







文章目录
7. RSA公钥加密系统
通过一个公钥加密系统 public-key cryptosystem ,我们可以对「在两个通信单位之间传输的消息」进行加密,即使窃听者 eavesdropper 窃听到被加密的消息,也不能对其进行破译。一个公钥加密系统还能让通信的一方,在电子消息的末尾附加一个无法伪造的数字签名 digital signature ——这种签名是纸质文件上的手写签名的电子版本。任何人都可以轻松地核对签名,但却不能伪造它,如果这一消息的任何位有所变化,整个签名就失去了效力。因此,数字签名可以为「签名者的身份和其签署信息的内容」提供证明。
对于电子签署的商业合同、电子支票、电子购货单和其他一些各方希望进行认证的电子信息来说,这是一种理想的工具。
RSA公钥加密系统主要基于以下事实:寻找大素数是很容易的,但要把一个数因子分解为两个大素数的积却相当困难 The RSA public-key cryptosystem relies on the dramatic difference between the ease of finding large prime numbers and the difficulty of factoring the product of two large prime numbers 。(算导31.8节)下面描述了一个能有效地找出大素数的过程,(算导31.9节)讨论大整数的因子分解问题。
7.1 公钥加密系统
在一个公钥加密系统中,每个参与者都拥有一把公钥 public key 和一个私钥 secret key 。每把密钥都是一段信息 Each key is a piece of information 。例如,在RAS加密系统中,每个密钥均由一对整数组成 each key consists of a pair of integers 。在密码学中,常以参与者 Alice 和 Bob 作为例子,用
P
A
,
S
A
P_A, S_A
PA,SA 分别表示 Alice 的公钥和私钥,用
P
B
P_B
PB 和
S
B
S_B
SB 分别表示 Bob 的公钥和私钥。
每个参与者均自己创建公钥和私钥。私钥需要保密,但公钥可以对任何人透漏、甚至公之于众。事实上,我们可以假设,每个参与者的公钥都能在一个公开目录中看到,这样通常是很方便的,这使得任何参与者都可以容易地获得任何其他参与者的公钥。
公钥和私钥指定了可用于任何信息的函数 The public and secret keys specify functions that can be applied to any message 。设
D
D
D 表示允许的信息集合。例如,
D
D
D 可能是所有有限长度的位序列的集合。在最简单的、最原始的公钥加密设想 formulation of publickey cryptography 中,要求公钥与私钥指定「从
D
D
D 到其自身的一一映射 one-to-one functions from D to itself 」。我们用
P
A
(
)
P_A()
PA() 表示「对应 Alice 的公钥
P
A
P_A
PA 的函数」,用
S
A
(
)
S_A()
SA() 表示「对应她的私钥
S
A
S_A
SA 的函数」,因此
P
A
(
)
,
S
A
(
)
P_A(), S_A()
PA(),SA() 函数都是
D
D
D 的排列(?)。我们假定已知密钥
P
A
P_A
PA 或
S
A
S_A
SA ,就可以有效地计算出函数
P
A
(
)
P_A()
PA() 和
S
A
(
)
S_A()
SA() 。
系统中任何参与者的公钥和私钥,都是一个匹配对,它们指定的函数互为反函数,也就是说,对任何消息 M ∈ D M \in D M∈D ,有: M = S A ( P A ( M ) ) (31.35) M = P A ( S A ( M ) ) (31.36) \begin{aligned} M &= S_A(P_A(M)) \qquad \qquad &\textrm{(31.35)} \\ M &= P_A(S_A(M))\qquad \qquad &\textrm{(31.36)} \end{aligned} MM=SA(PA(M))=PA(SA(M))(31.35)(31.36) 无论用哪种次序,运用两把密钥 P A P_A PA 和 S A S_A SA 对 M M M 相继进行变换后,最后仍然得到消息 M M M 。
在一个公钥加密系统中,我们需要:除了 Alice 外,没有人能在任意实用的时间内 any practical amount of time 计算出函数
S
A
(
)
S_A()
SA() 。这一假设十分关键,对于保持「送给 Alice 的加密邮件的保密性」和鉴别「Alice 的数字签名的真实性」而言。Alice 必须保密
S
A
S_A
SA ;如果她不能做到这一点,就会失去她的唯一性,而且加密系统也不能提供给她唯一性 unique capabilities 。假设:即使每个人都知道
P
A
P_A
PA 、并能有效地计算出
P
A
(
)
P_A()
PA() 这一
S
A
(
)
S_A()
SA() 的反函数,依然要保证只有 Alice 能计算出
S
A
(
)
S_A()
SA() 。为了创建一个可行的公钥加密系统,我们必须解决以下问题:如何创建一个系统,在该系统中我们可以公开一个变换
P
A
(
)
P_A()
PA() 、而不至于因此公开如何计算其相应的逆变换
S
A
(
)
S_A()
SA() 。这项任务看起来很难,但我们将看到如何去完成它。
