







文章目录
概率算法和近似算法是两种另类算法,概率算法在算法执行中引入随机性,近似算法采用近似方法来解决优化问题,这里介绍它们的特点和基本的算法设计。
12.1 概率算法
12.1.1 什么是概率算法
1. 概率算法的特点
概率算法也叫随机化算法,允许算法在执行过程中随机地选择下一个计算步骤。在很多情况下,算法在执行过程中面临选择时,随机性选择比最优选择省时,因此概率算法可以在很大程度上降低算法的复杂度。
概率算法的基本特征是随机决策,在同一实例上执行两次的结果可能不同,在同一实例上执行两次的时间也可能不同。这种算法的新颖之处是把随机性注入到算法中,使得算法设计与分析的灵活性、及解决问题的能力大为改善,曾一度在密码学、数字信号和大系统的安全及故障容错中得到广泛的应用。
之前讨论的算法的每个计算步骤都是固定的,而概率算法允许算法在执行过程中随机选择下一个计算步骤。概率算法的特点:一是不可再现性,在同一个输入实例上每次执行的结果不尽相同,例如 n n n 皇后问题,概率算法运行不同次、将得到不同的正确解;二是算法分析困难,要求有概率论、统计学和数论的知识。
对概率算法通常讨论以下两种期望时间:
- 平均的期望时间:所有输入实例上,平均的期望执行时间;
- 最坏的期望时间:最坏的输入实例上的期望执行时间。
2. 概率算法的分类
概率算法大致分为以下四类:
- 数值概率算法:常用于数值问题的求解,这类算法所得到的往往是近似解,而且近似解的精度随着计算时间的增加而不断提高。在许多情况下,精确解是不可能的、或没有必要的,因此用数值概率算法可以得到相当满意的解。其特点是用于数值问题的求解,得到最优化问题的近似解。
- 蒙特卡罗
Monte Carlo算法:用蒙特卡罗算法能够求得问题的一个解,但这个解未必是正确的。求得正确解的概率依赖于算法所用的时间。算法所用的时间越多,得到正确解的概率就越高。蒙特卡罗算法的主要缺点就在于此。一般情况下,无法有效判断得到的解是否肯定正确。其特点是判定问题的准确解,得到的解不一定正确(?)。 - 拉斯维加斯
Las Vegas算法:一旦用拉斯维加斯算法找到一个解,那么这个解肯定是正确的,但有时用拉斯维加斯算法可能找不到解。与蒙特卡罗算法类似,「拉斯维加斯算法得到正确解的概率」随着「它耗用的计算时间」的增加而提高。对于所求解问题的任一实例,用同一拉斯维加斯算法反复对该实例求解足够多次,可使求解失效的概率任意小。其特点是不一定会得到解,但得到的解一定是正确解。 - 舍伍德
Sherwood算法:总能求得问题的一个解,且所求得的解总是正确的。当一个确定性算法的最坏时间复杂度与平均时间复杂度存在较大差别时,可以在这个确定算法中引入随机性,将它改造成一个舍伍德算法,消除或减少确定算法中求解问题的好坏实例(确定算法中好实例是指在执行时间性能较好的算法输入,坏实例是指执行时间性能较差的算法输入)之间在执行时间性能上的差别。舍伍德算法的精髓不是避免算法的最坏情况行为,而是设法消除这种最坏行为和特定实例之间的关联性。其特点是总能求得一个解,且一定是正确解。
这里主要讨论后面三种概率算法。
3. 随机数生成器
在概率算法中需要由一个随机数生成器产生随机数序列,以便在算法执行中按照这个随机数序列进行随机选择。可以采用最简单的线性同余法生成随机数序列
a
1
,
…
,
a
n
a_1, \dots , a_n
a1,…,an 。
a
0
=
d
a
n
=
(
b
a
n
−
1
+
c
)
m
o
d
m
n
=
1
,
2
,
…
\begin{aligned} &a_0 = d\\ &a_n = (ba_{n - 1} + c) \bmod m \quad n = 1, 2, \dots \end{aligned}
a0=dan=(ban−1+c)modmn=1,2,… 其中,
b
≥
0
,
c
≥
0
,
d
≤
m
b \ge 0, c \ge 0, d \le m
b≥0,c≥0,d≤m ,
d
d
d 称为随机数生成器的随机种子 random seed(一般不作为随机数序列产生的第一个数,但可以在中间)。
以下程序产生 n n n 个 [ a , b ] [a, b] [a,b] 的随机整数(这种写法在C++中过时了):
#include <bits/stdc++.h>
using namespace std;
void randa(int x[], int n, int a, int b) { // 产生n个[a,b]的随机数
for (int i = 0; i < n; ++i)
x[i] = rand() % (b - a + 1) + a;
