一,Java基础
1.Java跨平台的原理
(1)java是将文件(.java)编译成字节码文件(.class),然后字节码在java虚拟机上解释成机器码
(2)字节码(.class)文件不面向任何具体平台,只面向虚拟机
(3)不同平台的虚拟机不同,但有相同的接口
(4)java语言是将文件一次编译,到处运行(只要运行的那个平台装了java虚拟机)

2.面向对象的三大特征
继承:继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或类从父 类继承方法,使得子类具有父类相同的行为。
特点:
继承鼓励类的重用
继承可以多层继承
一个类只能继承一个父类
父类中private修饰的不能被继承
构造方法不能被继承
封装:我 们编写一个类就是对数据和数据操作的封装。可以说,封装就是隐藏一切可隐藏的东西,只向外界提供最简单的编程 接口。
特点:
- 只能通过规定方法访问数据
- 隐藏类数实现细节
- 方便修改实现
- 方便加入控制语句
多态: 父类引用,子类对象,同一种事物,由于条件不同,产生的结果也不同
多态:同一个引用类型,使用不同的实例而执行不同操作
实现多态的三个必要条件
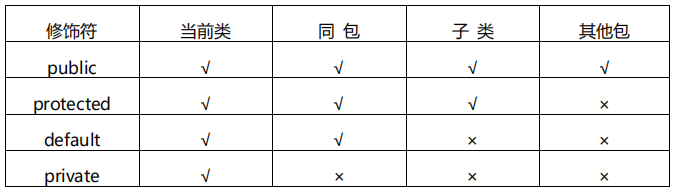
3.访问权限修饰符 public、private、protected, 以及不写(默认)时的区别
4. & 和 && 的区别
&&的短路功能,当第一个表达式的值为false的时候,则不再计算第二个表达式;否则两个表达式都执行。
&可以用作位运算符,当&两边的表达式不是Boolean类型的时候,&表示按位操作
&运算符有两种用法:(1)按位与;(2)逻辑与。
&&运算符是短路与运算。逻辑与跟短路与的差别是非常巨大的,虽然二者都要求运算符左右两端的布尔值都是
true 整个表达式的值才是 true。
&&之所以称为短路运算是因为,如果&&左边的表达式的值是 false,右边的表达式会被直接短路掉,不会进行
运算。很多时候我们可能都需要用&&而不是&,例如在验证用户登录时判定用户名不是 null 而且不是空字符串,应
当写为 username != null &&!username.equals(""),二者的顺序不能交换,更不能用&运算符,因为第一个条件如
果不成立,根本不能进行字符串的 equals 比较,否则会产生 NullPointerException 异常。注意:逻辑或运算符(|)
和短路或运算符(||)的差别也是如此。
1.==:如果比较的对象是基本数据类型,则比较的是数值是否相等;如果比较的是引用数据类型,则比较的是对象
的地址值是否相等
用(==)进行比较的时候,比较的是他们在内存中的存放地址,所以,除非是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false。对象是放在堆中的,栈中存放的是对象的引用(地址)。由此可见'=='是对栈中的值进行比较的。如果要比较堆中对象的内容是否相同,那么就要重写equals方法了。
2.equals()的作用是
用来比较方法两个对象的内容是否相等
equals重新需要注意五点:
- 自反性:对任意引用值X,x.equals(x)的返回值一定为true.
- 对称性:对于任何引用值x,y,当且仅当y.equals(x)返回值为true时,x.equals(y)的返回值一定为true;
- 传递性:如果x.equals(y)=true, y.equals(z)=true,则x.equals(z)=true
- 一致性:如果参与比较的对象没任何改变,则对象比较的结果也不应该有任何改变
- 非空性:任何非空的引用值X,x.equals(null)的返回值一定为false
3.
