







记一次跑批优化
目录
- 工作背景;
- 报表层表依赖关系梳理;
- 调度系统跑批模拟器;
- 理论上的最短耗时;
- echarts输出时序图;
1. 工作背景
因今年的项目需将原有报表工具上的一些报表迁移至新的报表平台,因此涉及到这些报表的取数脚本梳理。厂商在梳理过程中发现一张报表取数时,会涉及到多个中间表,且中间表也是经过层层加工出来,梳理工作进展缓慢。
因此考虑在厂商继续梳理的同时,我这边也研究下如何快速提取表之间的依赖关系。进而在与负责调度系统的同事沟通过程中,发现一些无效的作业依赖关系,并因此想到能否通过删除无效依赖关系,调整作业编号,从而缩短报表跑批耗时。随之便有了接下来的表依赖关系提取、调度跑批模拟器、深度优先遍历、echarts绘制调度时序图等工作。
2. 报表层表依赖关系梳理
基本概念
- 跑批调度系统里有多个跑批任务,本次仅针对报表层任务;
- 每个任务里包含多个作业;
- 每个作业有一个作业编号(命名为“作业类型_编号”,形如XXXX_0012);
- 作业的内容就是通过sh去调用一段perl脚本,脚本里包含sql语句,去执行数据跑批。
表间依赖关系整理
需梳理的目标脚本,为报表层脚本文件夹里的约560个perl脚本。perl文件的文件名即为目标表名,perl文件里的sql语句中的以IALDB、IBLDB、ICLDB、IDLDB、IELDB这五种库实例名开头的表,即为目标表依赖的表名。
存在问题:有些表没有写库实例名称,或者是库实例名称后边有空格的,这部分数量不多,后期手工梳理。 最终输出表间依赖关系2243条。
调度系统作业依赖关系导出
调度系统里的作业信息,以及作业依赖关系直接从数据库里导出。导出的数据进过汇总排序,按被依赖的数量做降序,Top10的截图如下:
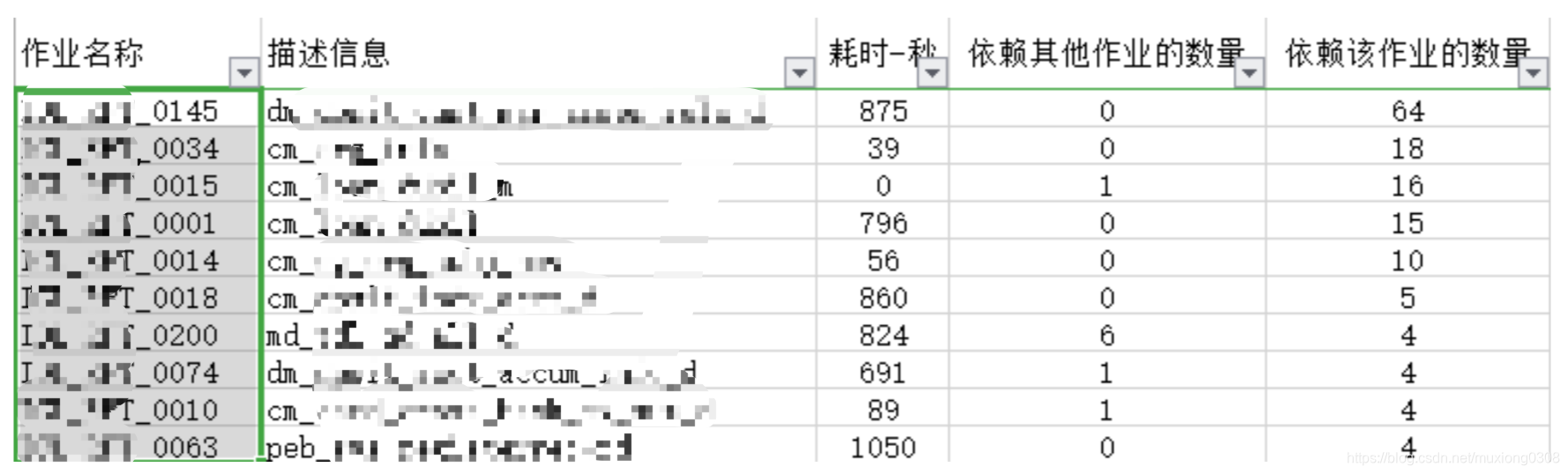
其中XXXX_0145号作业被依赖达64条。
无效依赖关系筛查
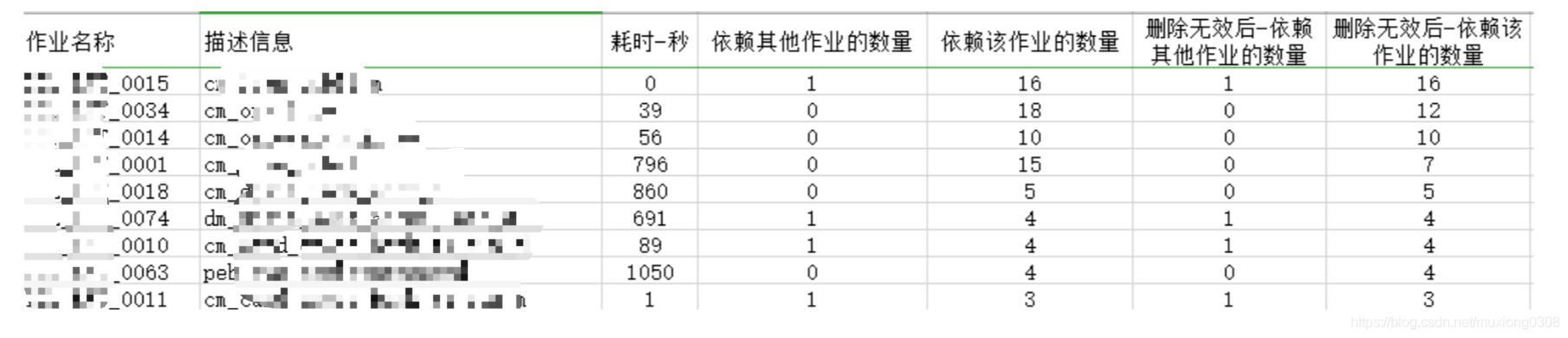
作业的依赖关系,比如A作业依赖于B作业,即为A的perl脚本依赖于B的perl脚本,即为A表需要用到B表的数据。但根据之前梳理出的表间关系做初筛,并结合以下ssh语句做复核,发现有92条作业依赖关系是无效的。以XXXX_0145为例,实际就1个作业依赖于0145,而非64个。
# ssh下查找包含某表名的pl文件
find 某路径下 -name "*.pl" | xargs grep -i "某tablename "
剔除了无效依赖关系后,按被依赖的数量做降序,Top10的截图如下:
依赖关系可视化呈现
删除无效依赖,可降低跑批任务的维护难度,在neo4j上做关系图可视化如下: 删除无效依赖前:262条关系

删除无效依赖后:170条关系,干净了不少。

