







概述
YOLO11是YOLO系列实时目标检测器的最新迭代版本,在之前YOLO版本取得的显著进步基础上,YOLO11在架构和训练方法上进行了重大改进,使其成为各种计算机视觉任务中的通用选择。除了传统的目标检测外,YOLO11 还支持目标跟踪、实例分割、姿态估计、OBB定向物体检测(旋转目标检测)等视觉任务。
训练深度学习模型包括向其输入数据并调整其参数,使其能够做出准确的预测。Ultralytics YOLO11 中的 "训练 "模式充分利用现代硬件能力,专为高效训练物体检测模型而设计。
YOLO11训练模式的主要功能
- **自动下载数据集:**首次使用时会自动下载按配置所需的标准数据集和预训练模型。
- **支持多个GPU :**可以在多个 GPU 上无缝扩展,加快训练进程。能够自动选择使用CPU还是GPU。
- **超参数配置:**通过 YAML 配置文件或CLI 参数修改超参数的选项。
- **可视化和监控:**实时跟踪训练指标和可视化机器学习过程,为用户提供更好的洞察力。
数据集准备
本次训练主要针对停车场停放车辆和空位进行检测。检测空位主要是学术方面的需求,在实际工程应用中,只检测出停放的车辆就可以了,因为停车场车位数量是事先确定的。
