFS_PATH); // 指定HDFS地址
66. List<String> fileNames = new ArrayList<>();
67. try (
68. // 获取文件系统实例
69. FileSystem fileSystem = FileSystem.get(new URI(HDFS_PATH), conf, "hadoop")
70. ) {
71. // 获取HDFS_DIR路径
72. Path hdfsDir = new Path(HDFS_DIR);
73. if (fileSystem.exists(hdfsDir)) {
74. // 列出文件夹下的所有文件和子文件夹
75. FileStatus[] fileStatuses = fileSystem.listStatus(hdfsDir);
76. for (FileStatus fileStatus : fileStatuses) {
77. if (fileStatus.isFile()) {
78. // 如果是文件,添加文件名称到列表
79. fileNames.add(fileStatus.getPath().getName());
80. }
81. }
82. } else {
83. System.out.println("HDFS_DIR 路径不存在:" + HDFS_DIR);
84. }
85. } catch (Exception e) {
86. e.printStackTrace();
87. }
88. return fileNames;
89. }
90.
91. public static void deleteFilesInHdfs(List<String> fileNames) {
92. // 创建配置对象
93. Configuration conf = new Configuration();
94. conf.set("fs.defaultFS", HDFS_PATH); // 指定HDFS地址
95. try (
96. FileSystem fs = FileSystem.get(new URI(HDFS_PATH), conf, "hadoop");
97. ) {
98. for (String fileName : fileNames) {
99. // 构建文件路径
100. Path filePath = new Path(HDFS_DIR + "/" + fileName);
101. // 删除文件
102. if (fs.exists(filePath)) {
103. boolean isDeleted = fs.delete(filePath, false); // false表示不递归删除
104. if (isDeleted) {
105. System.out.println("File deleted successfully: " + filePath);
106. } else {
107. System.out.println("Failed to delete file: " + filePath);
108. }
109. } else {
110. System.out.println("File does not exist: " + filePath);
111. }
112. }
113.
114. } catch (Exception e) {
115. e.printStackTrace();
116. }
117. }
118.
119.
120. /**
121. * 执行MapReduce任务
122. * @param conf 配置
123. * @param pattern 计算模式
124. * @param inputPath 输入数据路径
125. * @param outputPath 输出结果路径
126. */
127. private static void runMapReduceJob(Configuration conf,String pattern, String inputPath, String outputPath){
128. int flat = 0;
129. if(pattern.isEmpty()){
130. return;
131. } else if (pattern.equals("StockChg")) {
132. flat = 1;
133. } else if (pattern.equals("StockVolume")) {
134. flat = 2;
135. }else if (pattern.equals("StockKline")) {
136. flat = 3;
137. } else if (pattern.equals("StockKlineQ")) {
138. flat = 4;
139. } else {
140. System.out.println("不存在该MapReduce执行类");
141. return;
142. }
143. try {
144. // 创建Job实例
145. Job job = Job.getInstance(conf, "Stock "+pattern+" Analysis");
146. // 设置jar包路径 这里设置的在org.mapreduce.StockKline可以看到
147. if(flat == 1){
148. job.setJarByClass(com.bigdata.mapreduce.StockChg.StockChg.class);
149. job.setMapperClass(com.bigdata.mapreduce.StockChg.Mapper.class);
150. job.setReducerClass(com.bigdata.mapreduce.StockChg.Reducer.class);
151. // 设置输出键值对类型
152. job.setOutputKeyClass(Text.class);
153. job.setOutputValueClass(DoubleWritable.class);
154. }else if (flat == 2) {
155. job.setJarByClass(com.bigdata.mapreduce.StockVolume.StockVolume.class);
156. job.setMapperClass(com.bigdata.mapreduce.StockVolume.Mapper.class);
157. job.setReducerClass(com.bigdata.mapreduce.StockVolume.Reducer.class);
158. // 设置输出键值对类型
159. job.setOutputKeyClass(Text.class);
160. job.setOutputValueClass(LongWritable.class);
161. } else if (flat == 3) {
162. job.setJarByClass(com.bigdata.mapreduce.StockKline.StockKline.class);
163. job.setMapperClass(com.bigdata.mapreduce.StockKline.Mapper.class);
164. job.setReducerClass(com.bigdata.mapreduce.StockKline.Reducer.class);
165. // 设置输出键值对类型
166. job.setOutputKeyClass(Text.class);
167. job.setOutputValueClass(Text.class);
168. } else {
169. job.setJarByClass(com.bigdata.mapreduce.StockKlineQ.StockKlineQ.class);
170. job.setMapperClass(com.bigdata.mapreduce.StockKlineQ.Mapper.class);
171. job.setReducerClass(com.bigdata.mapreduce.StockKlineQ.Reducer.class);
172. // 设置输出键值对类型
173. job.setOutputKeyClass(Text.class);
174. job.setOutputValueClass(Text.class);
175. }
176.