3. 调度系统跑批模拟器
由于剔除了许多条依赖关系,不知该任务的跑批耗时是否有缩短,又不好在生产环境上进行验证,于是考虑在本地搞一个跑批的模拟器。
经与负责跑批调度系统的同事了解,调度系统的跑批规则如下:
- 20个线程同时跑;
- 按照作业编号order by的顺序取作业;
- 若取到的作业有依赖于其他作业,且其他作业尚未完成,则先跳过。
用python实现,设计如下:
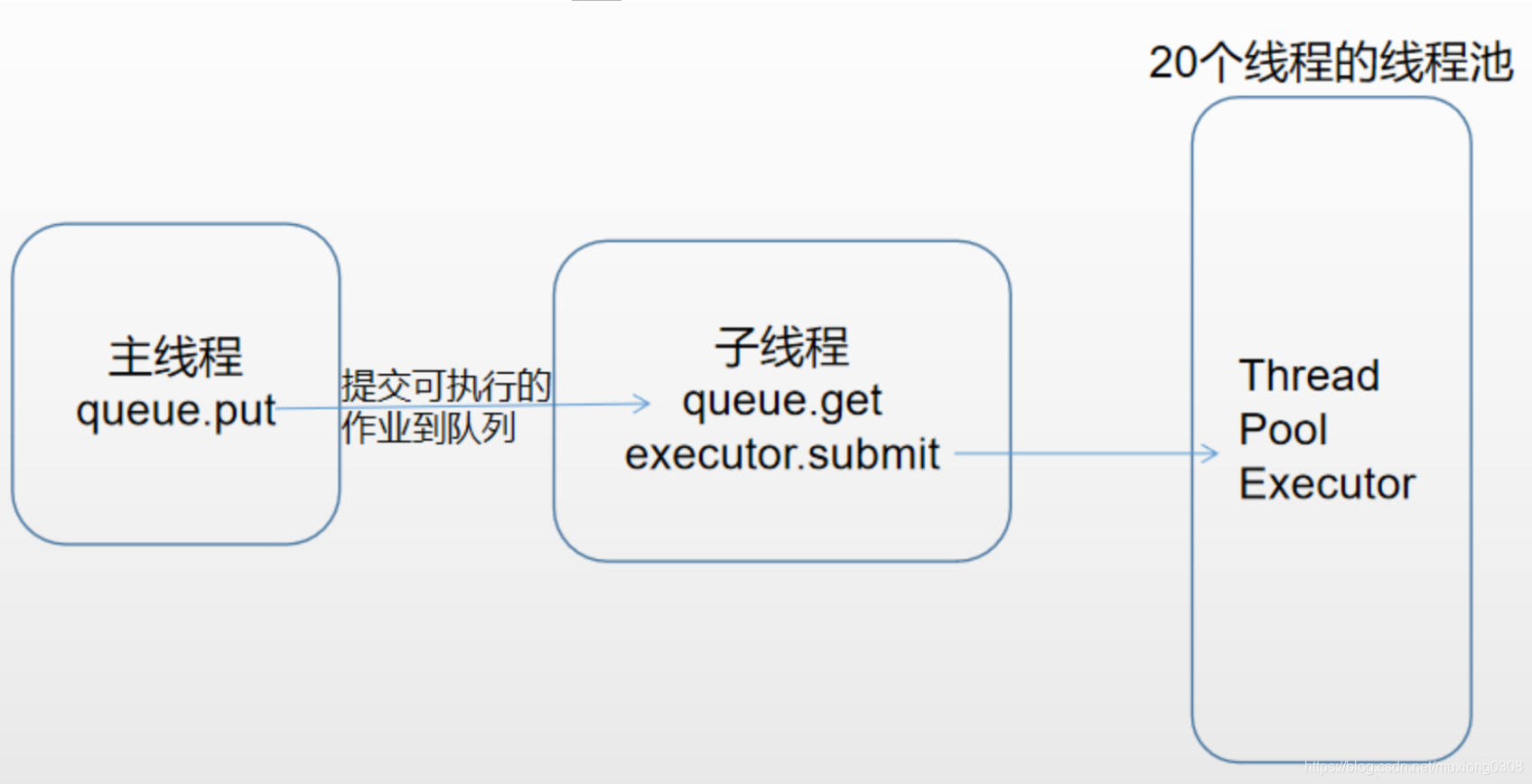
代码如下:
# 数仓调度跑批模拟器
# %% import、文件路径
from concurrent.futures import ThreadPoolExecutor
import threading
import time
import datetime
import pandas as pd
import queue
import os
import webbrowser
from mylog import logc, dataf
jobInfo_filepath = u'./jobSrc/jobInfo_new.csv'
depInfo_filepath = u'./jobSrc/depInfo_new.csv'
dicjob = {
}
executor = None
# 时间比例,缩小timescale倍
timescale = 100.0
dataf_template = "{
{value:[{0},{1},{2},{3},types[{4}].name],itemStyle:{
{normal:{
{color:types[{5}].color}}}}}},"
# 显示x-range图开关
IS_OPEN_ECHARTS = True
# %%
###############
# timescale=100
###############
# 调试数据:20190908的调度数据---92min
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 17:21:07,292 - console[line:243] - INFO: used 65.566222s
# 修改24个作业编号后,用时:
# 2019-09-24 18:24:18,931 - console[line:251] - INFO: used 47.367517s
# 调试数据:20190913的调度数据---98m12s
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 17:23:12,103 - console[line:243] - INFO: used 68.279253s