}
int main() {
int n = 10, x[10];
int a = 10, b = 30;
srand((unsigned)time(NULL)); // 随机种子
randa(x, n, a, b);
for (int i = 0; i < n; ++i)
printf("%d ", x[i]);
return 0;
}
12.1.2 蒙特卡罗类型概率算法
蒙特卡罗方法又称计算机随机模拟方法,是一种基于“随机数”的计算方法。这一方法源于美国在第二次世界大战中研制原子弹的曼哈顿计划。该计划的主持人之一、数学家冯·诺依曼用驰名世界的赌城——摩纳哥的 Monte Carlo 来命名这种方法。其基本思想其实很早以前就被人们所发现和利用。在七世纪人们就知道,用事件发生的“频率”来决定事件的“概率”,19世纪人们用投针试验的方法来决定
π
\pi
π 。高速计算机的出现,使得用数学方法在计算机上大量模拟这样的试验成为可能。
一个示例是,设计一个求(?还是验证?)圆周率 π \pi π 的蒙特卡罗概率算法。我们在边长为 2 2 2 的正方形内,有一个半径为 1 1 1 的内切圆,如图12.1所示。向该正方形中投掷 n n n 次飞镖,假设飞镖击中正方形中任何位置的概率相同。设飞镖的位置为 ( x , y ) (x, y) (x,y) ,如果有 x 2 + y 2 ≤ 1 x^2 + y^2 \le 1 x2+y2≤1 ,则飞镖落在内切圆中。
这里内切圆面积为 π \pi π ,正方形面积为 4 4 4 ,内切圆面积与正方形面积比为 π 4 \dfrac{\pi} {4} 4π 。若 n n n 次投掷中有 m m m 次落在内切圆中,则内切圆面积与正方形面积之比,可近似为 m / n m / n m/n ,即 π 4 ≈ m n \dfrac{ \pi} {4} \approx \dfrac{m}{n} 4π≈nm ,或者 π ≈ 4 m n \pi \approx \dfrac{4m}{n} π≈n4m 。
由于图中每个象限的概率相同,这里以右上角象限进行模拟。采用蒙特卡罗型概率算法,验证 π \pi π 的程序如下:
#include <bits/stdc++.h>
using namespace std;
int randa(int a, int b) { // 产生一个[a,b]的随机数
return rand() % (b - a + 1) + a;
}
double rand01() { // 产生一个[0,1]的随机数
return (double)rand() / RAND_MAX;
}
double solve() { // 验证pi的蒙特卡罗算法
int n = 100000, m = 0;
double x, y;
for (int i = 1; i <= n; ++i) {
x = rand01(), y = rand01();
if (x * x + y * y <= 1.0)
++m;
}
return 4.0 * m / n;
}
int main() {
srand((unsigned)time(NULL)); // 随机种子
printf("PI=%g\n", solve()); // 输出pi
}
上述程序的每次执行结果可能不同,例如
5
5
5 次执行的输出结果如下。从中看出,每次的执行结果依赖于 rand01() 随机函数。

12.1.3 拉斯维加斯类型概率算法
拉斯维加斯型概率算法不时地做出「可能导致算法陷入僵局的选择」,并且算法能够检测是否陷入僵局,如果是则算法承认失败。这种行为对于一个确定性算法是不能接受的,因为这意味着它不能解决相应的问题实例。但是,拉斯维加斯型概率算法的随机特性可以接受失败,只要这种行为出现的概率不占多数。当出现失败时,只要在相同的输入实例上再次运行概率算法,就又有成功的可能。
这种算法的一个显著特征是,它所做的随机性选择有可能导致算法找不到问题的解,即算法运行一次,或者得到一个正确解、或者无解。因此,需要对同一个输入实例反复多次运行算法,直到成功地获得问题的解。
一个示例是,设计一个求解
n
n
n 皇后问题的拉斯维加斯概率型算法。具体做法是:当在第
i
i
i 行放置一个皇后时,可能的列为
1
∼
n
1 \sim n
1∼n ,产生
1
∼
n
1 \sim n
1∼n 的随机数
j
j
j 作为列号,如果皇后的位置
(
i
,
j
)
(i, j)
(i,j) 发生冲突,就继续产生一个随机数,这样最多试探
n
n
n 次。其中任何一次试探成功(不冲突),则继续查找下一个皇后位置,如果试探超过
