







CUDA并行计算基础
这一部分是CUDA编程的基础中的基础。CUDA 线程层次 + 线程索引 + 线程分配
反正我跟着老师学习了理论课程以及做了实验后还是一知半解,那就自己写个博客继续复盘一下,达到初步认知CUDA编程的线程细节的层次。因为明天就要考试了嘛,现在还是一知半解,还怎么参加考试,先来复盘一下,然后再搞懂第一届考试题。冲冲冲!
文章目录
1. CUDA 线程层次
1.1 GPU CPU 术语
下面两个 host和device名词在CUDA编程中还是比较常见的。
host memory —— CPU的内存
device memory —— GPU的显存
运行程序所占的代码量如下图所示,我们要用GPU加速跑的最慢的关键部分,例如本图中的某5%的代码行(利用CUDA编写Kernel核函数进行加速),而跑的快的(不耗时)继续交给CPU执行

GPU将循环很多次的代码进行优化,加速程序运行。
1.2 线程层次术语
线程可以分为三个维度
Thread:sequential execution unit 顺序的执行单元
- 所有线程执行相同的核函数
- 并行执行
Thread Block:a group of threads 一组线程

- 一个block肯定是执行在同一个StreamingMultiProcessor(SM)流多处理器
- 同一个Block中的线程可以协作.
Thread Grid a collection of thread the threads 一个block的集合 - “一个Grid”当中的block可以在多个SM中执行
一个硬件可以执行多个block,但是一个block只能执行在一个SM中。
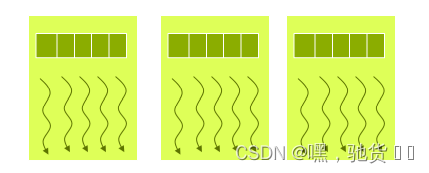
1.3 线程的索引
每一个层次可以分为三个维度
术语:
Bulit-in variables: 创建的变量
- threadIdx.[x,y,z] ——是当前kernel函数的线程在block中的索引值
- blockIdx.[x,y,z]——是执行当前kernel函数的线程所在block,在grid中的索引值