177.
178. // 设置输入和输出路径
179. FileInputFormat.addInputPath(job, new Path(inputPath));
180. FileOutputFormat.setOutputPath(job, new Path(outputPath));
181.
182. // 删除已存在的输出路径
183. Path outputDir = new Path(outputPath);
184. FileSystem fs = FileSystem.get(conf);
185. if (fs.exists(outputDir)) {
186. fs.delete(outputDir, true);
187. }
188.
189. // fs.mkdirs(outputDir);
190. // 提交Job
191. boolean success = job.waitForCompletion(true);
192. if (success) {
193. System.out.println("MapReduce任务执行成功!文件地址为:"+outputPath+"/part-r-00000");
194. } else {
195. System.out.println("MapReduce任务执行失败!");
196. }
197. } catch (Exception e) {
198. e.printStackTrace();
199. }
200. }
201.
202.
203. /**
204. * 上传文件到HDFS
205. * @param files 文件列表
206. */
207. public static void upload(List<MultipartFile> files) {
208. try {
209. //获取文件系统实例
210. Configuration conf = new Configuration();
211. conf.set("fs.defaultFS", HDFS_PATH);
212. FileSystem fileSystem = FileSystem.get(new URI(HDFS_PATH), conf, "hadoop");
213. //fileSystem.mkdirs(new Path("app_test"));
214. //确保HDFS的目标目录存在
215. Path dstDir = new Path(HDFS_DIR);
216. if (!fileSystem.exists(dstDir)) {
217. fileSystem.mkdirs(dstDir);
218. }
219. //上传文件到HDFS
220. uploadMultipartFiles(fileSystem, files, dstDir);
221.
222. fileSystem.close();
223. } catch (Exception e) {
224. e.printStackTrace();
225. }
226. }
227.
228. /**
229. * 采用mapreduce处理HDFS文件
230. */
231. public static void mapreduce() {
232. try {
233. //获取文件系统实例
234. Configuration conf = new Configuration();
235. conf.set("fs.defaultFS", HDFS_PATH);
236. FileSystem fileSystem = FileSystem.get(new URI(HDFS_PATH), conf, "hadoop");
237. //fileSystem.mkdirs(new Path("app_test"));
238. //确保HDFS的目标目录存在
239. Path dstDir = new Path(HDFS_DIR);
240. if (!fileSystem.exists(dstDir)) {
241. fileSystem.mkdirs(dstDir);
242. }
243.
244. //提交MapReduce任务--确保按顺序执行
245. // 季K线图 StockKline + StockKlineQ,结果位于 STOCK_KLINE_Q
246. runMapReduceJob(conf, "StockKline", HDFS_DIR, STOCK_KLINE);
247. runMapReduceJob(conf, "StockKlineQ", STOCK_KLINE, STOCK_KLINE_Q);
248. // 季收盘价走势,结果即季K线图数据,位于 STOCK_KLINE_Q
249. // 季成交量 StockVolume,结果位于 STOCK_VOLUME
250. runMapReduceJob(conf, "StockVolume", HDFS_DIR, STOCK_VOLUME);
251. // 月涨跌幅 StockKline + StockChg,结果位于 STOCK_CHG
252. runMapReduceJob(conf, "StockChg", STOCK_KLINE, STOCK_CHG);
253. // 成交量季度占比 结果即季度成交量数据,结果位于 STOCK_VOLUME
254.