在一个公钥加密系统中,加密的工作方式如图31-5所示。假定 Bob 要给 Alice 发送一条加密消息 M M M ,使得该消息对于窃密者像一串无法识别的乱码。发送消息的方案如下:
- Bob 取得 Alice 的公钥 P P P(根据一个公开的目录,或者直接向 Alice 索取)。
- Bob 计算出相应于
M
M
M 的密文
ciphertextC = P A ( M ) C = P_A(M) C=PA(M) ,并把 C C C 发送给 Alice 。 - 当 Alice 收到密文后,她运用自己的密钥
S
A
S_A
SA 恢复原始信息:
S
A
(
C
)
=
S
A
(
P
A
(
M
)
)
=
M
S_A(C) = S_A(P_A(M)) = M
SA(C)=SA(PA(M))=M 。
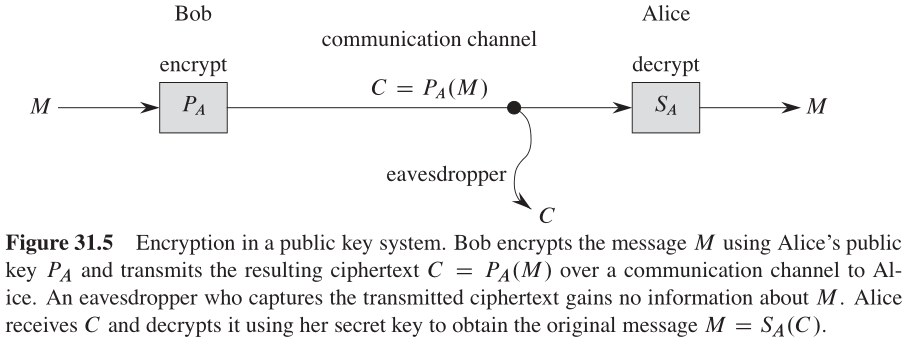
由于 S A ( ) S_A() SA() 和 P A ( ) P_A() PA() 互为反函数,所以 Alice 能从 C C C 中计算出 M M M 。因为只有 Alice 能计算出 S A ( ) S_A() SA() ,所以也只有 Alice 能根据 C C C 计算出 M M M 。因为 BoB 运用 P A ( ) P_A() PA() 对 M M M 进行加密,所以只有 Alice 可以理解接收的信息。
类似地,在公钥加密系统的设想中,我们可以很容易地实现数字签名(有其他方式可以解决构造数字签名的问题,但在这里不讨论)。假设现在 Alice 希望把一个数字签署的响应 M ′ M' M′ 发送给 Bob。数字签名方案的过程如图31-6所示。
-
Alice 使用她的私钥 S A S_A SA 和等式 σ = S A ( M ′ ) \sigma = S_A(M') σ=SA(M′) 计算出信息 M ′ M' M′ 的数字签名 σ \sigma σ 。
-
Alice 把信息/签名对 ( M ′ , σ ) (M', \sigma) (M′,σ) 发送给 Bob 。
-
当 Bob 收到 ( M ′ , σ ) (M', \sigma) (M′,σ) 时,他可以利用 Alice 的公钥、通过验证等式 M ′ = P A ( σ ) M' = P_A(\sigma) M′=PA(σ) 来证实,该消息确实是来自于 Alice 。这里假设 M ′ M' M′ 包含 Alice 的名字,这样 Bob 就知道应该使用谁的公钥。如果等式成立,则 Bob 可以得出结论:消息 M ′ M' M′ 确实是由 Alice 签名的;如果等式不成立,则 Bob 可以得出结论:要么是信息 M ′ M' M′ 或数字签名 σ \sigma σ 因传输错误而损坏,要么信息/签名对 ( M ′ , σ ) (M', \sigma) (M′,σ) 是一个故意的伪造。
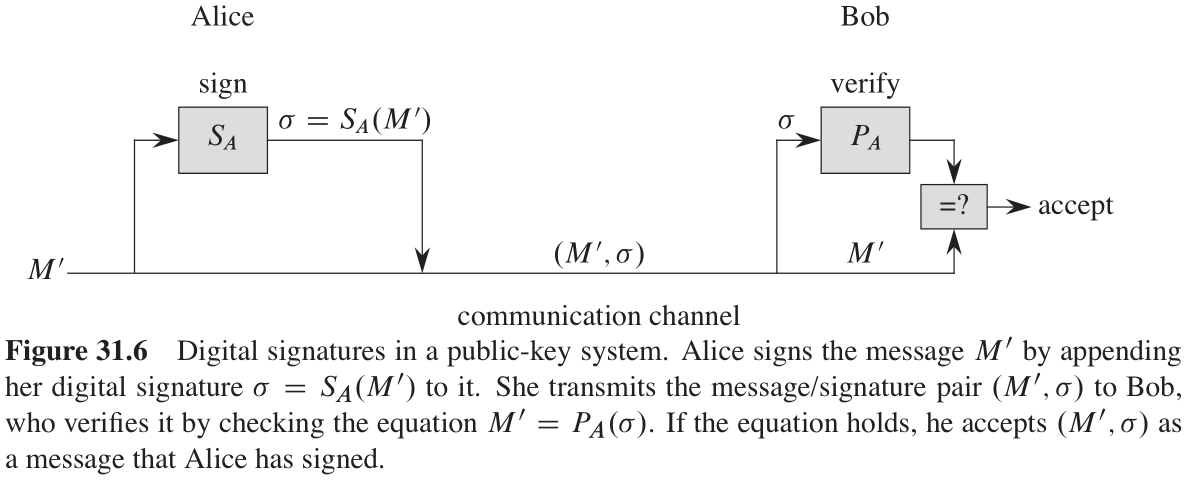
因为一个数字签名既证明了签署者的身份,也证明了签署信息的内容,所以它是对「文件末尾的手写签名」的一种模拟。
一个数字签名必须能被「任何能取得签署者的公钥的人」所验证。一条签署过的消息可以被一方确认后,再传送到其他可以验证签名的各方。例如,这条消息可能是 Alice 发给 Bob 的一张电子支票,在 Bob 确认了支票上 Alice 的签名后,就可以把这张支票送交银行,而银行也可以对签名进行验证,然后调拨相应的资金。
一条签署过的信息不必是加密的,该信息可以是公开的、没有受到保护。如果把上述有关加密和签名的两种方案结合起来使用,就可以创建出同时被签署和加密的消息 messages that are both signed and encrypted :
- 签署者首先把其数字签名(用私钥)附加在消息的后面,然后再用「他预定的接收者的公钥」,对最终的消息/签名对进行加密,从而发送消息;
- 接收者用其私钥对收到的消息进行解密,以同时获取原始消息和数字签名;
- 然后,接收者可以用「签署者的公钥」对签名进行验证。
- 相应的纸质文件系统的实现过程为:对文件签名后,将文件封入一个纸质信封内,该信封只能由预定的接收者打开。
7.2 RSA加密系统
在RSA公钥加密系统中,一个参与者按下列过程创建他的公钥和私钥:
- 随机选取两个大素数 p , q p, q p,q ,使得 p ≠ q p \ne q p=q 。例如,素数 p , q p, q p,q 可能各有 1024 1024 1024 位。
- 计算 n = p q n = pq n=pq 。
- 选取一个与 ϕ ( n ) \phi(n) ϕ(n) 互质的小奇数 e e e ,其中由等式 ( 31.20 ) (31.20) (31.20) , ϕ ( n ) = n ∏ p : p i s p r i m e a n d p ∣ n ( 1 − 1 p ) = p q ( 1 − 1 p ) ( 1 − 1 q ) = ( p − 1 ) ( q − 1 ) \phi(n) = n \prod_{\mathrm{ p\ :\ p\ is\ prime\ and\ p \mid n}} (1 - \dfrac{1}{p}) =pq(1- \dfrac{1}{p}) ( 1- \dfrac{1}{q}) = (p - 1)(q - 1) ϕ(n)=n∏p : p is prime and p∣n(1−p1)=pq(1−p1)(1−q1)=(p−1)(q−1) 。