n
n
n 次,算法返回 false 。对应的完整程序如下:
#include <bits/stdc++.h>
using namespace std;
const int N = 20; // 最多皇后个数
int q[N]; // 各皇后所在的列号,(i,q[i])为一个皇后位置,存储一个解
int num = 0; // 累计调用次数
void dispASolution(int n) { // 输出n皇后问题的一个解
printf("第%d次运行找到一个解: ", num);
for (int i = 1; i <= n; ++i)
printf("(%d, %d)", i, q[i]);
printf("\n");
}
int randa(int a, int b) { // 产生一个[a,b]区间的随机数
return rand() % (b - a + 1) + a;
}
bool place(int i, int j) { // 测试(i,j)位置能否摆放皇后
if (i == 1) return true; // 第一个皇后总是可以放置
int k = 1;
while (k < i) { // k=1~i-1是已放置了皇后的行
if ((q[k] == j) || (abs(q[k] - j) == abs(i - k)))
return false;
++k;
}
return true;
}
bool queen(int i, int n) { // 放置1~i的皇后
if (i > n) { // 所有皇后放置结束
dispASolution(n);
return true;
} else {
int count = 0, j; // 试探次数累计
while (count < n) { // 最多试探n次
j = randa(1, n); // 产生第i行上1到n列的一个随机数
++count;
if (place(i, j)) // 在第i行上找到一个合适位置(i,j)
break;
}
if (count >= n) return false;
q[i] = j;
return queen(i + 1, n);
}
}
int main() {
int n = 6; // n为皇后个数
printf("%d皇后问题求解如下:\n", n);
srand((unsigned)time(NULL));
while (num < 10) {
if (queen(1, n)) // 找到一个解退出
break;
++num;
printf("第%d次运行没有找到解\n", num);
}
return 0;
}
上述程序中一下执行
10
10
10 次 queen() ,很多次程序的执行都找不到解:
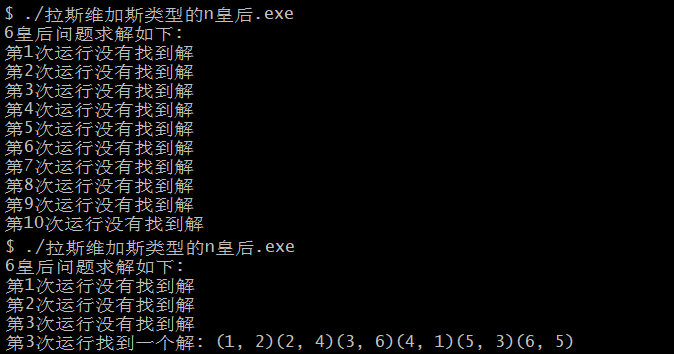
如果将上述随机放置策略与回溯法相结合,则会获得更好的效果。可以先在棋盘的若干行随机地放置相容的皇后,然后在其他行中用回溯法继续放置,直到找到一个解或宣告失败。
12.1.4 舍伍德类型概率算法
在分析确定性算法的平均时间复杂度时,通常假定算法的输入实例满足某一特定的概率分布。事实上,对于不同的输入实例,很多算法的运行时间相差很大,此时可以采用舍伍德型概率算法来消除「算法的时间复杂度与输入实例间的这种联系」。
一个示例是,设计一个快速排序的舍伍德类型概率算法。快排的关键在于一次划分中选择合适的划分基准元素,如果基准是序列中的最小(或最大)元素,则一次划分后得到的两个子序列不均衡,使得快排的时间性能降低。舍伍德型概率算法在一次划分之前,根据随机数在待划分序列中随机确定一个元素作为基准,并把它与第一个元素交换,则一次划分后得到期望均衡的两个子序列,从而使算法的行为不受「待排序序列的不同输入实例」的影响,使快速排序在最坏情况下的时间性能趋近于平均情况的时间性能,即 O ( n log 2 n ) O(n\log_2 n) O(nlog2n) 。
对应的完整程序如下:
#include <bits/stdc++.h>
using namespace std;
void disp(int a[], int n) { // 输出a中的所有元素
for (int i = 0; i < n; ++i)
printf(" %d" + !i, a[i]);
printf("\n");
}
int randa(int a, int b) { // 产生一个[a,b]的随机数
return rand() % (b - a + 1) + a;