# 修改24个作业编号后,用时:
# 2019-09-24 18:26:02,326 - console[line:253] - INFO: used 54.73252s
# 调试数据:20190922的调度数据---101m45s
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 17:24:56,260 - console[line:243] - INFO: used 68.034214s、
# 修改24个作业编号后,用时:
# 2019-09-24 18:27:53,594 - console[line:254] - INFO: used 54.080691s
# 2019-09-24 18:29:38,886 - console[line:255] - INFO: used 54.150868s
###############
# timescale=10
###############
# 调试数据:20190908的调度数据---92min
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 17:39:05,565 - console[line:235] - INFO: used 654.113571s
# 修改24个作业编号后,用时:
# 调试数据:20190913的调度数据---98m12s
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 17:51:41,276 - console[line:244] - INFO: used 685.985023s
# 修改24个作业编号后,用时:
# 调试数据:20190922的调度数据---101m45s
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 18:18:14,520 - console[line:246] - INFO: used 678.700894s
# 修改24个作业编号后,用时:
# %% 定义作业类
class BatJob(object):
def __init__(self, name, time, typeindex):
# 作业名称
self.__name = name
# 作业耗时
self.__time = time
# 作业依赖(list)
self.__deps = []
# 作业状态 S_WAIT,S_RUN,S_FINISH
self.__status = 'S_WAIT'