- (利用算导31.4节中的方法)计算出 e e e 的模 ϕ ( n ) \phi(n) ϕ(n) 乘法逆元 d d d 的值(推论31.26保证 d d d 存在且唯一——给定 e , ϕ ( n ) e, \phi(n) e,ϕ(n) ,当 g c d ( e , ϕ ( n ) ) = 1 gcd(e, \phi(n)) = 1 gcd(e,ϕ(n))=1 即二者互质时, e d ≡ 1 ( m o d ϕ ( n ) ) e d \equiv 1 \pmod {\phi(n)} ed≡1(modϕ(n)) 有唯一解, d d d 为 e e e 的乘法逆元)。
- 将对 P = ( e , n ) P = (e, n) P=(e,n) 公开,并作为参与者的RSA公钥。
- 使对 S = ( d , n ) S = (d, n) S=(d,n) 保密,并作为参与者的RSA私钥。
对于这个方案,域 D D D 为集合 Z n \Z_n Zn 。为了变换与公钥 P = ( e , n ) P = (e, n) P=(e,n) 相关的消息 M M M ,计算: P ( M ) = M e m o d n (31.37) P(M) = M^e \bmod n \tag{31.37} P(M)=Memodn(31.37) 为了变换与私钥 S = ( d , n ) S = (d, n) S=(d,n) 相关的密文 C C C ,计算: S ( C ) = C d m o d n (31.38) S(C) = C^d \bmod n \tag{31.38} S(C)=Cdmodn(31.38)
这两个等式对加密与签名是通用的 These equations apply to both encryption and signatures 。只是为了创建一个签名,签署人将其私钥应用于待签署的消息、而不是一个密文中;为了确认签名,将签署人的公钥应用在签名中、而非待加密的消息中。
我们可以运用31.6节中描述的过程 MODULAR-EXPONENTIATION 、来实现上述公钥与私钥的有关操作。为了分析这些操作的运行时间,假定公钥
(
e
,
n
)
(e, n)
(e,n) 和私钥
(
d
,
n
)
(d, n)
(d,n) 满足
log
e
=
O
(
1
)
,
log
d
≤
β
,
log
n
≤
β
\log e = O(1), \log d \le \beta, \log n \le \beta
loge=O(1),logd≤β,logn≤β(
e
e
e 为小奇数,
d
d
d 为
e
e
e 模
ϕ
(
n
)
\phi(n)
ϕ(n) 的乘法逆元,
n
=
p
q
n = pq
n=pq 为大素数乘积)。然后,应用公钥需要执行
O
(
1
)
O(1)
O(1) 次模乘法运算、使用
O
(
β
2
)
O(\beta^2)
O(β2) 次位操作,应用密钥需要执行
O
(
β
)
O(\beta)
O(β) 次模乘法操作、使用
O
(
β
3
)
O(\beta^3)
O(β3) 次位操作。
定理31.36(RSA的正确性)RSA等式
(
31.37
)
(31.37)
(31.37) 和
(
31.38
)
(31.38)
(31.38) 定义了满足等式
(
31.35
)
(31.35)
(31.35) 和
(
31.36
)
(31.36)
(31.36) 的逆变换。
证明:根据等式
(
31.37
)
(31.37)
(31.37) 和
(
31.38
)
(31.38)
(31.38) ,对任意
M
∈
Z
n
M \in \Z_n
M∈Zn ,有:
P
(
S
(
M
)
)
=
S
(
P
(
M
)
)
=
M
e
d
m
o
d
n
P(S(M)) = S(P(M)) = M^{ed} \bmod n
P(S(M))=S(P(M))=Medmodn 因为
e
,
d
e, d
e,d 是模
ϕ
(
n
)
=
(
p
−
1
)
(
q
−
1
)
\phi(n) = (p-1)(q-1)
ϕ(n)=(p−1)(q−1) 的乘法逆元,所以对某个整数
k
k
k ,有:
e
d
=
1
+
k
(
p
−
1
)
(
q
−
1
)
ed = 1 + k(p - 1)(q - 1)
ed=1+k(p−1)(q−1) 但是,如果
M
≡
0
(
m
o
d
p
)
M \cancel {\equiv}\ 0 \pmod p
M≡
0(modp) ,则有:
M
e
d
≡
M
(
M
p
−
1
)
k
(
q
−
1
)
(
m
o
d
p
)
≡
M
(
(
M
m
o
d
p
)
p
−
1
)
k
(
q
−
1
)
(
m
o
d
p
)
≡
M
(
1
)
k
(
q
−
1
)
(
m
o
d
p
)
(
根
据
定
理
31.31
费
马
小
定
理
)
≡
M
(
m
o
d
p
)
\begin{aligned}M^{ed} &\equiv M(M^{p - 1} ) ^{k (q - 1) } &\pmod p \\ &\equiv M((M \bmod p)^{p-1})^{k(q - 1)} &\pmod p \\ &\equiv M(1)^{k(q-1)} &\pmod p &\quad (根据定理31.31费马小定理) \\ &\equiv M &\pmod p \end{aligned}
Med≡M(Mp−1)k(q−1)≡M((Mmodp)p−1)k(q−1)≡M(1)k(q−1)≡M(modp)(modp)(modp)(modp)(根据定理31.31费马小定理)
