






阿里云人脸识别
官网地址如下:
https://vision.aliyun.com/
人脸识别SDK:
(我们以python为例)
要使用人脸识别得先安装他对应的SDK:
人脸人体:
pip install alibabacloud_facebody20191230
阿里云工作台入口:
https://vision.console.aliyun.com/cn-shanghai/detail/facebody/facebody/default
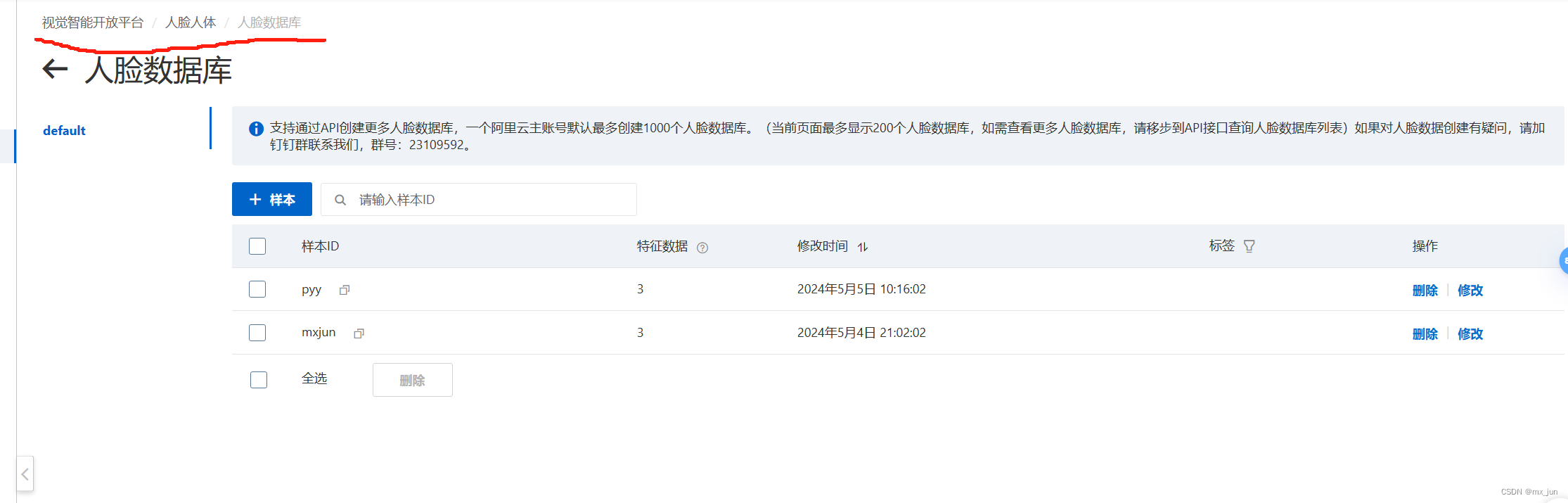
配置人脸图像库
进入上面工作台后,我们再进入如下位置先配置我们的人脸图像库(default)
--------------------------------
请确保已经配置了AccessKey
配置完后将其export加入你的 ~/.bashrc 底下
人脸识别python 实例代码:
官方原代码
# -*- coding: utf-8 -*-
# 引入依赖包
# pip install alibabacloud_facebody20191230import os
import io
from urllib.request import urlopen
from alibabacloud_facebody20191230.client import Client
from alibabacloud_facebody20191230.models import SearchFaceAdvanceRequest
from alibabacloud_tea_openapi.models import Config
from alibabacloud_tea_util.models import RuntimeOptionsconfig = Config(
# 创建AccessKey ID和AccessKey Secret,请参考https://help.aliyun.com/document_detail/175144.html。
# 如果您用的是RAM用户的AccessKey,还需要为RAM用户授予权限AliyunVIAPIFullAccess,请参考https://help.aliyun.com/document_detail/145025.html。
# 从环境变量读取配置的AccessKey ID和AccessKey Secret。运行代码示例前必须先配置环境变量。
access_key_id=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID'),
access_key_secret=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
# 访问的域名
endpoint='facebody.cn-shanghai.aliyuncs.com',
# 访问的域名对应的region
region_id='cn-shanghai'
)search_face_request = SearchFaceAdvanceRequest()
#场景一:文件在本地
stream0 = open(r'/tmp/SearchFace.jpg', 'rb')
search_face_request.image_url_object = stream0#场景二:使用任意可访问的url
#url = 'https://viapi-test-bj.oss-cn-beijing.aliyuncs.com/viapi-3.0domepic/facebody/SearchFace1.png'
img = urlopen(url).read()
search_face_request.image_url_object = io.BytesIO(img)
search_face_request.db_name = 'Face1'
search_face_request.limit = 5runtime_option = RuntimeOptions()
try:
# 初始化Client
client = Client(config)
response = client.search_face_advance(search_face_request, runtime_option)
# 获取整体结果
print(response.body)
except Exception as error:
# 获取整体报错信息
print(error)
