







一. 场景分析
为了优化系统的响应速度,对于那些访问频率高但更新频率低的数据,使用缓存可以显著减少数据库查询次数,提升用户体验。
这里以主页精选应用为例,具体就是缓存前十页的精选应用列表数据。因为精选应用的更新频率相对较低。
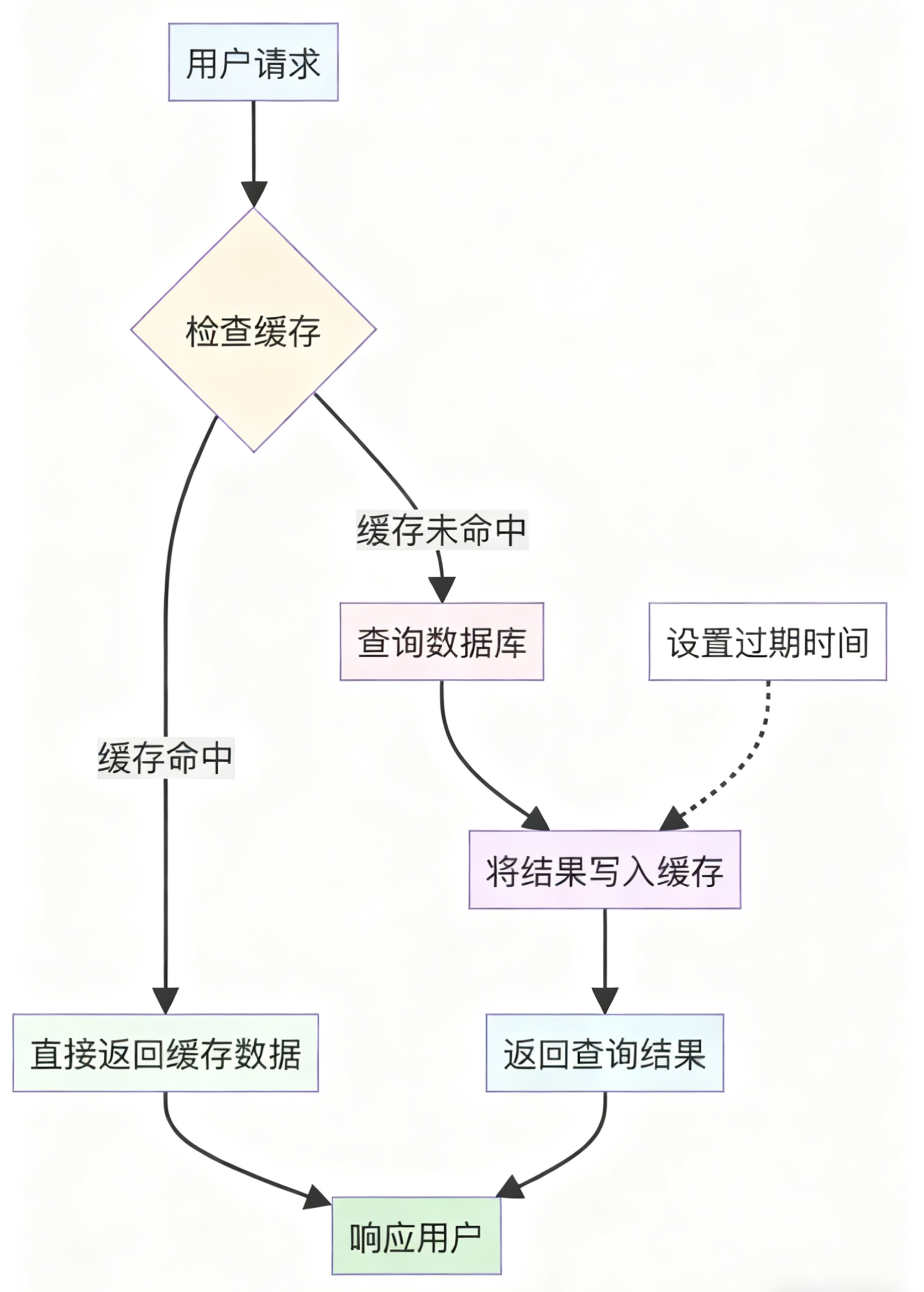
这种场景下我们采用最主流的旁路缓存模式:查询时先查询缓存,命中则直接返回。未命中则查询数据库,返回数据并将其写入缓存。设置合理的过期时间,无需手动删除缓存。
二. 开发实现
1. 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>3.1.3</version> <!-- 此处版本号可根据实际需求调整,比如Spring Boot 3.1.x系列 -->
</dependency>
2.检查配置文件中的Redis连接信息
spring:
data:
redis:
host: localhost
port: 6379
database: 0
password:
ttl: 3600 # 缓存过期时间(秒)
3.. 缓存key生成工具类
3.1 给出查询精选应用的接口方法:
/**
* 分页获取精选应用列表
*
* @param appQueryRequest 查询请求
* @return 精选应用列表
*/
@PostMapping("/good/list/page/vo")
public BaseResponse<Page<AppVO>> listGoodAppVOByPage(@RequestBody AppQueryRequest appQueryRequest) {
}
3.2 AppQueryRequest请求类:
@EqualsAndHashCode(callSuper = true)
@Data
public class AppQueryRequest extends PageRequest implements Serializable {
/**
* id
*/
private Long id;
/**
* 应用名称
*/
private String appName;
/**
* 代码生成类型(枚举)
*/
private String codeGenType;
/**
* 优先级
*/
private Integer priority;
/**
* 创建用户id
*/
private Long userId;
private static final long serialVersionUID = 1L;
}
这里可以看到查询请求类有多个字段,如果用户每次的查询条件不同,生成的AppqueryRequest也是不同的。为了生成一致且唯一的缓存键。缓存键的生成思路是将复杂的对象转换为固定长度的哈希值。这样相同的查询条件生成的缓存key是相同的,保证了不同查询请求的key唯一,又避免了key过长的问题。
3.3 key生成工具类:
/**
* 缓存 key 生成工具类
*
* @author yupi
*/
public class CacheKeyUtils {
/**
* 根据对象生成缓存key (JSON + MD5)
*
* @param obj 要生成key的对象
* @return MD5哈希后的缓存key
*/
public static String generateKey(Object obj) {
if (obj == null) {
return DigestUtil.md5Hex("null");
}
// 先转JSON,再MD5
String jsonStr = JSONUtil.toJsonStr(obj);
return DigestUtil.md5Hex(jsonStr);
}
}
这个工具类主要使用 Hutool 工具库实现,几个要点:
1.JSON 序列化: 确保对象内容的一致性,相同内容的对象生成相同的字符串
2.MD5 哈希: 将长字符串转换为固定长度的字符串,避免 Redis key 过长
3.边界处理: 正确处理 null 值和空参数的情况
4. 启用缓存功能
再Spring Boot 启动类上添加 @EnableCaching 注解,支持 Spring Data 缓存注解。
@SpringBootApplication
@EnableCaching
public class SzjAiCodeApplication {
public static void main(String[] args) {
SpringApplication.run(SzjAiCodeApplication.class, args);
}
}
5. 配置缓存管理器
必须配置 Redis 缓存管理器 CacheManager,这是 Spring Cache 的核心组件。如果不配置的话,使用缓存注解时可能会报错。
/**
* Redis 缓存管理器配置
*/
@Configuration
public class RedisCacheManagerConfig {
@Resource
private RedisConnectionFactory redisConnectionFactory;