255. fileSystem.close();
256. } catch (Exception e) {
257. e.printStackTrace();
258. }
259. }
260.
261. public static List<String> getLines(String filePath) {
262. // 创建配置实例
263. Configuration conf = new Configuration();
264. conf.set("fs.defaultFS", HDFS_PATH); // 指定HDFS地址
265. List<String> lines = new ArrayList<>();
266. try (
267. // 获取文件系统实例
268. FileSystem fileSystem = FileSystem.get(new URI(HDFS_PATH), conf, "hadoop");
269. BufferedReader reader = new BufferedReader(new InputStreamReader(fileSystem.open(new Path(filePath + "/part-r-00000"))))
270. ) {
271. String line;
272. while ((line = reader.readLine()) != null) {
273. lines.add(line);
274. }
275. } catch (Exception e) {
276. e.printStackTrace();
277. }
278. return lines;
279. }
280.
281. public static void uploadMultipartFiles(FileSystem fs, List<MultipartFile> files, Path hdfsDir) throws Exception {
282. System.out.println("开始上传文件到HDFS...");
283. if (files == null || files.isEmpty()) {
284. System.out.println("没有文件需要上传!");
285. return;
286. }
287. for (MultipartFile file : files) {
288. if (file.isEmpty()) {
289. System.out.println("文件为空,跳过上传:" + file.getOriginalFilename());
290. continue;
291. }
292. Path destPath = new Path(hdfsDir, Objects.requireNonNull(file.getOriginalFilename()));
293. try (InputStream in = file.getInputStream();
294. FSDataOutputStream out = fs.create(destPath, true)) {
295. byte[] buffer = new byte[1024];
296. int bytesRead;
297. while ((bytesRead = in.read(buffer)) > 0) {
298. out.write(buffer, 0, bytesRead);
299. }
300. System.out.println("文件上传成功!" + file.getOriginalFilename() + "-->" + destPath);