由于停车场的形态各异,从各个角度看停车状况均不相同,要检测停车位的停车情况,并不是简单的事情。在选择训练数据的时候,需要需要到各种光照条件、视角、各种车辆角度、部分遮挡、各种停车场形态等问题,选择相关的图片,并加以标注。在训练过程中,YOLO还会对各种进行多种变形,以提高模型的泛化能力。
我们来看以下这副组合图,是YOLO训练过程输出的一个Batch(这里batch=8)的图片,涵盖了车位大小、倾斜、光照条件、不同角度等多种情况。

标注(Annotation)
选取合适的图片后,需要对图片进行标注(Annotation)。在停车检测任务中,只需要考虑两个class:车辆和空位,使用标注工具软件(例如labelimg)进行画框标注,输出YOLO格式的TXT文件。当然,也可以使用和需要检测场景有一定相关性的已有数据集,但要先核查标注的准确性。
TXT文件的标注格式为:
<class-index> x y w h
这里我们定义:0 car, 1 free
以下是一个图片标注的例子,有7个车位停放车辆,4个车位空闲
0 0.8734375 0.22421875 0.09375 0.1921875
0 0.73828125 0.2171875 0.1203125 0.2625
0 0.225 0.17890625 0.115625 0.2796875
0 0.6046875 0.2234375 0.134375 0.334375
0 0.9625 0.2640625 0.075 0.25
1 0.35078125 0.21875 0.1140625 0.24375
1 0.47421875 0.23828125 0.1078125 0.2703125
1 0.15390625 0.7046875 0.0671875 0.121875
0 0.571875 0.7515625 0.1875 0.128125
1 0.01171875 0.6953125 0.0234375 0.103125
0 0.79296875 0.7921875 0.1796875 0.159375
数据集目录结构
path
└-- datasets
|-- train
| |-- images
| └-- labels
└-- val
|-- images
└-- labels
图片和labels
本次训练使用了1600副图片,其中1250用于训练集,350用于验证集。图片分辨率为640*640。
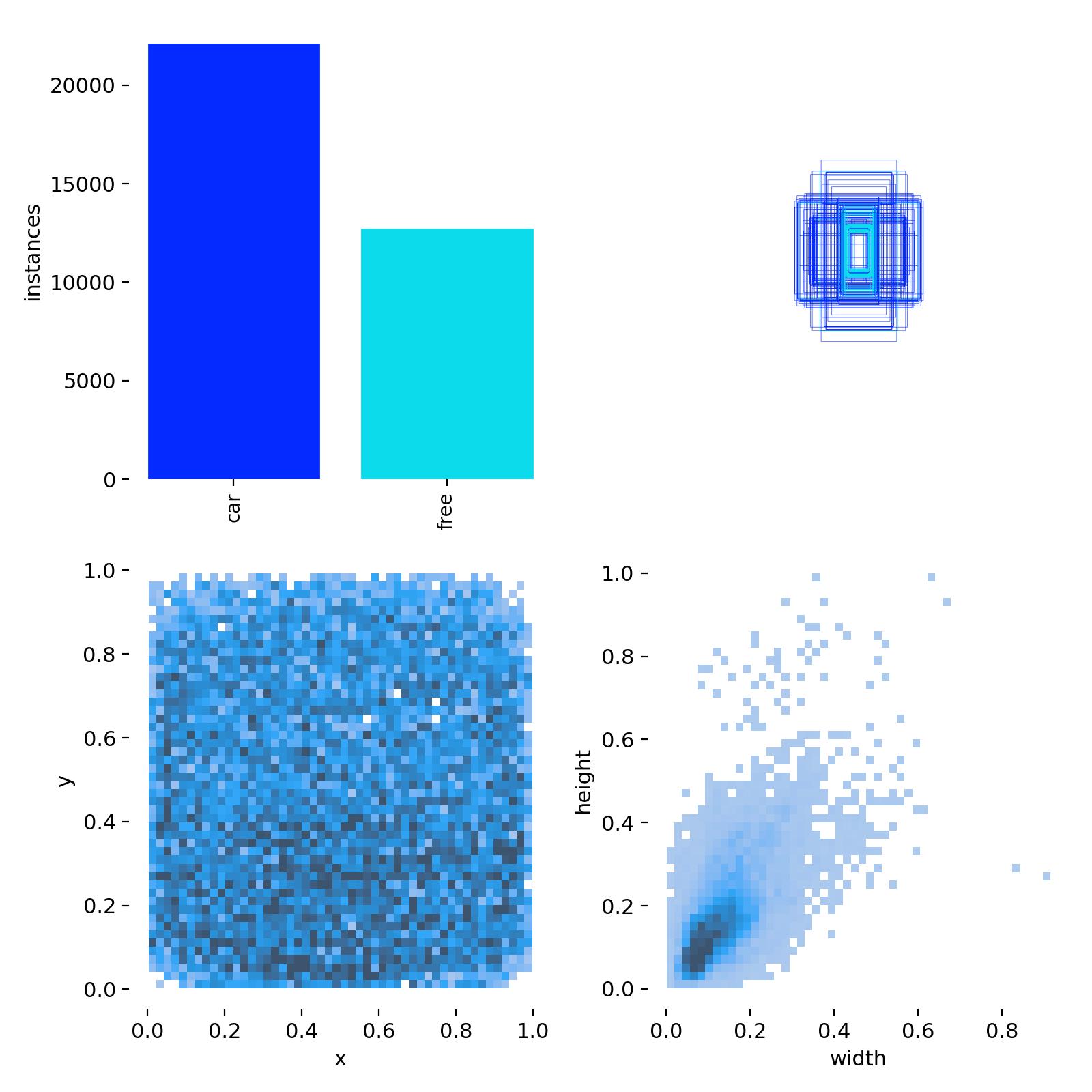
通过Labels分布图可以看到,在所有实例中,占用车位比空闲车位多。标注框的中心分布(左下图),在所有图片中比较均匀,车位大小(右下图)绝大部分是比较小的尺寸。