类似地,对所有 M M M 有: M e d ≡ M ( m o d q ) M^{ed} \equiv M \pmod q Med≡M(modq) 因此,根据中国余数定理的推论31.29,对所有 M M M ,有: M e d ≡ M m o d n ■ M^{ed} \equiv M \bmod n\qquad \qquad \blacksquare Med≡Mmodn■
RSA加密系统的安全性,主要来源于「对大整数进行因式分解的困难性」。如果对手能对公钥中的模数 n n n 进行分解,就可以根据公钥推导出私钥,这是因为对方和公钥创建者以同样的方式使用因子 p , q p, q p,q 。因此,如果能轻易地分解大整数,也就能够轻易地打破RSA加密系统。这一命题的逆命题是,如果分解大整数是困难的,则打破RSA也是困难的。经过二十年的研究,人们还没有发现比因子分解模 n n n 更容易的方法来打破RSA加密系统。并且正如我们将(在算导31.9节中)所见,对大整数进行因子分解的困难程度令人惊异。通过随机地选取两个 1024 1024 1024 位的素数、并将其相乘,就可以创建出一把无法用现行技术、在可行的时间内“破解”的公钥。在数论算法的设计方法还缺乏根本突破的情况下,细心地遵循所推荐标准来实现,RSA加密系统可以为实际应用提供高度的安全性。
然而,为了通过RSA加密系统实现安全性,应该在很长(数百位乃至千位)的整数上操作、以防御因子分解技术可能的进步。2009年,RSA模数通常是在 768 ∼ 2048 768 \sim 2048 768∼2048 位的范围内,要建立这样大小的模数,必须能够有效地找出大素数。(算导31.8节)下面将讨论这个问题。
为了效率,通常运用一种“混合的”或“密钥管理”模式的RSA、来实现快速的无公钥加密系统 non-public-key cryptosystem 。在这样一个系统中,加密密钥和解密密钥是相同的。如果 Alice 希望私下给 Bob 发送一条长信息
M
M
M ,她从快速无公钥加密系统中选取一把随机密钥
K
K
K ,然后运用
K
K
K 对
M
M
M 进行加密,得到密文
C
C
C 。这里
C
C
C 和
M
M
M 一样长,但
K
K
K 相当短。然后,她利用 Bob 的公开RSA密钥对
K
K
K 进行加密,因为
K
K
K 很短,所以计算
P
B
(
K
)
P_B(K)
PB(K) 的速度也很快(比计算
P
B
(
M
)
P_B(M)
PB(M) 的速度快很多)。接着,她把
(
C
,
P
B
(
K
)
)
(C, P_B(K))
(C,PB(K)) 传送给 Bob ,Bob 对
P
B
(
K
)
P_B(K)
PB(K) 解密后得到
K
K
K ,再用
K
K
K 对
C
C
C 进行解密,得到
M
M
M 。
类似地,可以使用一种混合的方法来提高数字签名的执行效率。在这种方法中,将RSA与一个公开的抗冲突散列函数 collision-resistant hash function
h
h
h 相结合,这个函数是易于计算的,但是对这个函数来说,要找出两条消息
M
M
M 和
M
′
M'
M′ 、使得
h
(
M
)
=
h
(
M
′
)
h(M) = h(M')
h(M)=h(M′) ,在计算上是不可行的。
h
(
M
)
h(M)
h(M) 的值是消息
M
M
M 的一个短(如
256
256
256 位)“指纹”。如果 Alice 希望签署一条消息
M
M
M ,她首先把函数
h
h
h 作用于
M
M
M 得到指纹
h
(
M
)
h(M)
h(M) ,然后用她的私钥加密
h
(
M
)
h(M)
h(M) 。她将
(
M
,
S
A
(
h
(
M
)
)
(M, S_A(h(M))
(M,SA(h(M)) 作为她签署的
M
M
M 的版本发送给 Bob 。而 Bob 可以通过计算
h
(
M
)
h(M)
h(M) ,并将
P
A
P_A
PA 应用于收到的
S
A
(
h
(
M
)
)
S_A(h(M))
SA(h(M)) 、验证其是否等于
h
(
M
)
h(M)
h(M) 来验证签名的真实性。因为没有人能够创建出两条具有相同指纹的消息,所以在计算上不可能既改变签署的消息、又保持签名的合法性。
最后,我们注意到,利用证书 certificates 可以更轻松地分配公钥。例如,假设存在一个“可信的权威”
T
T
T ,每个人都知道他的公钥。Alice 可以从
T
T
T 获取一条签署的消息(即她的证书),该消息声明“Alice 的公钥是
P
A
P_A
PA ”。由于每个人都知道
P
T
P_{T}
PT ,所以这个证书是“自我认证”。Alice 可以将她的证书包含在签名信息中,使得接收者可以立即得到 Alice 的公钥、以验证她的签名。因为她的密钥是被
T
T
T 签署的,所以接收者知道 Alice 的密钥确实是 Alice 本人的密钥。
8. 素数的测试
在本节中,我们要考虑寻找大素数的问题。首先讨论素数的密度,接着讨论一种似乎可行、但不完全可行的测试素数的方法,然后介绍一种由 Miller 和 Rabin 发现的、有效的随机素数测试算法。
8.1 素数的密度
在许多应用领域,如密码学中,需要找出大的“随机”素数。幸运的是,大素数并不少,因此测试适当大小的随机整数、直到找到素数的过程是可行的。素数分布函数 prime distribution function
π
(
n
)
\pi(n)
π(n) 描述了:小于或等于
n
n
n 的素数的数目。例如
π
(
10
)
=
4
\pi(10) = 4
π(10)=4 ,因为小于等于
10
10
10 的素数有
4
4
4 个,分布为
2
,
3
,
5
,
7
2, 3, 5, 7
2,3,5,7 。素数定理给出了
π
(
