






▼最近直播超级多,预约保你有收获
今晚直播:《动手做出一个ChatGPT》
—1—
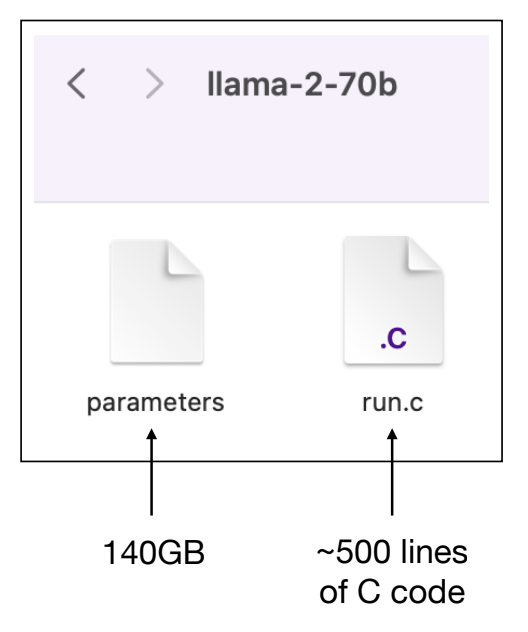
大模型的两个重要文件
大模型,是由海量的数据经过复杂训练而生成的模型,它们能够理解、记忆、生成人类的语言。
我们将大模型进行拆解,进行形象的比喻,那么大模型本质上由两个核心组件构成:一个巨大的参数文件和一个运行这些参数的代码文件。
第一、参数文件,可以视为这些大模型的“DNA”,它包含了千亿级的权重,这些权重值是通过大量数据训练而来的,它们共同构成了一个复杂的人工神经网络。这个网络能够捕捉、学习并模仿人类语言的细微差别,从而理解和生成文本。每一个权重都承载着特定的信息和规则,使得大模型能够在给定输入时做出预测。
第二、代码文件,可以视为这些大模型的“大脑”。这部分代码负责指导如何使用参数文件中的权重来处理输入的文本,执行推理,并产生输出。这些代码可以用各种编程语言编写,它们定义了大模型的架构、如何在给定的输入下选择最合适的词汇以及如何结合上下文生成连贯的文本等。
这两个组件的结合,让大模型具备了令人惊叹的推理能力。我们就能与之交互,无论是撰写文章、编写程序代码,还是解答复杂问题,大模型都能提供卓越的表现。
—2—
大模型的推理
大模型的工作原理是基于一个核心任务:依靠包含压缩数据的神经网络对所给序列中的下一个单词进行预测。
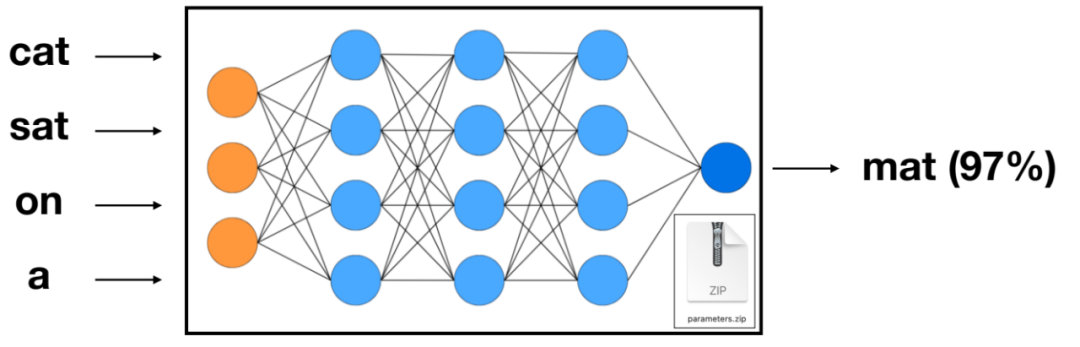
当我们输入一个句子片段,如“cat sat on a”,大模型会动用其内部的千亿级参数通过神经元的相互连接,探索这些词汇之间的潜在联系。每个神经元的连接都代表了特定的语言模式或知识片段,大模型便沿着这些连接寻找最可能的下一个词汇,然后给词库中的每一个词一个概率,概率最高的就是下一个最合适的词汇,比如“mat(97%),就形成了“猫坐在垫子上(cat sat on a mat)”的完整句子。
大模型的神经网络就是在预测下一个单词的概率。
而我们在将海量数据浓缩成模型可学习的参数中,不可避免地会丢失一部分信息。此外,并非所有可能遇到的问题都直接出现在训练数据中,导致即便是最先进的大模型也无法保证其输出结果具有100%的准确性,这就是不可避免的幻觉问题。
—3—
纯干货大模型实战直播
为了帮助同学们掌握好大模型技术架构和微调一个大模型,今晚20点,我会开一场直播和同学们深度聊聊:
第一、GPT-1/2/3核心技术演进剖析
第二、带你动手离线预训练一个 GPT 大模型
第三、ChatGPT 核心技术演进剖析
第四、带你动手离线微调一个 ChatGPT 大模型
请同学点击下方按钮预约直播,咱们今晚20点不见不散哦~~
—4—
免费领取《AI 大模型技术系列直播》
我们梳理了下 AI 大模型的知识图谱,包括12项核心技能:大模型内核架构、大模型开发 API、开发框架、向量数据库、AI 编程、AI Agent、缓存、算力、RAG、大模型微调、大模型预训练、LLMOps 等。
为了帮助同学们掌握 AI 大模型开发技能,我们准备了一系列免费直播干货,扫码全部领取!

参考:https://mp.weixin.qq.com/s/VUxmkXlJxiYCu9YB1A_WLw
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