训练代码和参数
本次训练基本使用缺省参数,训练了200轮,imgsz设置为640。
预训练模型使用yolo11n.pt
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.yaml").load("yolo11n.pt") # 使用YAML和预训练模型构建新模型
# Train the model
results = model.train(data="data.yaml", epochs=200, imgsz=640, batch=8) #不传入device参数时,系统根据机器配置自动使用GPU或CPU,优先选用GPU
这个batch是指一次训练多少张图片,训练结束后在runs文件下的图片会看到类似上面的组合图片。
Batch参数的大小,需要根据你的计算机的配置确定,如果你用CPU进行训练,需要根据RAM大小确定。如果你用GPU训练,需要根据显卡显存确定。YOLO缺省的参数是16。当然,也可以设置成“-1”,让系统自动确定(但不一定是最好的选择)。batch大,显存/内存占用多,如果显存/内存不足,训练可能会失败或变得非常缓慢。如果batch设置的太小,那么利用率可能太低,会造成资源闲置。一般可以从一个较小的batch开始,如8或16,然后逐步增加,查看显存/内存占用到80%左右,就是比较合适的。
训练结果
各种指标曲线
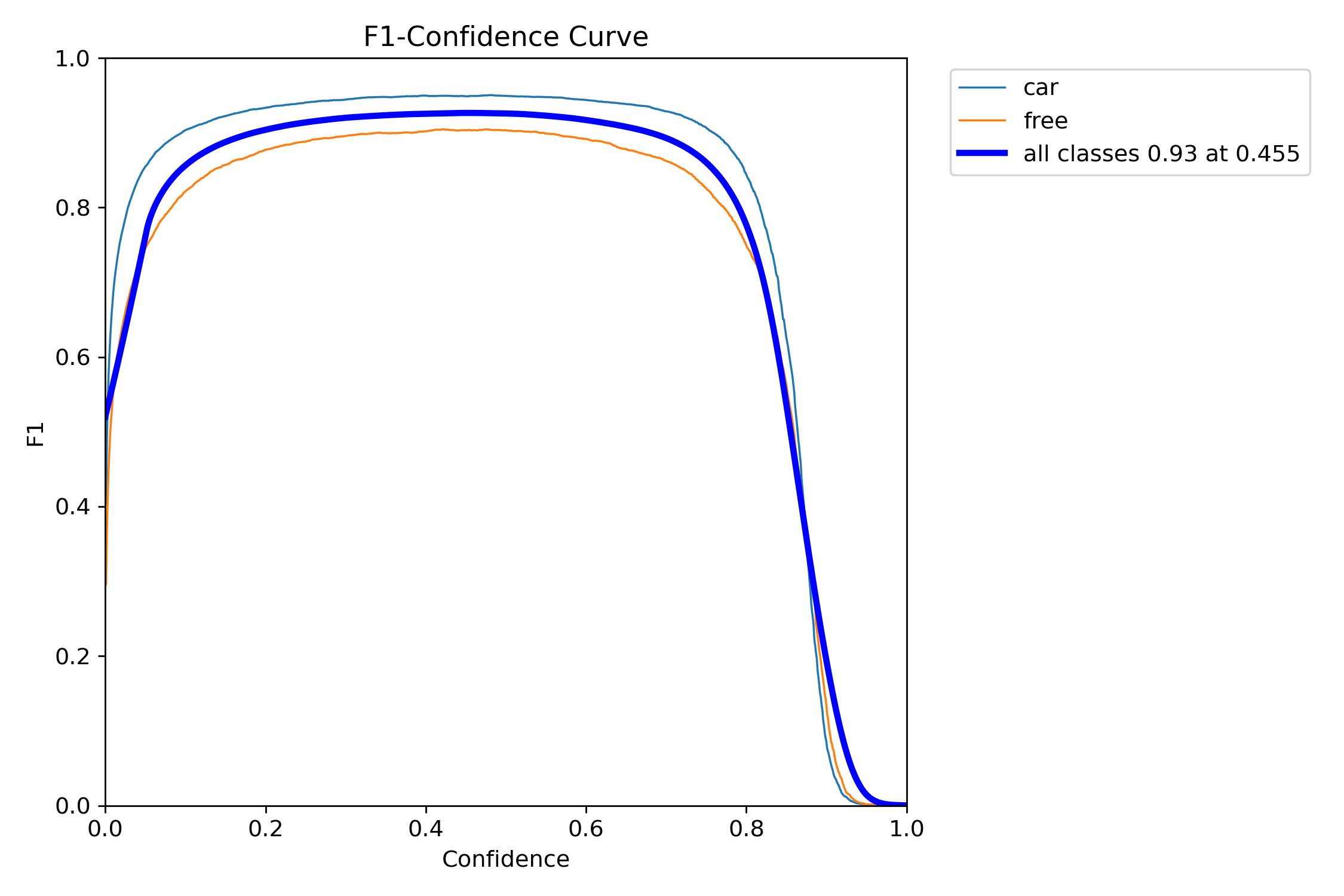
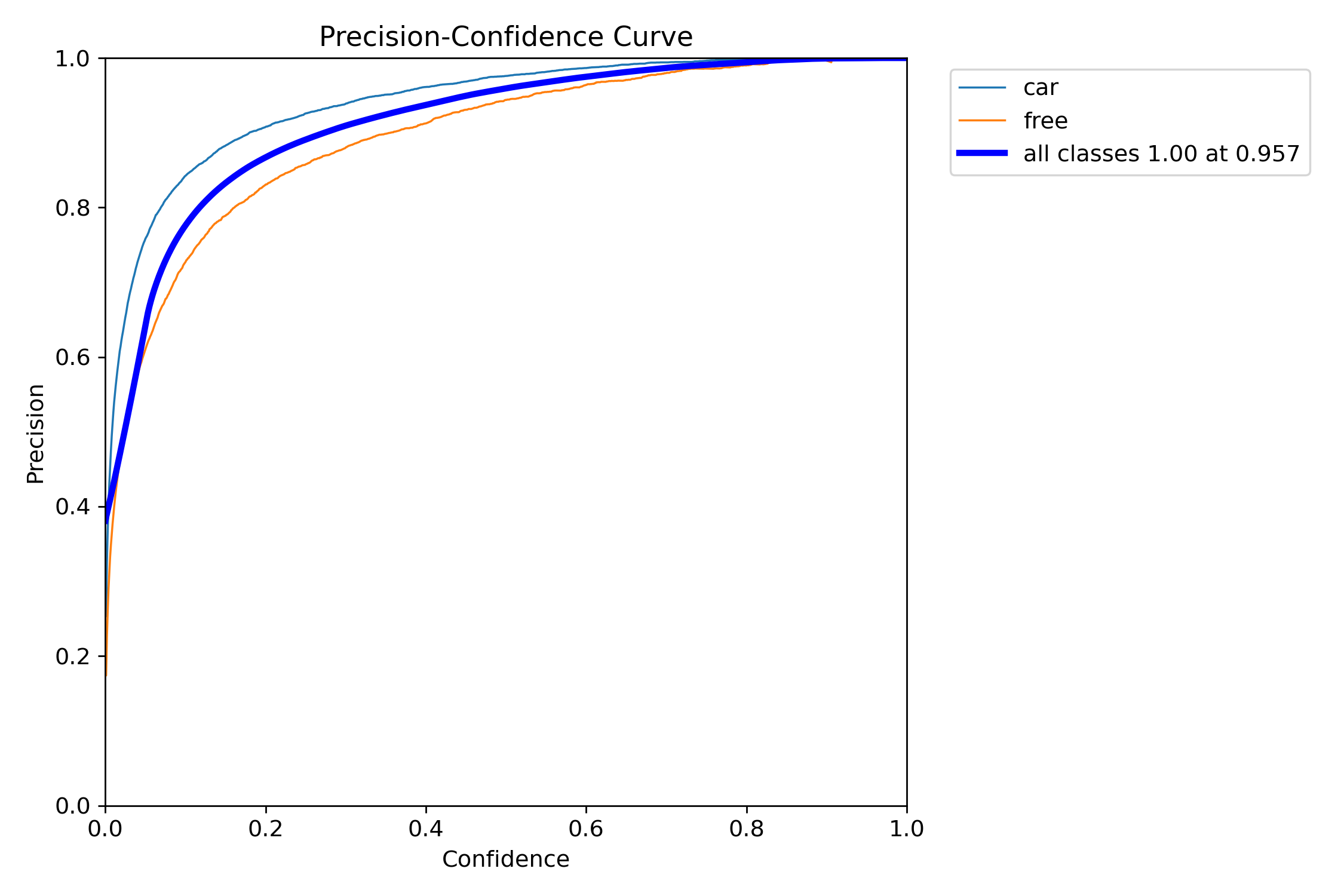
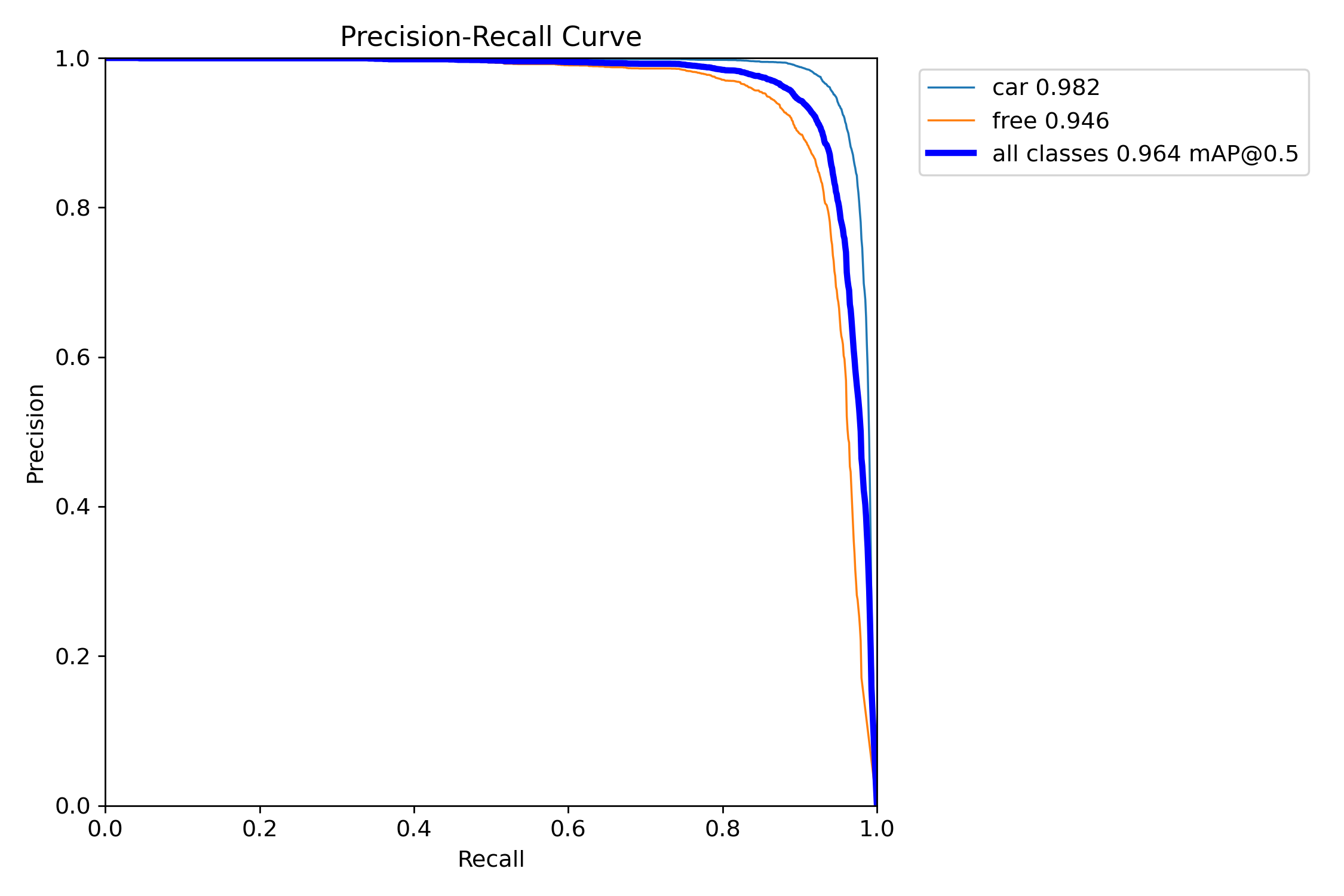
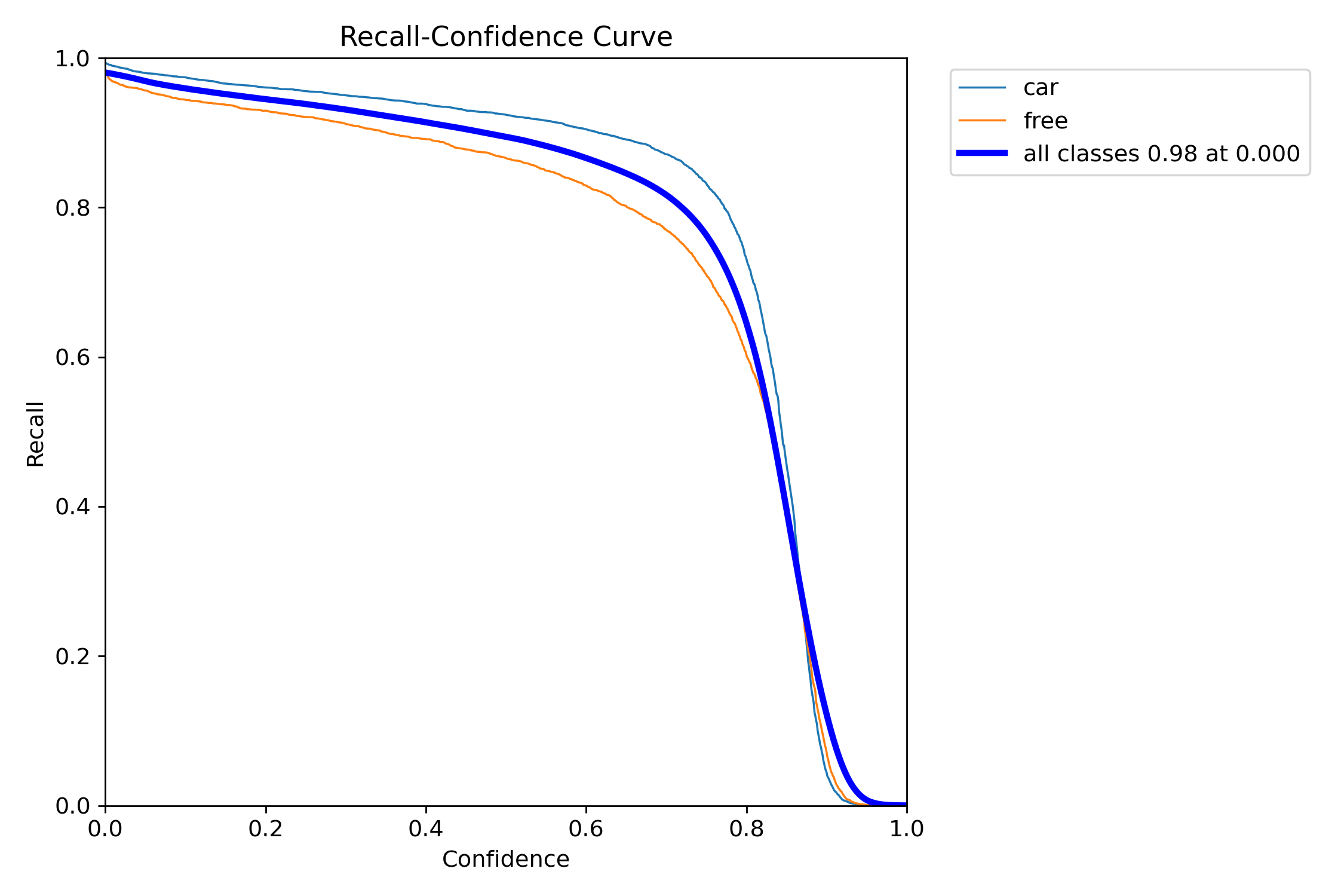
损失函数曲线和精度曲线,如下图所示。
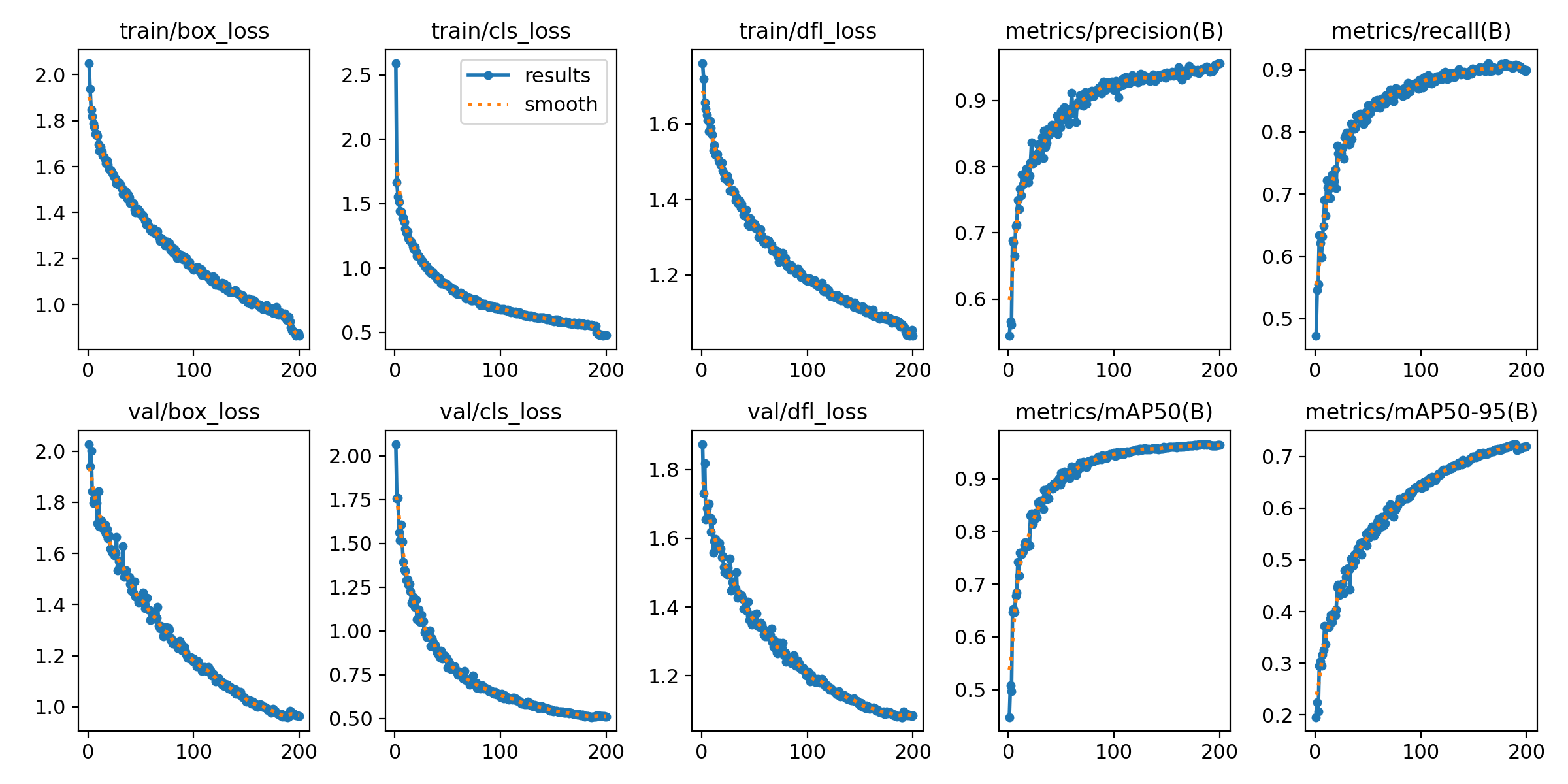
左边6幅图,上面的是训练过程中的损失函数曲线,下面是验证过程的损失函数曲线。在训练到200轮次的时候,都降到了比较低的水平,整个过程均呈下降趋势。
右上角2副图是bounding box的精度和召回率曲线。右下2副图是平均精度曲线(mAP,可以简单理解为预测框和真实框的重合度),mAP50是重合度50%的平均精度,mAP50-95则是重合度从50%到95%范围内的平均值,mAP50-95的值比mAP50低。
训练过程中的验证标注图和预测图


通过这两幅图能看出训练到一定轮次,模型的预测结果和标注框之间的差异。
使用真实停车场图片测试