n
)
\pi(n)
π(n) 的一个有用近似。
定理31.37(素数定理 Prime number theorem )
lim
n
→
∞
π
(
n
)
n
/
ln
n
=
1
■
\lim_{n \to \infin} \dfrac{\pi(n)}{ n / \ln n} = 1\qquad \qquad \blacksquare
n→∞limn/lnnπ(n)=1■
即使对于较小的 n n n ,近似计算式 n / ln n n / \ln n n/lnn 也可以相当精确地给出 ϕ ( n ) \phi(n) ϕ(n) 的估计值。例如,当 n = 1 0 9 n = 10^9 n=109 时, π ( n ) = 50 , 847 , 534 , n / ln ( n ) = 48 , 254 , 942 \pi(n) = 50,847,534,\ n / \ln(n) = 48,254,942 π(n)=50,847,534, n/ln(n)=48,254,942 ,误差不超过 6 % 6\% 6% 。对数论研究者来说, 1 0 9 10^9 109 是一个小数字。
我们可以把「随机选取一个整数
n
n
n 、并判断它是否为素数」这一过程视作一个伯努利试验 Bernoulli trail(见算导C.4节)。通过素数定理,一次成功(即一个随机选取的整数
n
n
n 是素数)的概率为
1
ln
n
\dfrac{1}{\ln n}
lnn1 。这种几何分布告诉我们,为了获取一次成功、我们需要多少次试验,而由于等式
(
C
.
32
)
(C.32)
(C.32) ,试验的期望值近似为
ln
n
\ln n
lnn 。因此,为了找出一个长度与
n
n
n 相同的素数 find a prime that is of the same length as n ,要检查在
n
n
n 附近随机选取的
ln
n
\ln n
lnn 个整数。例如,我们期望:为了找出一个
1024-bit
\textrm{1024-bit}
1024-bit 的素数,大约需要测试
ln
2
1024
≈
710
\ln 2^{1024} \approx 710
ln21024≈710 个随机选取的、
1024
1024
1024 位长的整数的素性。当然,通过只选择奇数,就可以把这个数字减少一半。
在本节其余部分,将要考虑这个问题:确定一个大奇数
n
n
n 是否为素数。为了表示上的方便,我们假设
n
n
n 具有下列素数分解因子:
n
=
p
1
e
1
p
2
e
2
…
p
r
e
r
(31.39)
n = p_1^{e_1} p_2^{e_2} \dots p_r^{e_r} \tag{31.39}
n=p1e1p2e2…prer(31.39) 这里
r
≥
1
r \ge 1
r≥1 ,
p
1
,
p
2
,
…
,
p
r
p_1, p_2, \dots, p_r
p1,p2,…,pr 是
n
n
n 的素数因子,且
e
1
,
e
2
,
…
,
e
r
e_1, e_2, \dots, e_r
e1,e2,…,er 是正整数。
n
n
n 是素数当且仅当
r
=
1
r = 1
r=1 且
e
1
=
1
e_1 = 1
e1=1 时(即只有一个素数分解因子,且就是
n
n
n 本身时)。
解决这个素数测试问题的一种简便方法是试除 trial division ——试着用每个整数
2
,
3
,
…
,
⌊
n
⌋
2, 3, \dots, \lfloor \sqrt{n} \rfloor
2,3,…,⌊n⌋ 分别去除
n
n
n(大于
2
2
2 的偶数可以跳过;即不用偶数来除,或极端点只用素数来除)。很容易看出来,
n
n
n 是素数当且仅当没有一个试除数能整除
n
n
n 。假定每次试除需要常数时间,则最坏情况运行时间是
Θ
(
n
)
=
Θ
(
n
1
/
2
)
\Theta(\sqrt{n}) =\Theta(n^{1/2})
Θ(n)=Θ(n1/2) ,这是
n
n
n 的长度的指数 which is exponential in the length of n(如果
n
n
n 表示为
β
\beta
β 位的二进制数,则
β
=
⌈
log
(
n
+
1
)
⌉
\beta = \lceil \log (n + 1) \rceil
β=⌈log(n+1)⌉ ,因此
n
=
Θ
(
2
β
/
2
)
\sqrt{n} = \Theta(2^{\beta / 2})
n=Θ(2β/2) )。因此,只有当
n
n
n 很小或
n
n
n 恰好有小素数因子时,试除法才能较好地进行。当试除法可以执行时,它的优点是:不仅能确定
n
n
n 是素数还是合数、而且当
n
n
n 是合数时它能确定出
n
n
n 的一个素数因子。
在本节中,我们感兴趣的仅仅是:确定一个给定的数 n n n 是否是素数;如果 n n n 是合数,我们不考虑找出其素数因子。正如将在(算导31.9节中)看到的那样,计算一个数的素数因子分解的计算开销是很高的。令人惊讶的是,确定一个数是否是素数,要比确定一个合适的素因子分解容易得多。
8.2 伪素数测试过程
现在来考察一种“几乎可行”的素数测试方法 primality testing ,事实上对于很多实际应用,这种方法已经足够好了。后面还将改进这种方法,以消除其中的小缺陷。令
Z
n
+
\Z^+_n
Zn+ 表示
Z
n
\Z_n
Zn 中的非零元素:
Z
n
+
=
{
1
,
2
,
…
,
n
−
1
}
\Z_n^+ = \{ 1, 2, \dots, n - 1\}
Zn+={1,2,…,n−1} 如果