hashcode
1.如果两个对象相同,那么它们的hashCode值一定要相同;
2.如果两个对象的hashCode相同,它们并不一定相同(这里说的对象相同指的是用eqauls方法比较)。
如不按要求去做了,会发现相同的对象可以出现在Set集合中,同时,增加新元素的效率会大大下降。
3.equals()相等的两个对象,hashcode()一定相等;equals()不相等的两个对象,却并不能证明他们的hashcode()不相等。
6.重载(overload)和重写(override)的区别
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态
性。重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为
重载;重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的返回类型,比父类被重写方
法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。重载对返回类型没有特殊的要求。
方法重载的规则:
1.方法名一致,参数列表中参数的顺序,类型,个数不同。
2.重载与方法的返回值无关,存在于父类和子类,同类中。
3.可以抛出不同的异常,可以有不同修饰符
方法重写的规则:
1.参数列表必须完全与被重写方法的一致,返回类型必须完全与被重写方法的返回类型一致。
2.构造方法不能被重写,声明为 final 的方法不能被重写,声明为 static 的方法不能被重写,但是能够被再次
声明。
3.访问权限不能比父类中被重写的方法的访问权限更低。
4.重写的方法能够抛出任何非强制异常(UncheckedException,也叫非运行时异常),无论被重写的方法是
否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则
可以。
7.抽象类(abstract class)和接口(interface)有什么异同
不同:
抽象类:
1.抽象类中可以定义构造器
2.可以有抽象方法和具体方法
3.接口中的成员全都是 public 的
4.抽象类中可以定义成员变量
5.有抽象方法的类必须被声明为抽象类,而抽象类未必要有抽象方法
6.抽象类中可以包含静态方法
7.一个类只能继承一个抽象类
接口:
1.接口中不能定义构造器
2.方法全部都是抽象方法
3.抽象类中的成员可以是 private、默认、protected、public
4.接口中定义的成员变量实际上都是常量
5.接口中不能有静态方法
6.一个类可以实现多个接口
相同:
1.不能够实例化
2.可以将抽象类和接口类型作为引用类型
3.一个类如果继承了某个抽象类或者实现了某个接口都需要对其中的抽象方法全部进行实现,否则该类仍然需要
被声明为抽象类
8.述静态变量和实例变量的区别
静态变量:是被static修饰的变量,也成为类变量,他属于类,不属于类的任何一个对象
实例变量:必须依存于某一实例,需要先创建对象然后通过对象访问他
9.Java 中异常分为哪些种类
总体上我们根据Java对异常的处理要求,将异常类分为2类。
非检查异常(unckecked exception):Error 和 RuntimeException 以及他们的子类。javac在编译时,不会提示和发现这样的异常,不要求在程序处理这些异常。所以如果愿意,我们可以编写代码处理(使用try...catch...finally)这样的异常,也可以不处理。对于这些异常,我们应该修正代码,而不是去通过异常处理器处理 。这样的异常发生的原因多半是代码写的有问题。如除0错误ArithmeticException,错误的强制类型转换错误ClassCastException,数组索引越界ArrayIndexOutOfBoundsException,使用了空对象NullPointerException等等。
检查异常(checked exception):除了Error 和 RuntimeException的其它异常。javac强制要求程序员为这样的异常做预备处理工作(使用try...catch...finally或者throws)。在方法中要么用try-catch语句捕获它并处理,要么用throws子句声明抛出它,否则编译不会通过。这样的异常一般是由程序的运行环境导致的。因为程序可能被运行在各种未知的环境下,而程序员无法干预用户如何使用他编写的程序,于是程序员就应该为这样的异常时刻准备着。如SQLException , IOException,ClassNotFoundException 等。
error 和 exception 的区别?
Error 类和 Exception 类的父类都是 Throwable 类,他们的区别如下。
Error 类
一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢出等。对于这类
错误的导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止。
Exception 类表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复
运行,而不应该随意终止异常。
Exception 类
又分为运行时异常(Runtime Exception)和受检查的异常(Checked Exception ),运行时异
常;ArithmaticException,IllegalArgumentException,编译能通过,但是一运行就终止了,程序不会处理运行时异常,
出现这类异常,程序会终止。而受检查的异常,要么用 try....catch 捕获,要么用 throws 字句声明抛出,交给它
的父类处理,否则编译不会通过。
10.throw 和 throws 的区别
throw:
1)throw 语句用在方法体内,表示抛出异常,由方法体内的语句处理。
2)throw 是具体向外抛出异常的动作,所以它抛出的是一个异常实例,执行 throw 一定是抛出了某种异常。
throws
:
1)throws 语句是用在方法声明后面,表示如果抛出异常,由该方法的调用者来进行异常的处理。
2)throws 主要是声明这个方法会抛出某种类型的异常,让它的使用者要知道需要捕获的异常的类型。
3)throws 表示出现异常的一种可能性,并不一定会发生这种异常。
11.String 、StringBuilder 、StringBuffer 的区别?
1.
String 是只读字符串,也就意味着 String 引用的字符串内容是不能被改变的。
2.StringBuffer/StringBuilder 表示的字符串对象可以直接进行修改
StringBuilder 是
Java5 中引入的,它和 StringBuffer 的方法完全相同,区别在于它是
在单线程环境下使用的
, 因为它的所有方 法都没有被 synchronized 修饰,因此它的
效率理论上也比 StringBuffer 要高
。
StringBuffer 是线程安全的,而 StringBuilder 不是线程安全的。因此,StringBuilder 的效率会更高。
这三个类的主要区别在于运行速度和线程安全
运行速度 :StringBuilder > StringBuffer > String StringBuilder运行时最快的
String最慢的原因:String为字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对 象是不可更改的,但后两者的对象是变量,是可以更改的
线程安全:StringBuilder是线程不安全的,而StringBuffer是线程安全的
String:适用于少量的字符串操作的情况
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
共同:
StringBuilder 与 StringBuffer 有公共父类 AbstractStringBuilder(抽象类)。
12.如何格式化日期?