}
void swap(int &x, int &y) { // 交换x和y
int tmp = x;
x = y; y = tmp;
}
int Partition(int a[], int s, int t) { // 划分算法
int i = s, j = t;
int tmp = a[s]; // 用序列的第1个元素作为基准
while (i != j) { // 从序列两端交替向中间扫描,直到i=j为止
while (j > i && a[j] >= tmp)
--j; // 从右向左扫描,找第一个关键字<tmp的a[j]
a[i] = a[j]; // 将a[j]前移到a[i]的位置
while (i < j && a[i] <= tmp)
++i; // 从左向右扫描,找第一个关键字>tmp的a[i]
a[j] = a[i];
}
a[i] = tmp;
return i;
}
void QuickSort(int a[], int s, int t) { // 对a[s...t]元素序列进行递增排序
if (s < t) { // 序列内至少存在两个元素的情况
int j = randa(s, t); // 产生[s,t]的随机数j
swap(a[j], a[s]); // 将a[j]作为基准
int i = Partition(a, s, t);
QuickSort(a, s, i - 1); // 对左子序列递归排序
QuickSort(a, i + 1, t); // 对右子序列递归排序
}
}
int main() {
int n = 10;
int a[] = {2, 5, 1, 7, 10, 6, 9, 4, 3, 8};
printf("排序前:"); disp(a, n);
srand((unsigned)time(NULL));
QuickSort(a, 0, n - 1);
printf("排序后:"); disp(a, n);
return 0;
}
运行结果如下所示:

从中看出,舍伍德版的快速排序就是在确定性算法中引入随机性,其优点是计算时间复杂度对所有实例而言相对均匀,但与相应的确定性算法相比,其平均时间复杂度没有改进。
12.2 近似算法
12.2.1 什么是近似算法
近似算法通常与NP问题相关,由于目前不可能采用有效的多项式时间、精确地解决NP问题,所以采用多项式时间求一个次优解。在理想情况下,近似值最优可达到一个小的常数因子(例如,在最优解的
5
%
5\%
5% 以内)。近似算法也越来越多地用于「已知精确多项式时间算法、但由于输入大小而过于昂贵的问题」。
所有已知的解决NP问题的算法,都有指数型运行时间。但是,如果要找一个“好解”、而非最优解,有时候多项式算法是存在的。
给定一个最小化问题和一个近似算法,可以按照如下方法评价算法:首先给出最优解的一个下界,然后把算法的运行结果与这个下界进行比较。对于最大化问题,先给出一个上界,然后把算法的运行结果与这个上界进行比较。
近似算法比较经典的问题有旅行商问题 TSP 、最小顶点覆盖和集合覆盖等。迄今为止,所有的NPC问题都还没有多项式时间算法。
12.2.2 求解旅行商问题的近似算法
本节通过旅行商问题的近似算法,说明近似算法方法。
【问题描述】将求解旅行商问题的图改为带权无向连通图 G ( V , E ) G(V, E) G(V,E) ,其中每一边 ( u , v ) ∈ E (u, v) \in E (u,v)∈E 都有一非负整数费用 c ( u , v ) c(u, v) c(u,v) 。现在要找出 G G G 的最小费用哈密顿回路。
【问题求解】旅行商问题中的费用函数 c c c 具有三角不等式性质,即对任意的 3 3 3 个顶点 u , v , w ∈ V u, v, w\in V u,v,w∈V ,有 c ( u , w ) < c ( u , v ) + c ( v , w ) c(u, w) < c(u, v) + c(v, w) c(u,w)<c(u,v)+c(v,w) 。对于给定的带权无向图 G G G ,可以利用图 G G G 的最小生成树来找近似最优的旅行商问题回路,其过程如下:
void approxTSP(Graph g) {
// 选择g的任一顶点v;
// 用Prim算法找出带权图g的、一棵以v为根的最小生成树tree;
// 从v开始, 对树tree深度优先遍历, 得到顶点表path;
// 将v加到表path的末尾, 按表path中顶点的次序组成哈密顿回路H, 作为计算结果返回
}
// (不是应该先检查是否为哈密顿图吗?)