# 获取单个字段
print(error.code)
# tips: 可通过error.__dict__查看属性名称#关闭流
#stream0.close()
以下代码根据官方给的实例修改得到
修改后的实例:
# -*- coding: utf-8 -*-
# 引入依赖包
# pip install alibabacloud_facebody20191230import os
import io
from urllib.request import urlopen
from alibabacloud_facebody20191230.client import Client
from alibabacloud_facebody20191230.models import SearchFaceAdvanceRequest
from alibabacloud_tea_openapi.models import Config
from alibabacloud_tea_util.models import RuntimeOptionsconfig = Config(
# 创建AccessKey ID和AccessKey Secret,请参考https://help.aliyun.com/document_detail/175144.html。
# 如果您用的是RAM用户的AccessKey,还需要为RAM用户授予权限AliyunVIAPIFullAccess,请参考https://help.aliyun.com/document_detail/145025.html。
# 从环境变量读取配置的AccessKey ID和AccessKey Secret。运行代码示例前必须先配置环境变量。
access_key_id=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID'),
access_key_secret=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
# 访问的域名
endpoint='facebody.cn-shanghai.aliyuncs.com',
# 访问的域名对应的region
region_id='cn-shanghai'
)def alibaba_face():
search_face_request = SearchFaceAdvanceRequest()
#场景一:文件在本地# 请确保你的这个本地文件存在
stream0 = open(r'/tmp/SearchFace.jpg', 'rb')
search_face_request.image_url_object = stream0#场景二:使用任意可访问的url
# url = 'https://viapi-test-bj.oss-cn-beijing.aliyuncs.com/viapi-3.0domepic/facebody/SearchFace1.png'
# img = urlopen(url).read()
# search_face_request.image_url_object = io.BytesIO(img)# 我们的比较对象是default -- 默认人脸图像库
search_face_request.db_name = 'default'
search_face_request.limit = 5runtime_option = RuntimeOptions()
try:
# 初始化Client
client = Client(config)
# print("line 44 init Client Success!")
response = client.search_face_advance(search_face_request, runtime_option)
# 获取整体结果
# print(response.body)
match_list = response.body.to_map()['Data']['MatchList'] # 拿到所有我们的需要的字典(存放键值对)
scores = [item['Score'] for item in match_list[0]['FaceItems']] # 取到字典中所有的 key= 'Score',的value --> 取到所有的分数(人脸匹配度)
highest_score = max(scores) #
value = round(highest_score, 2) # 四舍五入去小数点后两位
print(value)