# 作业类别
# { name: '无父类有子类(起始节点)', color: '#75d874', typeindex:0 },
# { name: '无父类无子类(单节点)', color: '#7b9ce1', typeindex:1 },
# { name: '有父类无子类(末端节点)', color: '#000000', typeindex:2 },
# { name: '有父类有子类(中间节点)', color: '#bd6d6c', typeindex:3 }
self.__typeindex = typeindex
def addDep(self, dep):
self.__deps.append(dep)
def goPut(self):
self.__status = 'S_PUT'
def goRun(self):
self.__status = 'S_RUN'
# 作业完成时,修改状态
def goDone(self):
self.__status = 'S_FINISH'
def __str__(self):
return "\n".join(item for item in (
'【name】' + self.__name,
'【time】' + str(self.__time),
'【status】' + str(self.__status),
'【deps】' + str(self.__deps),
'【typeindex】' + str(self.__typeindex)
))
def getDeps(self):
return self.__deps
def getStatus(self):
return self.__status
def getTime(self):
return self.__time/timescale
def getTypeindex(self):
return self.__typeindex
# %% 导入作业信息、依赖信息
def loadInfo():
jobInfo = pd.read_csv(jobInfo_filepath)
depInfo = pd.read_csv(depInfo_filepath)
dic = {
}
jobnameList = []
for i in range(len(jobInfo)):
jobname = jobInfo.jobname[i]
jobtime = 1 if jobInfo.jobtime_s[i] == 0 else jobInfo.jobtime_s[i]
typeindex = jobInfo.typeindex[i]
dic[jobname] = BatJob 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4550
4550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