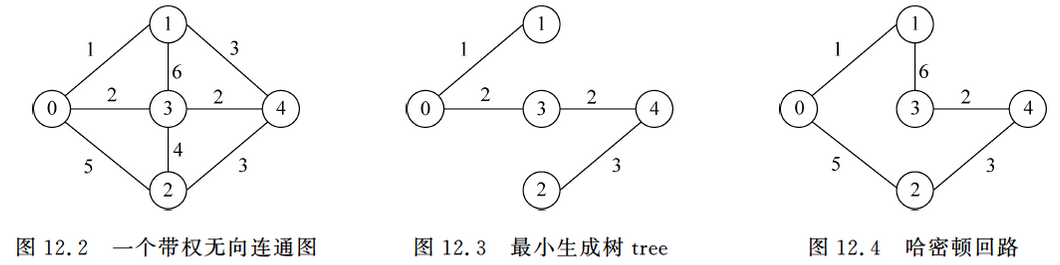
例如,对于如图12.2所示的带权无向连通图,假设顶点 v = 0 v = 0 v=0 ,找近似最优的旅行商问题回路的过程如下:
- 采用
Prim()算法,求出从顶点 v v v 出发产生的最小生成树tree,如图12.3所示。 - 对
tree从顶点 v v v 进行深度优先遍历,得到path = {0, 1, 3, 4, 2}。 - 将
v加到表path的末尾,按表path中顶点的次序组成哈密顿回路 H H H ,如图12.4所示。得到的旅行商问题路径为 0 → 1 → 3 → 4 → 2 → 0 0 \to 1 \to 3 \to 4 \to 2 \to 0 0→1→3→4→2→0 ,路径长度 = 1 + 6 + 2 + 3 + 5 = 17 = 1 + 6 + 2 + 3 + 5 = 17 =1+6+2+3+5=17 。
自然,这个近似解并非最优解,但由于 Prim() 和 DFS 算法的时间复杂度都是多项式级,所以该算法的时间复杂度也是多项式级。实际上可以从每个顶点出发这样求解,通过比较求出最优近似解,其时间复杂度仍然是多项式级的。
#include "Graph.cpp"
#include <bits/stdc++.h>
using namespace std;
// 问题表示
MGraph g; // 图的邻接矩阵
// 求解过程表示
MGraph tree; // 存放最小生成树
bool visited[MAXV];
vector<int> path; // 存放从每个顶点出发得到的近似TSP路径
void Prim(int v) { // 产生最小生成树tree
int lowcost[MAXV];
int closest[MAXV];
for (int i = 0; i < g.n; ++i) { // 初始化lowcost和closest数组
lowcost[i] = g.edges[v][i];
closest[i] = v;
}
for (int i = 1; i < g.n; ++i) { // 找出(n-1)个顶点
int mincost = INF, k;
for (int j = 0; j < g.n; ++j) { // 在(V-U)中找出离U最近的顶点
if (lowcost[j] != 0 && lowcost[j] < mincost) { // lowcost[j]为0或INF都不会算
mincost = lowcost[j];
k = j; // k记录最近顶点的编号
}
}
tree.edges[closest[k]][k] = mincost; // 构建最小生成树的一条无向边
tree.edges[k][closest[k]] = mincost;
lowcost[k] = 0; // 标记k已经加入U
for (int j = 0; j < g.n; ++j) { // 修改数组lowcost和closest
if (g.edges[k][j] != 0 && g.edges[k][j] < lowcost[j]) {
lowcost[j] = g.edges[k][j];
closest[j] = k; // j与k是MST中的邻接点
}
}
}
}
void DFS(int v) { // DFS算法
path.push_back(v); // 被访问顶点添加到path中
visited[v] = true; // 置已访问标记
for (int w = 0; w < tree.n; ++w) // 找顶点v的所有邻接点
if (visited[w] == false && tree.edges[v][w] != 0 && tree.edges[v][w] != INF)
DFS(w); // 找顶点v的未访问过的邻接点w