# print("line 56 获取得到效果 Success!")
return value
except Exception as error:
# 获取整体报错信息
print(error)
# print("Line 62 有错")
# 获取单个字段
print(error.code)
# tips: 可通过error.__dict__查看属性名称
# print("Line 66 有错")#关闭流
#stream0.close()if __name__ == "__main__":
alibaba_face()
------------------------------------
输出数据:
{'Data': {'MatchList': [{'FaceItems': [{'Confidence': 89.82196, 'DbName': 'default', 'EntityId': 'mxjun', 'FaceId': '144368497', 'Score': 0.8729780316352844},
{'Confidence': 73.34613, 'DbName': 'default', 'EntityId': 'mxjun', 'FaceId': '144368491', 'Score': 0.6268069744110107},
{'Confidence': 72.958725, 'DbName': 'default', 'EntityId': 'mxjun', 'FaceId': '144368500', 'Score': 0.6124728918075562},
{'Confidence': 14.665969, 'DbName': 'default', 'EntityId': 'pyy', 'FaceId': '144512167', 'Score': 0.08487027883529663},
{'Confidence': 2.3494823, 'DbName': 'default', 'EntityId': 'pyy', 'FaceId': '144512114', 'Score': 0.01359618455171585}],
'Location': {'Height': 587, 'Width': 394, 'X': 379, 'Y': 485}, 'QualitieScore': 99.98341}]},
'RequestId': 'C4174478-9678-5797-B4F8-43C12F4D2DB0'}
数据解析结构图:

输出解读:
这段数据是一个嵌套的字典结构,主要包含两部分关键信息:`Data`和`RequestId`。下面是详细的解析:
### Data部分
- **MatchList**: 这是一个列表,包含了至少一个匹配项。每个匹配项都是一个字典,具体结构如下:
- **FaceItems**: 这是一个列表,包含了多个面部识别的结果。每个结果又是一个字典,包含以下键值对:
- **Confidence**: 表示识别的置信度,数值范围一般在0到100之间,值越大表示识别的准确度越高。
- **DbName**: 数据库名称,默认值为'default',表明这些数据来自哪个数据库。
- **EntityId**: 实体ID,可以理解为被识别的人的身份标识。
- **FaceId**: 面部ID,用于唯一标识一个面部记录。
- **Score**: 可能是另一个衡量匹配程度的分数,数值范围同样可能在0到1之间。- **Location**: 一个字典,描述了识别到的面部在图像中的位置信息,包含:
- **Height**: 高度像素值。
- **Width**: 宽度像素值。
- **X**: X坐标,表示距离图片左侧的距离。
- **Y**: Y坐标,表示距离图片顶部的距离。- **QualitieScore**: 图像质量得分,接近100表示图像质量非常好,利于面部识别。
### RequestId部分
- **RequestId**: 字符串类型,唯一标识这次请求的ID,通常用于日志追踪或问题排查。
### 示例解析
从数据看,`MatchList`中有一个匹配项,该匹配项识别到了与`EntityId`为'mxjun'相关的多个面部记录,以及与`EntityId`为'pyy'相关的两个面部记录。识别位置信息、置信度以及其他评分都详细列出,这对于分析识别效果非常有帮助。此外,整个请求的唯一标识是`C4174478-9678-5797-B4F8-43C12F4D2DB0`。
DBname 人脸识别的数据库的名字 -- default
在人脸数据库中去比对找到score(匹配度) -->
拿到匹配度 最大的一个 -- 比如我们这样设置if>60 --> 识别成功 else -->识别失败
===========================================
小插曲: 设置python优先级:
系统同时存在 python2 和 python3的时候,怎么 把python3 设为默认python
sudo update-alternatives --install /usr/bin/python python /usr/bin/python2 100
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 200
这里的数字(100和200)是优先级,数字越大优先级越高。所以上面的命令将python3设置为默认版本。
然后,你可以使用以下,命令来查看和更改默认设置:
sudo update-alternatives --config python
注: printf -- 打印注意,每次打印结束记得加上 '\n' --> 不然数据可能缓冲到系统里面
==================================
C 语言调用python 接口:
分装原来的python代码要求放回其中score最大值:
# -*- coding: utf-8 -*-
# 引入依赖包
# pip install alibabacloud_facebody20191230
import os
import io
from urllib.request import urlopen
from alibabacloud_facebody20191230.client import Client
from alibabacloud_facebody20191230.models import SearchFaceAdvanceRequest
from alibabacloud_tea_openapi.models import Config
from alibabacloud_tea_util.models import RuntimeOptions
config = Config(
# 创建AccessKey ID和AccessKey Secret,请参考https://help.aliyun.com/document_detail/175144.html。
# 如果您用的是RAM用户的AccessKey,还需要为RAM用户授予权限AliyunVIAPIFullAccess,请参考https://help.aliyun.com/document_detail/145025.html。
# 从环境变量读取配置的AccessKey ID和AccessKey Secret。运行代码示例前必须先配置环境变量。
access_key_id=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID'),
access_key_secret=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
# 访问的域名
endpoint='facebody.cn-shanghai.aliyuncs.com',
# 访问的域名对应的region
region_id='cn-shanghai'
)
def alibaba_face():
search_face_request = SearchFaceAdvanceRequest()
#场景一:文件在本地
stream0 = open(r'/tmp/SearchFace.jpg', 'rb')
search_face_request.image_url_object = stream0
#场景二:使用任意可访问的url
# url = 'https://viapi-test-bj.oss-cn-beijing.aliyuncs.com/viapi-3.0domepic/facebody/SearchFace1.png'
# img = urlopen(url).read()
# search_face_request.image_url_object = io.BytesIO(img)
search_face_request.db_name = 'default'
search_face_request.limit = 5
runtime_option = RuntimeOptions()
try:
# 初始化Client
client = Client(config)
