









昨天说了在kibana中使用es的语句查询折线图和统计图,今天废话少说直接上代码
es固定写法
SearchRequest request = new SearchRequest(indices);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
这里我们可以使用这个代码对应的就是我昨天写的filter 的部分
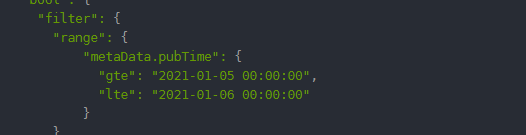
RangeQueryBuilder time = QueryBuilders.rangeQuery("metaData.pubTime").gte(timeNodeTotal.getStartTime()).lte(timeNodeTotal.getEndTime());
对应以下代码
接下来就是写我们agg的东西在java聚合当中aggas我们使用
AggregationBuilders 来调用以下是代码
AggregationBuilder aggregationBuilder = AggregationBuilders.dateHistogram("aggas")
.field("metaData.pubTime")
.fixedInterval(DateHistogramInterval.hours(timeNodeTotal.getDivision()))
.minDocCount(0);
这里我使用aggas为桶 在java聚合当中,我们需要的是桶来操作我们的数据在上面调用中对应的Es代码模块是以下内容。
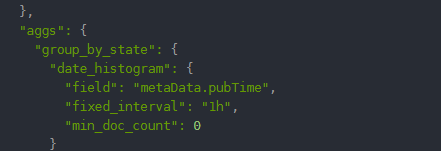
这个时候就已经把安时间分割已经出来了,fixedInterval(DateHistogramInterval.hours()) 中是设置你为什么分割。我在源码里面发现他里面也可以使用他定义好的间隔,我当前是因为项目需要人工控制时间使用就没有使用他自己的定义好的,这里源码可以看见,1秒,1分钟,1小时等等,需要的可以自己在源码里面选择自己需求所需要的

下面就是统计出现的数量
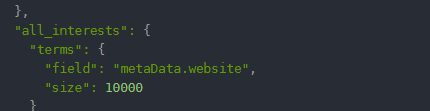
TermsAggregationBuilder webtotal = AggregationBuilders.terms("webtotal").field("metaData.website").size(10000);
对应Es代码为
现在已经把Es语句在java中写好了执行
searchSourceBuilder.timeout(new TimeValue(30, TimeUnit.SECONDS));
searchSourceBuilder.query(boolQueryBuilder).aggregation(aggregationBuilder);
searchSourceBuilder.query(boolQueryBuilder).aggregation(webtotal);
searchSourceBuilder.query(boolQueryBuilder);
request.source(searchSourceBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
这里代码中 SearchResponse search = client.search(request, RequestOptions.DEFAULT);
可能是会抛异常 看情况处理
取Es中查询出来的内容,在平时去es数据的时候都是
search.getHits().getHits()
然后在get出所有数据循环就可以得到数据,但是现在我是创建了桶,所以是要在桶中取数据
通过取桶有很多方式,目前我使用了两种
第一种
ArrayList<Map<String, Object>> DataList = new ArrayList<>();
Aggregation agg = search.getAggregations().get("aggas");
List<? extends Histogram.Bucket> buckets = ((Histogram) agg).getBuckets();
for (Histogram.Bucket bucket : buckets) {
HashMap<String, Object> tetool = new HashMap<>();
tetool.put("data", bucket.getKeyAsString());
tetool.put("dataCount", bucket.getDocCount());
DataList.add(tetool);
}
第二种
ArrayList<Map<String, Object>> weblist = new ArrayList<>();
Terms web = search.getAggregations().get("webtotal");
List<? extends Terms.Bucket> webBuckets = web.getBuckets();
在这里的时候和上面一样foreach 循环拿出来就可以 在我这里我对数据全是用的map储存的,用万能的map处理当然不是唯一的 。
如果对于上面Es语句不懂的:点击这里
Es7.6官网文档:点击这里
多看官网,我的聚合也是看官方文档一点点磨出来的















 3727
3727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