n
n
n 是素数,则
Z
n
+
=
Z
n
∗
\Z_n^+ = \Z^*_n
Zn+=Zn∗ 。
我们称
n
n
n 是一个基于
a
a
a 的伪素数 base-a pseudoprime ,如果
n
n
n 是一个合数,且
a
n
−
1
≡
1
(
m
o
d
n
)
(31.40)
a^{n - 1} \equiv 1 \pmod n \tag{31.40}
an−1≡1(modn)(31.40) 费马小定理(定理31.31)意味着:如果
n
n
n 是素数,则对
Z
n
+
\Z^+_n
Zn+(如上所述,
n
n
n 是素数时
Z
n
+
=
Z
n
∗
\Z_n^+ = \Z^*_n
Zn+=Zn∗ )中的每个
a
a
a ,
n
n
n 都满足等式
(
31.40
)
(31.40)
(31.40) 。因此,如果能找出任一
a
∈
Z
n
+
a \in \Z^+_n
a∈Zn+ 、使得
n
n
n 不满足等式
(
31.40
)
(31.40)
(31.40) ,那么
n
n
n 就当然是合数(费马小定理的逆否命题)。令人惊讶的是,费马小定理的逆命题也几乎成立(对
Z
n
+
\Z^+_n
Zn+ 中的每个
a
a
a ,
n
n
n 都满足等式
(
31.40
)
(31.40)
(31.40) ,则
n
n
n 是素数)——对于素数测试,这一标准几乎是完美的。我们对
a
=
2
a = 2
a=2 ,测试看
n
n
n 是否满足等式
(
31.40
)
(31.40)
(31.40) ,如果不满足,则通过返回 COMPOSITE 声明
n
n
n 是合数(根据费马小定理的逆否命题);否则返回 PRIME ,猜测
n
n
n 是素数(实际上,此时我们所知道的只是
n
n
n 或者是素数、或者是基于
2
2
2 的伪素数)。
下列过程就是用这种方法测试
n
n
n 的素性。它使用了(算导31.6节中的)MODULAR-EXPONENTIATION 过程。假设输入
n
n
n 是一个大于
2
2
2 的整数。

这个过程可能会产生错误,但是只有一种类型——也就是说,如果它判定
n
n
n 是合数,那么结果总是正确的;然而,如果它判定
n
n
n 是素数,那么只有当
n
n
n 是基于
2
2
2 的伪素数时、过程才会出错。
这个过程出错的概率有多大?令人惊讶地少。在小于 10000 10000 10000 的 n n n 值中,只有在其中 22 22 22 个值上会产生错误。最靠前的四个这样的值分别为 341 , 561 , 645 , 1105 341, 561, 645, 1105 341,561,645,1105(基于 2 2 2 的伪素数)。我们不证明它,但是当 β → ∞ \beta \to \infin β→∞ 时该过程对随机选取的 β \beta β 位数进行测试,错误的概率趋近于 0 0 0 。根据 Pomerance 那样、更精确地估计一个给定规模下「基于 2 2 2 的伪素数的个数」,我们可以估计出:
- 被上述过程判定为素数的、一个随机选取的 512 512 512 位数,是「基于 2 2 2 的伪素数」的概率不到 1 / 1 0 20 1 / 10^{20} 1/1020 ;
- 被上述过程判定为素数的、一个随机选取的 1024 1024 1024 位数,是基于 2 2 2 的伪素数的概率不到 1 / 1 0 41 1 / 10^{41} 1/1041 。
因此,如果只是尝试为某个应用找到一个大素数,通过随机选取大的数字、直到它们其中之一使得 PSEUDOPRIME 返回 PRIME ,这在所有实际使用中几乎永远不会出错。但是当「待测试素性的数字」不是随机选取时,我们需要一个更好的方法来进行素数测试。后面将会看到,如果稍微巧妙一点、再加上一些随机性,就会得到一个在所有输入情况下、都工作良好的素数测试程序。
遗憾的是,我们不能通过简单地选取另外一个基数(例如 a = 3 a = 3 a=3 )检查等式 ( 31.40 ) (31.40) (31.40) 的方法、来消除所有的错误,因为总存在正整数 n n n(称为 Carmichael 数)对所有 a ∈ Z n ∗ a \in \Z^*_n a∈Zn∗ 满足等式 ( 31.40 ) (31.40) (31.40) ——(我们注意到,当 g c d ( a , n ) > 1 gcd(a, n) > 1 gcd(a,n)>1 也就是当 a ∉ Z n ∗ a \notin \Z^*_n a∈/Zn∗ 时,等式 ( 31.40 ) (31.40) (31.40) 不成立,但是我们希望解释:如果 n n n 只有大素数因子、其他数都和 n n n 互质时,就很难通过寻找这样的 a a a 来说明 n n n 是合数)。前三个 Carmichael 数是 561 , 1105 , 1729 561, 1105, 1729 561,1105,1729 。Carmichael 数极少;例如,在小于 100 , 000 , 000 100, 000, 000 100,000,000 的数中,只有 255 255 255 个 Carmichael 数。(算导练习31.8-2)解释了这种数很少的原因。
下一步来说明,如何对素数测试方法进行改进,使得测试过程不会被 Carmichael 数欺骗。
8.3 Miller-Rabin 随机化素性测试
Miller-Rabin 素性测试方法对简单测试过程 PSEUDOPRIME 做了两点改进,克服了其中存在的问题:
- 它试验了多个随机选取的基值 n n n ,而非仅仅一个基值。