301. }
302. }
303. }304. }
其中mapreduce任务的执行需要遵守相应顺序。
1. //提交MapReduce任务--确保按顺序执行
2. // 季K线图 StockKline + StockKlineQ,结果位于 STOCK_KLINE_Q
3. runMapReduceJob(conf, "StockKline", HDFS_DIR, STOCK_KLINE);
4. runMapReduceJob(conf, "StockKlineQ", STOCK_KLINE, STOCK_KLINE_Q);
5. // 季收盘价走势,结果即季K线图数据,位于 STOCK_KLINE_Q
6. // 季成交量 StockVolume,结果位于 STOCK_VOLUME
7. runMapReduceJob(conf, "StockVolume", HDFS_DIR, STOCK_VOLUME);
8. // 月涨跌幅 StockKline + StockChg,结果位于 STOCK_CHG
9. runMapReduceJob(conf, "StockChg", STOCK_KLINE, STOCK_CHG);
10. // 成交量季度占比 结果即季度成交量数据,结果位于 STOCK_VOLUME
4.1 季k线数据
- 请求方式:GET
- 请求路径:/kline
- 请求参数:无
- 请求示例:http://localhost:8082/kline
- 返回示例:
| { |
- 返回数据结构
| 名称 | 类型 | 必选 | 约束 | 中文名 | 说明 |
| » code | integer | true | none | 状态码 | none |
| » msg | string | true | none | 返回描述 | none |
| » data | [object] | true | none | 返回数据 | none |
| »» quarterEndDate | string | true | none | 季末日期 | none |
| »» openPrice | number | true | none | 开盘价(元) | none |
| »» highestPrice | number | true | none | 最高价(元) | none |
| »» lowestPrice | number | true | none | 最低价(元) | none |
| »» closePrice | number | true | none | 收盘价(元) | none |
4.2 季收盘价走势
- 请求方式:GET
- 请求路径:/close_trend
- 请求参数:无
- 请求示例:http://localhost:8082/close_trend
- 返回示例:
| { |
- 返回数据结构
| 名称 | 类型 | 必选 | 约束 | 中文名 | 说明 |
| » code | integer | true | none | 状态码 | none |
| » msg | string | true | none | 返回描述 | none |
| » data | [object] | true | none | 返回数据 | none |
| »» quarterEndDate | string | true | none | 季末日期 | none |
| »» closePrice | number | true | none | 收盘价(元) | none |
4.3 季成交量
- 请求方式:GET