模型训练出来, 表现怎么样,除了上述的指标分析,还需要找实际的场景运行看看。我们使用下面的代码来进行预测。
预测代码
import os
import shutil
from ultralytics import YOLO
from functions import process_images
def yolo11_detect_predict(repo_path, model, conf, iou):
modelname = os.path.basename(model)
# Remove folder if it exists
if os.path.exists(os.path.join(repo_path, f'results/{modelname[:-3]}/')):
shutil.rmtree(os.path.join(repo_path, f'results/{modelname[:-3]}/'))
dest_path=modelname[:-3]
model = YOLO(model)
source=os.path.join(repo_path, 'data/images')
project=os.path.join(repo_path, 'results/')
name=dest_path+"/yolo_images"
print(f"开始预测 {name}")
model.predict(source=source, save_txt=True, save=True, exist_ok=True, imgsz=1280, conf=conf, iou=iou, project=project, name=name)
print("运行预测完成")
if __name__ == '__main__':
repo_path = os.getcwd()
model = "./models/best.pt"
# Execute the yolo11 predict
yolo11_detect_predict(repo_path, model, conf=0.4, iou=0.45)
预测结果
以下是一些检测结果图片,可以看出,模型对这种规则排布的停车场,具有较好的准确度,但是对于空车位的检测,受到光线的影响比较显著,而对汽车的检测准确度很高。



车辆的检测结果较好,置信度一般也比较高,大部分在0.8以上。
但是,对于不规则排布的停车场,模型的适应性还有待提高。
如下图所示:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