- 当计算每个模取幂的值时,在最后一组平方中
during the final set of squarings.,它寻找一个 1 1 1 的模 n n n 非平凡平方根。如果发现一个,终止执行并输出结果COMPOSITE。(算导31.6节的推论31.35证明了用这种方法测试合数的正确性)
Miller-Rabin 素性测试的伪代码如下。输入 n > 2 n > 2 n>2 是一个等待素性测试的奇数, s s s 是「从 Z n + \Z^+_n Zn+ 中随机选取的、要进行试验的基值」的个数。
- 代码运用随机数生成程序
RANDOM,RANDOM(1, n - 1)返回一个满足 1 ≤ a ≤ n − 1 1 \le a \le n -1 1≤a≤n−1 的随机选取的整数 a a a 。 - 代码中还使用一个辅助过程
WITNESS,WITNESS(a, n) = true当且仅当 a a a 是「 n n n 为合数的一个证据」时——即用 a a a 来证明(证明方法见后面) n n n 为合数是可能的。测试WITNESS(a, n)是一个对「作为过程PSEUDOPRIME基础(用 a = 2 a = 2 a=2 )的测试 a n − 1 ≡ 1 ( m o d n ) a^{n - 1} \cancel {\equiv }\ 1 \pmod n an−1≡ 1(modn) 」的扩展,但是更加有效。

我们首先介绍并证明 WITNESS 的构造过程,然后展示如何把它应用于 Miller-Rabin 素性测试过程。
- 令 n − 1 = 2 t u n - 1 = 2^t u n−1=2tu ,其中 t ≥ 1 t \ge 1 t≥1 且 u u u 是奇数;即 n − 1 n - 1 n−1 的二进制表示是「奇整数 u u u 的二进制表示后面跟上恰好 t t t 个零」。因此, a n − 1 ≡ ( a u ) 2 t ( m o d n ) a^{n - 1} \equiv (a^u)^{2^t} \pmod n an−1≡(au)2t(modn) ,所以可以通过先计算 a u m o d n a^u \bmod n aumodn ,然后对结果连续平方 t t t 次来计算 a n − 1 m o d n a^{n - 1} \bmod n an−1modn 。
WITNESS的伪代码,通过首先在第二行计算值 x 0 = a u m o d n x_0 = a^u \bmod n x0=aumodn 、然后在第三至六行 for 循环中的一行中对结果平方 t t t 次,来计算 a n − 1 m o d n a^{n - 1} \bmod n an−1modn 。通过在 i i i 上归纳,被计算出的序列 x 0 , x 1 , … , x i x_0, x_1, \dots, x_i x0,x1,…,xi 的值满足等式 x i ≡ a 2 i u ( m o d n ) ( i = 0 , 1 , … , t ) x_i \equiv a^{{2^i}u} \pmod n\ (i =0,1,\dots, t) xi≡a2iu(modn) (i=0,1,…,t) ,所以特别地, x t ≡ a 2 t u ( m o d n ) x_t \equiv a^{2^t u} \pmod n xt≡a2tu(modn) 。- 然而,在第四行后执行一个平方步骤,如果第五至六行检测到一个
1
1
1 的非平凡平方根刚被发现,则循环可能提前结束(稍后解释)。如果这样,则算法终止并返回
TRUE。 - 如果
x
≡
a
n
−
1
(
m
o
d
n
)
x\equiv a^{n - 1} \pmod n
x≡an−1(modn) 所计算出的值不等于
1
1
1 ,则第七至八行返回
TRUE,就像PSEUDOPRIME在这种情况中返回COMPOSITE。 - 如果第六行或第八行没有返回
TRUE,则第九行返回FALSE。
我们现在来论证,如果 WITNESS(a, n) 返回 TRUE ,则可以用
a
a
a 作为证据、构造出
n
n
n 是合数的证明。
- 如果
WITNESS从第八行返回TRUE,则它已经发现 x t = a n − 1 m o d n ≠ 1 x_t = a^{n - 1} \bmod n \ne 1 xt=an−1modn=1 。然而,如果 n n n 是素数,则根据费马小定理(定理31.31),对任何 a ∈ Z n + a \in \Z^+_n a∈Zn+(当 n n n 为素数,则 Z n + = Z n ∗ \Z_n^+ = \Z_n^* Zn+=Zn∗ )都有 a n − 1 ≡ 1 ( m o d n ) a^{n - 1} \equiv 1 \pmod n an−1≡1(modn) 成立。因此 n n n 不可能为素数,并且等式 a n − 1 m o d n ≠ 1 a^{n - 1} \bmod n \ne 1 an−1modn=1 证明了这个事实。 - 如果
WITNESS从第六行返回TRUE,则它已经发现 x i − 1 x_{i-1} xi−1 是一个 1 1 1 的以 n n n 为模的非平凡平方根,因为 x i − 1 ≠ ± 1 ( m o d n ) x_{i - 1} \ne \pm 1\pmod n xi−1=±1(modn) ,但是 x i ≡ x i − 1 2 ≡ 1 ( m o d n ) x_i \equiv x_{i-1}^2 \equiv 1 \pmod n xi≡xi−12≡1(modn) 。推论31.35说明,仅当 n n n 是合数时,才能存在 1 1 1 的以 n n n 为模的非平凡平方根,因此说明 x i − 1 x_{i - 1} xi−1 是一个 1 1 1 的模 n n n 非平凡平方根,也就证明了 n n n 是合数。