- blockDim.[x,y,z]——表示一个block中包含多少个线程
- gridDim.[x,y,z]——表示一个grid中包含多少个block
执行设置:
dim3 grid(3,2,1),block(5,3,1)
从图中我们可以看到,grid维度为 3,2 block维度为 5,3
如何选取索引位置呢?
就是看Idx了,blockIdx(1,1),和threadIdx(2,1)的索引如下图所示:
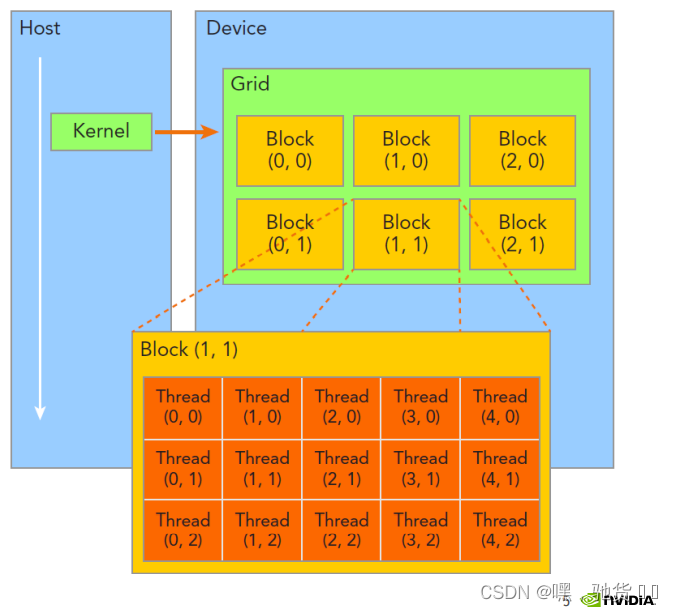 这里老师讲的比较快但是讲得很清楚,我觉得是这样哈,需要多斟酌几次,当时直接听课真的是很懵。
这里老师讲的比较快但是讲得很清楚,我觉得是这样哈,需要多斟酌几次,当时直接听课真的是很懵。
1.4 我们DAY1写的kernel核函数
两数之和,x代表的是thread中第一个维度的索引
__global__ void add(int *a,int *b, int*c){
c[threadIdx.x] = a[threadIdx.x] + b[threadIdx.x];//.x代表的是第一个维度的索引
}
add<<<1,4>>>(a,b,c)
核函数在global memory(也就是显存)中按照索引读取数值,
核函数:add<<<1,4>>>(a,b,c) 这个1和4其实代表的就是grid和block的维度
代表1个grid中有1个block,1个block当中有4个thread,一共是四个线程
设备上所选择的cuda核都是执行的一个kernel函数,设备实际执行如下:
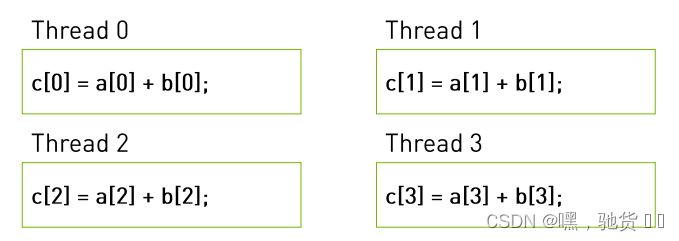
其中<<<1,4>>>也可以是数组
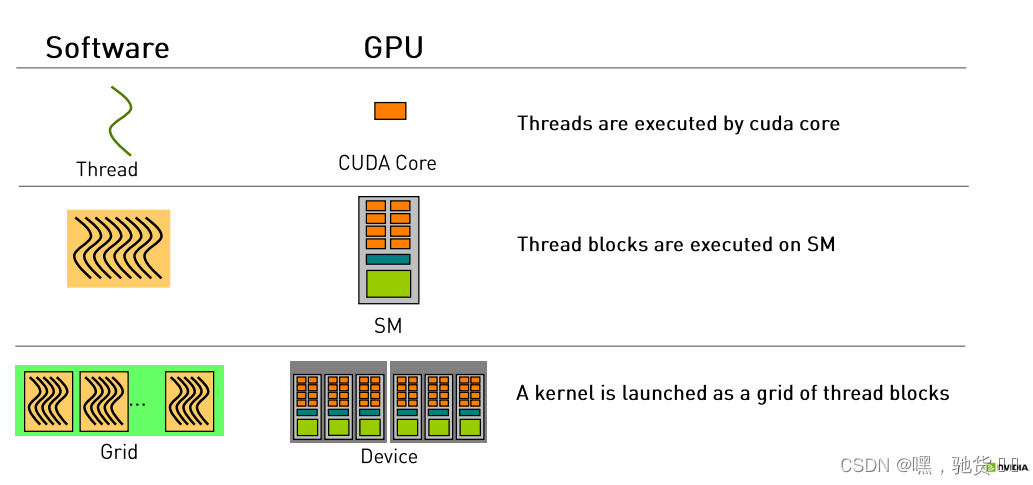
1.5 软件与硬件的术语的执行位置的对应
| 软件 | 显卡 |
|---|---|
| Thread线程 | CUDA Core |
| Block | SM |
| Grid | Device |
一个术语对应的软件可以跑在一个设备上,反过来不一样,一个术语对应的显卡硬件设备可以跑多个软件
2. CUDA 的执行流程