# print("line 44 init Client Success!")
response = client.search_face_advance(search_face_request, runtime_option)
# 获取整体结果
print(response.body)
#这行代码使用了列表推导式,它遍历match_list列表中的第一个元素(索引为0)所包含的FaceItems列表。
# 对于FaceItems列表中的每个项目(假设每个项目都是一个字典),它提取出键为'Score'的值,并将这些值组成一个新的列表
match_list = response.body.to_map()['Data']['MatchList'] # 拿到所有我们的需要的字典
# 外面加这个[] -- set集合,无序不重复数据集合
scores = [item['Score'] for item in match_list[0]['FaceItems']] # 取到字典中所有的 key= 'Score',的value --> 取到所有的分数(人脸匹配度)
highest_score = max(scores) #
value = round(highest_score, 2) # 四舍五入去小数点后两位
# print(value)
# print("line 56 获取得到效果 Success!")
return value
except Exception as error:
# 获取整体报错信息
print(error)
# print("Line 62 有错")
# 获取单个字段
print(error.code)
# tips: 可通过error.__dict__查看属性名称
# print("Line 66 有错")
#关闭流
#stream0.close()
face.c: C 语言调用python 接口:
#include <Python.h>
void face_init(void)
{
Py_Initialize();
PyObject *sys = PyImport_ImportModule("sys");
PyObject *path = PyObject_GetAttrString(sys, "path");
PyList_Append(path, PyUnicode_FromString("."));
}
void face_final(void)
{
Py_Finalize();
}
double face_category(void)
{
// 加载face.py 这个文件
PyObject *pModule = PyImport_ImportModule("face");
if (!pModule)
{
PyErr_Print();
printf("Error: failed to load face.py\n");
goto FAILED_MODULE;
}
// 加载(获取) alibaba_face() 这个函数 -- 顺便判断是否存在
PyObject *pfunc = PyObject_GetAttrString(pModule, "alibaba_face");
if (!pfunc)
{
PyErr_Print();
printf("Error: failed to load alibaba_face\n");
goto FAILED_FUNC;
}
// 调用我们获取到的函数
PyObject *pValue = PyObject_CallObject(pfunc, NULL);
if (!pValue)
{
PyErr_Print();
printf("Error:function call failed\n");
goto FAILED_VALUE;
}
double result = 0.0;
if (!PyArg_Parse(pValue, "d", &result)) // 解析获取 alibaba_face() 返回值, 转换成C语言格式
{
PyErr_Print();
printf("Error:face failed\n");
goto FAILED_RESULT;
}
printf("result=%.2lf\n", result);
// 注意释放顺序是反的,从新到旧
// 添加跳转位置,当发生错误的时候,跳转过来将他释放
FAILED_RESULT:
Py_DECREF(pValue);
FAILED_VALUE:
Py_DECREF(pfunc);
FAILED_FUNC:
Py_DECREF(pModule);
FAILED_MODULE:
return result;
}
---------------------------------------
face.h
#ifndef __FACE_H__
#define __FACE_H__
void face_init(void);
double face_category(void);
void face_final(void);
#endif
main.c
#include<Python.h>
#include<stdio.h>
#include "face.h"
int main(int argc, char **argv)
{
double face_result = 0.0;
face_init();
face_result = face_category();
printf("face_result =%.2lf\n", face_result);
face_final();
return 0;
}怎么编译:
请核对自己python版本,确保已经安装python3,不然不够新调用不动阿里云的 API
gcc -o face face.c main.c -I /usr/include/python3.10/ -L /usr/lib/python3.10/ -lpython3.10
执行:
执行生成的face文件即可
.face















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