@Bean
public CacheManager cacheManager() {
// 配置 ObjectMapper 支持 Java8 时间类型
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.registerModule(new JavaTimeModule());
// // 默认类型配置:启用默认类型信息(针对非final类),以便反序列化时能恢复原类型
// objectMapper.activateDefaultTyping(
// objectMapper.getPolymorphicTypeValidator(),
// ObjectMapper.DefaultTyping.NON_FINAL
// );
// 默认配置
RedisCacheConfiguration defaultConfig = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(30)) // 默认 30 分钟过期
.disableCachingNullValues() // 禁用 null 值缓存
// key 使用 String 序列化器
.serializeKeysWith(RedisSerializationContext.SerializationPair
.fromSerializer(new StringRedisSerializer()));
//不打开即使用redis的默认序列化器
// // value 使用 JSON 序列化器(支持复杂对象)但是要注意开启后需要给序列化增加默认类型配置,否则无法反序列化
// .serializeValuesWith(RedisSerializationContext.SerializationPair
// .fromSerializer(new GenericJackson2JsonRedisSerializer(objectMapper)));
//
return RedisCacheManager.builder(redisConnectionFactory)
.cacheDefaults(defaultConfig)
// 针对 good_app_page 配置5分钟过期
.withCacheConfiguration("good_app_page",
defaultConfig.entryTtl(Duration.ofMinutes(5)))
.build();
}
}
这个配置的几个关键点:
1. 序列化器选择: StringRedisSerializer 用于序列化 key,确保 Redis 中的 key 是可读的字符串;GenericJackson2JsonRedisSerializer 用于序列化 value,支持复杂对象的序列化和反序列化。
2. 时间类型支持: 注册 JavaTimeModule 来支持 Java 8 时间类型 LocalDateTime
3. 差异化配置: 既提供了默认配置,又为特定的缓存区域设置不同的过期时间
但是要注意,如果对 value 进行 JSON 序列化,可能会出现无法反序列化的情况,因为 Redis 中并没有存储 Java 类的信息,不知道要反序列化成哪个类,就会报错。所以我们可以先注释掉这些代码,使用redis默认的序列化器。
如果一定要对 value 进行 JSON 序列化,则开启默认类型配置,并且要反序列化的对象一定要有无参构造方法。
6. 应用缓存注解
在接口方法上添加缓存注解:
@PostMapping("/good/list/page/vo")
@Cacheable(
value = "good_app_page",
key = "T(com.yupi.yuaicodemother.utils.CacheKeyUtils).generateKey(#appQueryRequest)",
condition = "#appQueryRequest.pageNum <= 10"
)
public BaseResponse<Page<AppVO>> listGoodAppVOByPage(@RequestBody AppQueryRequest appQueryRequest) {
// 方法实现保持不变...
}
这里使用了 SpEL(Spring Expression Language)表达式:
T(类名):用于调用静态方法,生成缓存 key
#参数名:用于引用方法参数
condition:设置缓存条件,只有前 10 页才会被缓存
缓存注解的工作原理,执行流程如下:
1. 方法执行前:Spring 根据 key 表达式生成缓存键
2. 缓存检查:检查 Redis 中是否存在该键对应的缓存数据
3. 缓存命中:如果存在且未过期,直接返回缓存数据,不执行方法
4. 缓存未命中:如果不存在,执行方法获取结果,并将结果存储到 Redis 中 5. 返回结果:返回方法执行结果

















 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