- 请求路径:/volume
- 请求参数:无
- 请求示例:http://localhost:8082/volume
- 返回示例:
| { }, }, |
- 返回数据结构
| 名称 | 类型 | 必选 | 约束 | 中文名 | 说明 |
| » code | integer | true | none | 状态码 | none |
| » msg | string | true | none | 返回描述 | none |
| » data | [object] | true | none | 返回数据 | none |
| »» year | string | true | none | 年 | none |
| »» quarter | string | true | none | 季度 | none |
| »» yearAndQuarter | string | true | none | 年和季度 | none |
| »» volume | number | true | none | 成交量(股) | none |
4.4 月涨跌幅
- 请求方式:GET
- 请求路径:/chg
- 请求参数:无
- 请求示例:http://localhost:8082/chg
- 返回示例:
| { |
- 返回数据结构
| 名称 | 类型 | 必选 | 约束 | 中文名 | 说明 |
| » code | integer | true | none | 状态码 | none |
| » msg | string | true | none | 返回描述 | none |
| » data | [object] | true | none | 返回数据 | none |
| »» year | string | true | none | 年 | none |
| »» month | string | true | none | 月 | none |
| »» chg | number | true | none | 涨跌幅(小数) | none |
4.5 某年季成交量占比
- 请求方式:GET
- 请求路径:/volume_in_year
- 请求参数:Params
| 名称 | 位置 | 类型 | 必选 | 说明 |
| year | query | string | 是 | 年份 |
- 请求示例:http://localhost:8082/volume_in_year?year=2012
- 返回示例:
| { |
- 返回数据结构
| 名称 | 类型 | 必选 | 约束 | 中文名 | 说明 |
| » code | integer | true | none | 状态码 | none |
| » msg | string | true | none | 返回描述 | none |
| » data | [object] | true | none | 返回数据 | none |
| »» year | string | true | none | 年 | none |
| »» quarter | string | true | none | 月 | none |
| »» yearAndQuarter | string | true | none | 年和月 | none |
| »» volume | number | true | none | 成交量(股) | none |
4.6 上传文件
- 请求方式:POST
- 请求路径:/upload
- 请求参数:form-data
| 名称 | 位置 | 类型 | 必选 | 说明 |
| » files | body | string(binary) | 是 | File文件 |