为什么会有Block和Grid?
这是GPU的物理架构所导致的。
2.1 核函数运行流程
- 加载合函数
- 将Grid分配到一个Device
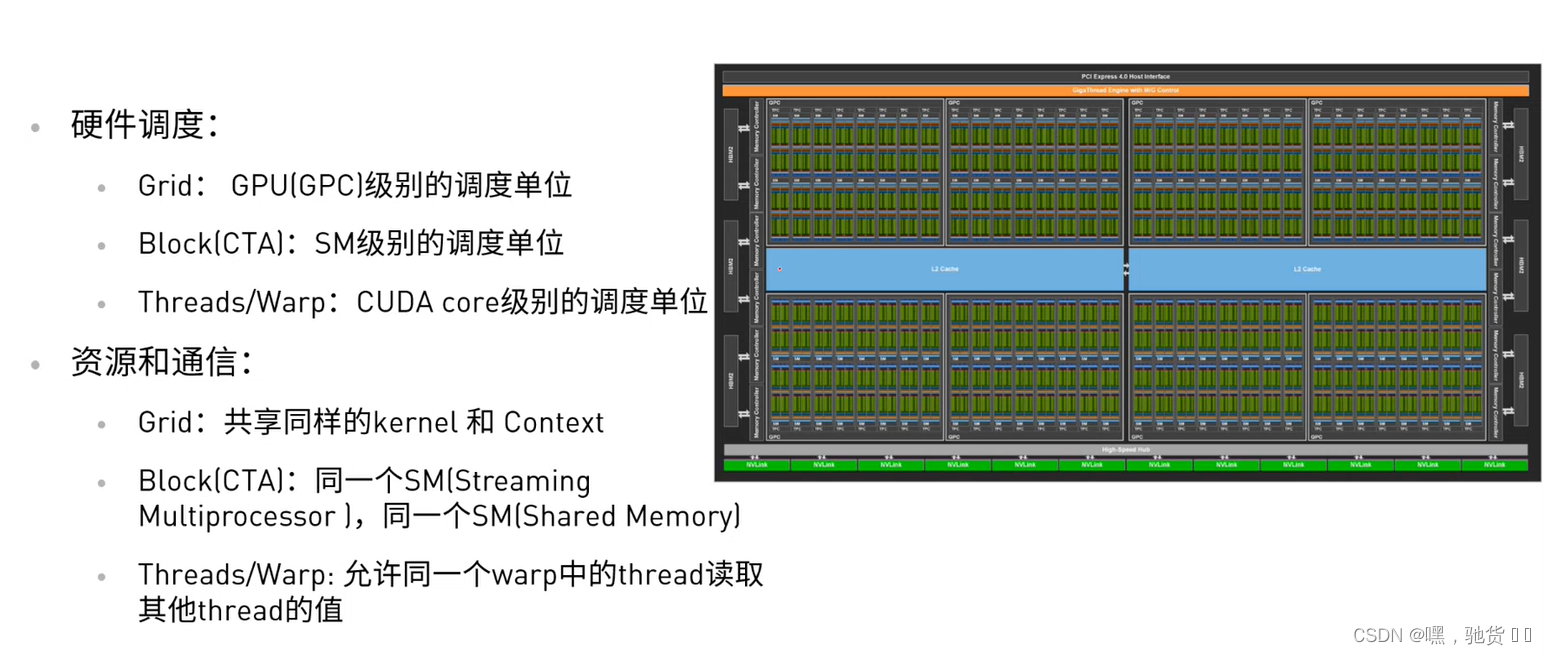
- 根据<<<…>>>内的执行设置的第一个参数,Giga threads engine将block分配到SM中。一个Block内的线程一定会在一个SM内,一个SM可以有很多个Block
- 根据<<<…>>>内的执行设置的第二个参数,Warp调度器会调用线程。
- Warp调度器为了提高运行效率,会将每32个线程分为一组,32是cuda故意设计的。
2.2 硬件调度以及资源和通信
3. CUDA的线程索引
如何让线程找到它该处理的数据——如何确定线程执行的数据
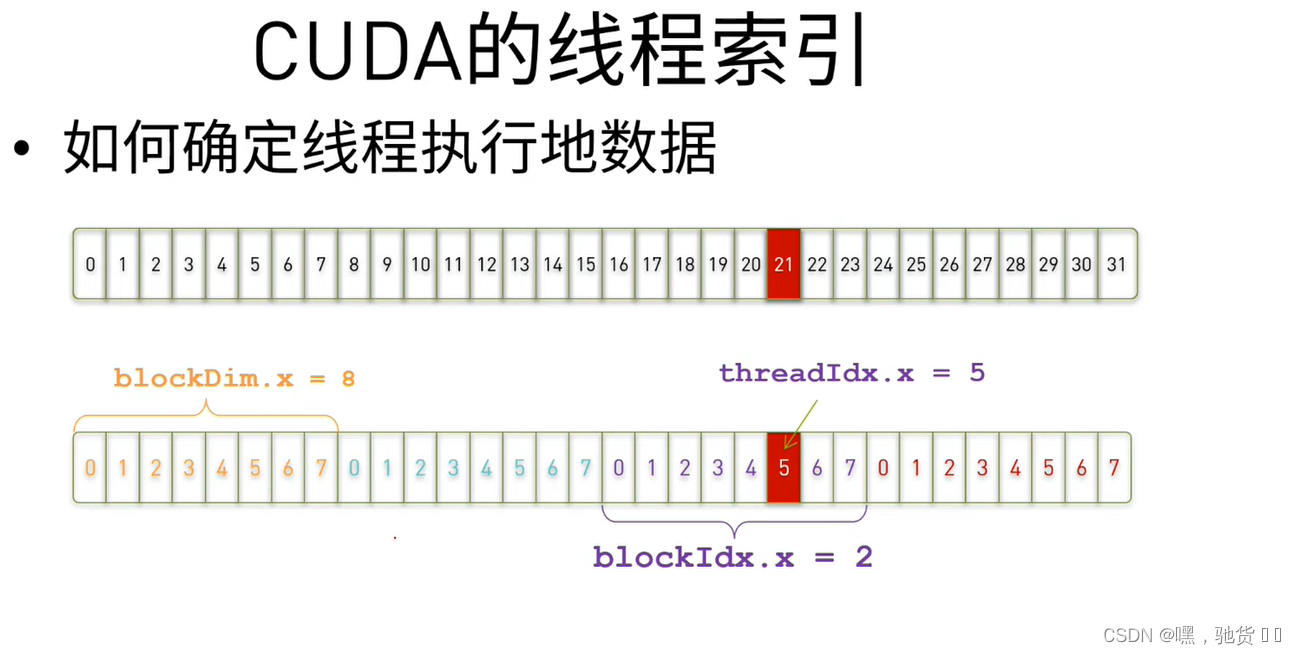
真正的计算机的存储地址是连续的不是矩形的,且C语言索引是0打头的,我们的全局索引就是这个index值,下图以一维为例。
假设8个线程分为一个block,即block维度为8,确认流程如下:
索引计算公式如下,

那第21个数据对应的线程的索引值就是固定的了,同理22对应着下一个线程,23……。也就是说这样就可以让我们的一个线程处理一个数据,高速的进行并行计算。
从此每个数据都有与之对应的线程的索引值了
每个线程都执行相同的命令
公式结合代码看,大家就理解了:
__global__ void add(const double *x,const double *y, double *z)
{
const int n = threadIdx.x + blockDim.x * blockIdx.x;
z[n] = x[n] + y[n];
}
同理,上升到二维,想找到Y方向的全局索引,换成.y就可以了
n = threadIdx.x + blockDim.x * blockIdx.x;
要想拿到别人拿不到的工资,就要吃别人吃不了的苦。















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