SimpleDateFormat formatter = new SimpleDateFormat("yyyy/MM/dd");
Date date1 = new Date();
System.out.println(oldFormatter.format(date1));
13.Java 中有几种类型的流?
按照流的方向:
输入流(inputStream)和输出流(outputStream)。
按照实现功能分:
节点流(可以从或向一个特定的地方(节点)读写数据。如 FileReader)和处理流(是对一个
已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如 BufferedReader。处理流的构造方法总是要
带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。)
按照处理数据的单位:
字节流和字符流。字节流继承于 InputStream 和 OutputStream,字符流继承于
InputStreamReader 和 OutputStreamWriter。


二,Java集合
1.请问 ArrayList、HashSet、HashMap 是线程安全的吗?如果不是我想要线程安全的集合怎么办?
每个方法都没有加锁,显然都是线程不安全的。在集合中 Vector 和 HashTable 倒是线程安全的
Collections 工具类提供了相关的 API,可以让上面那 3 个不安全的集合变为安全的。
1. Collections.synchronizedCollection(c)
2. Collections.synchronizedList(list)
3. Collections.synchronizedMap(m)
4. Collections.synchronizedSet(s)
2.ArrayList 内部用什么实现的?
ArrayList 内部是用 Object[]实现的。
一、构造函数
1)空参构造
array 是一个 Object[]类型。当我们 new 一个空参构造时系统调用了 EmptyArray.OBJECT 属性,EmptyArray 仅
仅是一个系统的类库,该类源码如下:
/**
* Constructs a new {@code ArrayList} instance with zero initial capacity.
*/
public ArrayList() {
array = EmptyArray.OBJECT;
}
public final class EmptyArray {
private EmptyArray() {}
public static final boolean[] BOOLEAN = new boolean[0];
public static final byte[] BYTE = new byte[0];
public static final char[] CHAR = new char[0];
public static final double[] DOUBLE = new double[0];
public static final int[] INT = new int[0];
public static final Class<?>[] CLASS = new Class[0];
public static final Object[] OBJECT = new Object[0];
public static final String[] STRING = new String[0];
public static final Throwable[] THROWABLE = new Throwable[0];
public static final StackTraceElement[] STACK_TRACE_ELEMENT = new StackTraceElement[0];
}
也就是说当我们 new 一个空参 ArrayList 的时候,系统内部使用了一个 new Object[0]数组。
2)带参构造 1
/**
* Constructs a new instance of {@code ArrayList} with the specified
* initial capacity.
*
* @param capacity
* the initial capacity of this {@code ArrayList}.
*/
public ArrayList(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("capacity < 0: " + capacity);
}
array = (capacity == 0 ? EmptyArray.OBJECT : new Object[capacity]);
}
该构造函数传入一个 int 值,该值作为数组的长度值。如果该值小于 0,则抛出一个运行时异常。如果等于 0,则
使用一个空数组,如果大于 0,则创建一个长度为该值的新数组。
ArrayList 底层结构是数组,底层查询快,增删慢。
LinkedList 底层结构是链表型的,增删快,查询慢。
voctor 底层结构是数组 线程安全的,增删慢,查询慢。
4. ArrayList 和 Linkedlist 区别?
ArrayList 和 Vector 使用了数组的实现,可以认为 ArrayList 或者 Vector 封装了对内部数组的操作,比如向数组
中添加,删除,插入新的元素或者数据的扩展和重定向。
LinkedList 使用了循环双向链表数据结构。与基于数组的 ArrayList 相比,这是两种截然不同的实现技术,这也决
定了它们将适用于完全不同的工作场景。
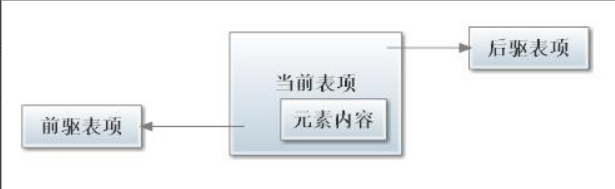
LinkedList 链表由一系列表项连接而成。一个表项总是包含 3 个部分:元素内容,前驱表和后驱表,如图所示:
在下图展示了一个包含 3 个元素的 LinkedList 的各个表项间的连接关系。在 JDK 的实现中,无论 LikedList 是否
为空,链表内部都有一个 header 表项,它既表示链表的开始,也表示链表的结尾。表项 header 的后驱表项便是链表
中第一个元素,表项 header 的前驱表项便是链表中最后一个元素。
 5.Map 中的 key 和 value 可以为 null 么?
5.Map 中的 key 和 value 可以为 null 么?
H
ashMap 对象的 key、value 值均可为 null。
HahTable 对象的 key、value 值均不可为 null。
且两者的的 key 值均不能重复,若添加 key 相同的键值对,后面的 value 会自动覆盖前面的 value,但不会报错。
三,多线程和并发库
未完待续。。。























 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