- 请求示例:http://localhost:8082/upload
- 返回示例:
| { |
- 返回数据结构
| 名称 | 类型 | 必选 | 约束 | 中文名 | 说明 |
| » code | integer | true | none | 状态码 | none |
| » msg | string | true | none | 返回描述 | none |
| » data | null | true | none | 返回结果 | 成功时返回null |
4.7 删除文件
- 请求方式:DELETE
- 请求路径:/delete
- 请求参数:application/json
| 名称 | 位置 | 类型 | 必选 | 说明 |
| - | body | array[string] | 是 | 文件名称列表 |
- 请求示例:http://localhost:8082/delete
| [ |
- 返回示例:
| { |
- 返回数据结构
| 名称 | 类型 | 必选 | 约束 | 中文名 | 说明 |
| » code | integer | true | none | 状态码 | none |
| » msg | string | true | none | 返回描述 | none |
| » data | null | true | none | 返回结果 | 成功时返回null |
4.8 查看文件
- 请求方式:GET
- 请求路径:/file_names
- 请求参数:无
- 请求示例:http://localhost:8082/file_names
- 返回示例:
| { |
- 返回数据结构
| 名称 | 类型 | 必选 | 约束 | 中文名 | 说明 |
| » code | integer | true | none | 状态码 | none |
| » msg | string | true | none | 返回描述 | none |
| » data | object | true | none | 返回数据 | none |
| »» total | integer | true | none | 文件总数 | none |
| »» names | [string] | true | none | 文件名称列表 | none |
5 可视化图表设计
5.1 季k线图
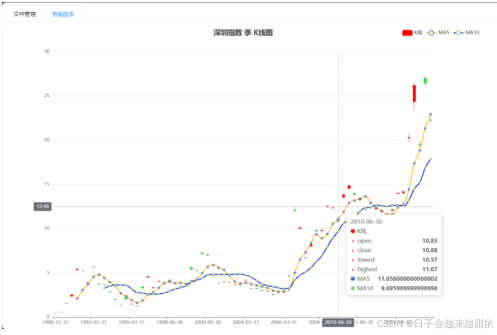
日期(date):每个交易日的日期,格式通常为YYYY-MM-DD。
开盘价(open):每个交易日的开盘价,精度通常为小数点后两位,单位为人民币 元。
最高价(highest):每个交易日的最高价,精度为小数点后两位,单位为人民币元。
最低价(lowest):每个交易日的最低价,精度为小数点后两位,单位为人民币元。
收盘价(close):每个交易日的收盘价,精度为小数点后两位,单位为人民币元。
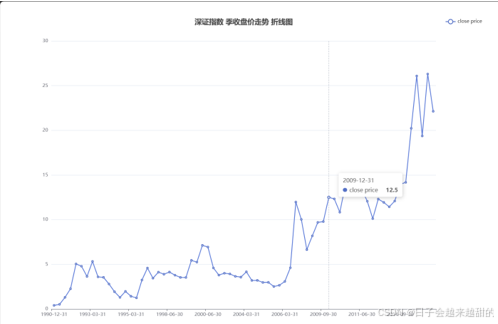
日期(date):每个交易日的日期,格式通常为YYYY-MM-DD。
收盘价(close price):每个交易日的收盘价,精度为小数点后一位,单位为人民·币元。
5.3 季成交量柱状图
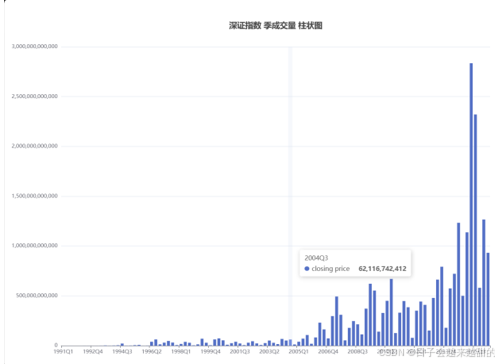
日期(yearAndQuarter):每个交易日的日期,这是柱状图的横轴数据,用于标识每个柱子对应的年份和季度。
成交量(closing price):每个交易日的成交量数据,这是柱状图的纵轴数据,用于展示每个月份的成交量大小。
5.4 月涨跌幅热力图