}
void TSP(int v) { // TSP算法
tree.n = g.n; // 设置生成树的顶点数为图的顶点数
memset(tree.edges, INF, sizeof(tree.edges));
Prim(v);
memset(visited, false, sizeof(visited));
DFS(v);
}
void ApproxTSP() { // 输出TSP问题的近似解
vector<int> minPath; // 存放最优的TSP近似解
int minPathLen = INF;
printf("求解结果\n");
for (int v = 0; v < g.n; ++v) {
path.clear();
TSP(v);
printf("从顶点%d出发查找:\n\t路径: ", v);
int pathLen = 0;
for (int i = 0; i < path.size(); ++i) {
printf("%d->", path[i]);
if (i != path.size() - 1);
pathLen += g.edges[path[i]][path[i +1]];
}
printf("->%d", v);
pathLen += g.edges[path[path.size() - 1]][v];
printf(", 长度=%d\n", pathLen);
if (pathLen > INF)
printf("\t该路径不存在\n");
else if (pathLen < minPathLen) {
minPathLen = pathLen;
minPath = path;
}
}
printf("最优近似解\n\t路径: ");
for (int i = 0; i < minPath.size(); ++i)
printf("%d->", minPath[i]);
printf("->%d", minPath[0]);
printf(", 长度=%d\n", minPathLen);
}
int main() {
int A[][MAXV] = { // 一个带权无向图
{0, 1, 5, 2 INF},
{1, 0, INF, 6, 3},
{5, INF, 0, 4, 3},
{2, 6, 4, 0, 2},
{INF, 3, 3, 2, 0}
};
int n = 5, e = 8;
CreateMat(g, A, n, e); // 创建图的邻接矩阵
ApproxTSP();
return 0;
}
上述程序的执行结果如下:

本例算法找到的恰好是最优解,但在很多情况下不一定会找到问题的最优解。可以通过近似比 approximate ratio 来刻画。若一个最优化问题的最优解为
c
∗
c^*
c∗ ,求解该问题的一个近似最优值为
c
c
c ,则该近似算法的近似比定义如下:
γ
=
max
(
c
c
∗
,
c
∗
c
)
\gamma = \max \Bigg( \dfrac{c}{c^*}, \dfrac{c^*}{c} \Bigg)
γ=max(c∗c,cc∗) 对于一个最大化问题,
c
≤
c
∗
c \le c^*
c≤c∗ ,此时近似比表示最优解
c
∗
c^*
c∗ 比近似最优值
c
c
c 大多少倍;对于一个最下化问题,
c
∗
≤
c
c^* \le c
c∗≤c ,此时近似比表示最优解
c
∗
c^*
c∗ 比近似最优值
c
c
c 小多少倍。所以,
γ
≥
1
\gamma \ge 1
γ≥1 ,其值越大求出的近似解越差。
实际上,近似算法并非适合所有问题的求解,一些问题求近似解和求最优解一样难。
其他问题


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