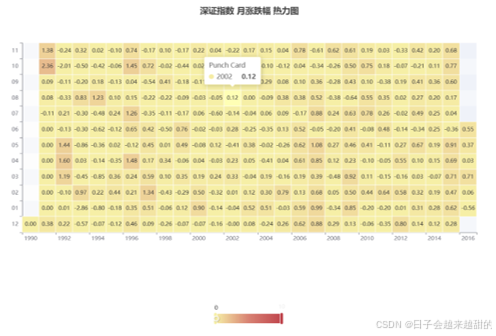
年份(years):每个交易日的年份,这是热力图的横轴数据。
月份(months):每个交易日的月份,这是热力图的纵轴数据。
涨跌幅(data):与上个月收盘价的涨跌对比,这是热力图的表格中的数据。
5.5 成交量季度占比饼图
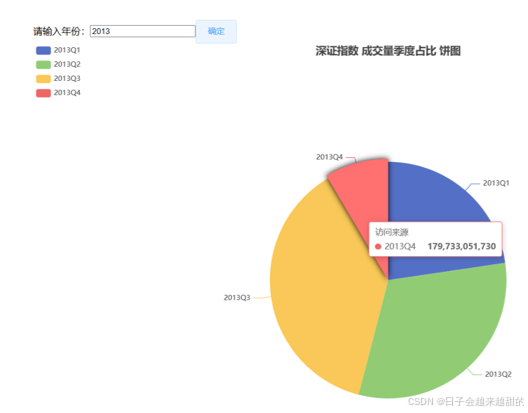
日期(yearAndQuarter):饼图中表示年份和季度的数据
6 软件测试
启动hadoop服务
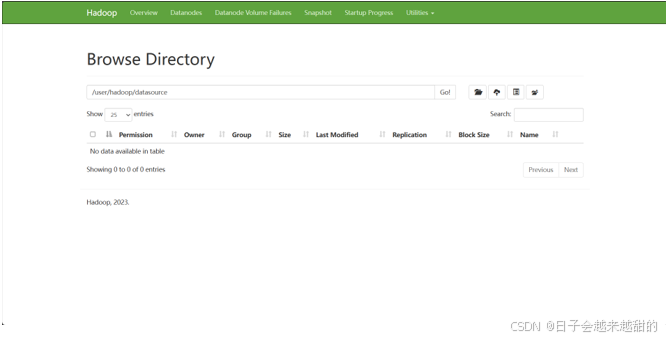
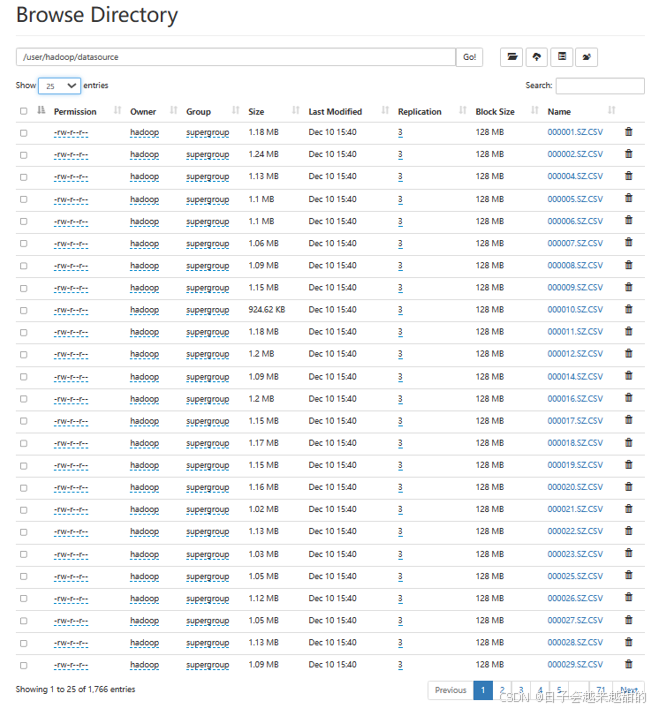
资源文件目录为HDFS中的/user/hadoop/datasource,当前为空
启动前后端服务
上传所有资源文件
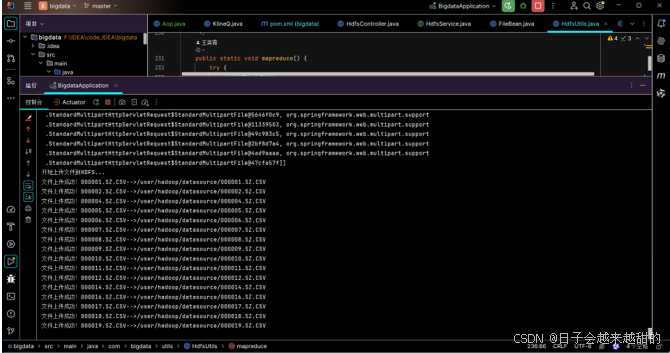
后端接收文件并上传到HDFS,控制台提示信息
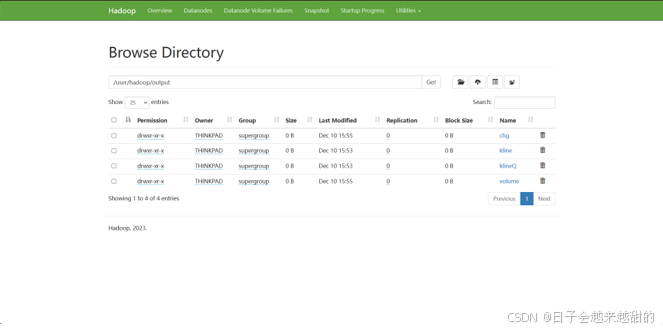
上传文件到HDFS后,自动执行mapreduce任务,后端控制台提示信息如图,计算结果分类输出到HDFS的/user/hadoop/output文件夹下
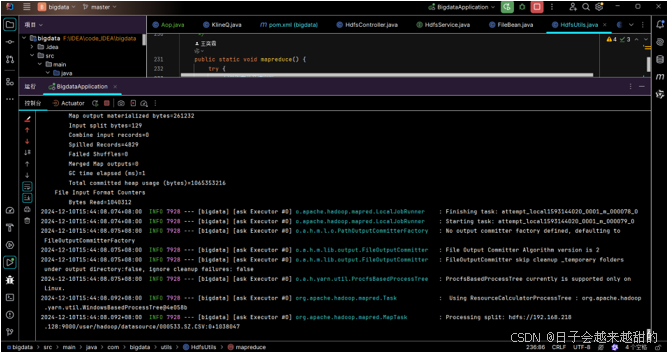
计算结束后,控制台打印本次处理总时长为431.542秒,约7分钟
![]()
前端查看当前HDFS中的文件
当前HDFS中资源目录如图
前端查看相关图表,季K线图如图6.11,季收盘价走势折线图如图6.12,季成交量柱状图如图6.13,月涨跌幅热力图如图6.14,成交量季度占比饼状图如图6.15、图6.16。其中成交量季度占比饼状图需要输入指定年份,查看该年中成交量的季度占比。
7 总结
在本项目的实施过程中,我们成功构建了一个基于Hadoop和Spring Boot的深证A股个股日线数据分析Web系统,该系统不仅实现了对股票数据的保存、整理、分析和总结,还通过网站进行了数据的可视化展示。系统的设计和实现让我们深刻理解了大数据处理的整个流程,从数据收集到存储、处理,再到最终的可视化展示。技术层面上,Hadoop平台的使用让我们能够有效处理大规模数据集,而Spring Boot框架则简化了后端接口的开发和测试工作。前端方面,Vue.js框架和Echarts库的运用极大地提升了数据展示的动态性和图表的交互性。系统功能方面,我们实现了多种数据可视化图表,包括季K线图、季收盘价走势图、季成交量柱状图、月涨跌幅热力图和成交量季度占比饼图等,为用户提供了直观的数据展示。同时,系统还能够通过MapReduce程序计算出深证指数的关键指标,如K线数据、季度K线数据、季度成交量和月度平均涨跌幅等。在文件操作方面,系统支持文件的上传、删除和查看,使用户能够方便地管理HDFS中的资源文件。尽管MapReduce提供了强大的数据处理能力,但在处理速度上还有提升空间,本次单机处理总时长约为7分钟,未来我们可以考虑优化算法或使用更高效的数据处理框架。展望未来,我们计划进一步优化系统性能,扩展功能,并提升用户体验。这包括探索更高效的数据处理算法,减少数据处理时间,提高系统响应速度;增加更多的数据分析和预测功能,为用户提供更全面的市场分析工具;以及进一步优化前端界面,提供更加友好和直观的用户交互体验。总体而言,本项目为投资者和分析师提供了一个有力的工具,我们将继续努力,使其更加完善。


















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