- 这样就完成了有关
WITNESS正确性的证明。如果调用WITNESS(a, n)返回TRUE,则 n n n 必为合数——证据 a a a 、以及程序返回TRUE的原因(它是从第六行、还是第八行返回?),为 n n n 是合数提供了一个证明。
在这里,我们简短地展示 WITNESS 的行为的另一种描述,将 WITNESS 作为一个序列
X
=
⟨
x
0
,
x
1
,
…
,
x
t
⟩
X = \langle x_0, x_1, \dots, x_t\rangle
X=⟨x0,x1,…,xt⟩ 的函数,稍后在分析 Miller-Rabin 素数测试的效率时,会发现它很有用。注意,如果对某个
0
≤
i
<
t
0 \le i < t
0≤i<t 有
x
i
=
1
x_i = 1
xi=1 ,则 WITNESS 可能不会计算序列的余下部分。然而如果计算,则
x
i
+
1
,
x
i
+
2
,
…
,
x
t
x_{i + 1}, x_{i + 2}, \dots, x_t
xi+1,xi+2,…,xt 的值都将是
1
1
1 ,并且我们考虑序列
X
X
X 中的这些位置都是
1
1
1 。我们有四种情况:
-
X
=
⟨
…
,
d
⟩
X = \langle \dots,\ d\rangle
X=⟨…, d⟩ ,其中
d
≠
1
d \ne 1
d=1 :序列
1
1
1 不是以
1
1
1 结尾。从第八行返回
TRUE; a a a 是 n n n 为合数的一个证据(由费马小定理) ; -
X
=
⟨
1
,
1
,
…
,
1
⟩
X= \langle 1,\ 1,\ \dots,\ 1 \rangle
X=⟨1, 1, …, 1⟩ :序列
X
X
X 全都是
1
1
1 。返回
FALSE, a a a 不是 n n n 为合数的证据。 -
X
=
⟨
…
,
−
1
,
1
,
…
,
1
⟩
X = \langle \dots,\ -1,\ 1,\ \dots,\ 1 \rangle
X=⟨…, −1, 1, …, 1⟩ :序列
X
X
X 以
1
1
1 结尾,而且最后一个非
1
1
1 的数等于
−
1
-1
−1 。返回
FALSE, a a a 不是 n n n 为合数的证据。 -
X
=
⟨
…
,
d
,
1
,
…
,
1
⟩
X = \langle \dots,\ d,\ 1,\ \dots,\ 1 \rangle
X=⟨…, d, 1, …, 1⟩ ,其中
d
≠
±
1
d \ne \pm 1
d=±1 :序列
X
X
X 以
1
1
1 结尾,但最后一个非
1
1
1 的数不是
−
1
-1
−1 。返回
TRUE; a a a 是 n n n 为合数的证据,因为 d d d 是一个 1 1 1 的非平凡平方根。
我们现在检验使用了 WITNESS 的 MILLER-RABIN 素性测试。再一次,假设
n
n
n 是一个大于
2
2
2 的奇数。

过程 MILLER-RABIN 是为了「证明
n
n
n 是合数」所进行的概率性搜索。主循环(从第一行开始)从
Z
n
+
\Z^+_n
Zn+ 中挑选
s
s
s 个
a
a
a 的随机值(第二行)。
- 如果所挑选的一个
a
a
a 值是
n
n
n 为合数的证据,则过程
MILLER-RABIN在第四行返回COMPOSITE。这样的结果总是正确的,由WITNESS的正确性证明可以看出。 - 如果在
s
s
s 次试验中没有发现证据,则
MILLER-RABIN假定这是因为证据不存在,因此假设 n n n 为素数。我们将看到,如果 s s s 足够大,则这个输出结果很可能是正确的,但也存在这样一种微小的可能性,即过程在选择 a a a 时运气不佳,虽然过程没有发现证据,但证据确实存在。
为了说明 MILLER-RABIN 的操作过程,令
n
n
n 为 Carmichael 数
561
561
561 ,使得
n
−
1
=
560
=
2
4
⋅
35
n - 1 = 560 = 2^4 \cdot 35
n−1=560=24⋅35 ,于是
t
=
4
,
u
=
35
t = 4, u =35
t=4,u=35 。假定过程选择
a
=
7
a = 7
a=7 作为基,则(算导31.6节的)图31-4说明 WITNESS 计算
x
0
≡
a
35
≡
241
(
m
o
d
561
)
x_0 \equiv a^{35} \equiv 241 \pmod {561}
x0≡a35≡241(mod561) ,因此计算序列
X
=
⟨
241
,
298
,
166
,
67
,
1
⟩
X = \langle 241, 298, 166, 67, 1 \rangle
X=⟨241,298,166,67,1⟩ 。所以,在最后一次平方步骤中发现了一个
1
1
1 的非平凡平方根,因为
a
280
≡
67
(
m
o
d
n
)
,
a
560
≡
1
(
m
o
d
n
)
a^{280} \equiv 67 \pmod n,\ a^{560} \equiv 1 \pmod n
a280≡67(modn), a560≡1(modn) 。因此,
a
=
7
a = 7
a=7 是
n
n
n 为合数的一个证据,WITNESS(7, n) 返回 TRUE ,因而 MILLER-RABIN 返回 COMPOSITE 。
如果
n
n
n 是一个
β
\beta
β 位数,则 MILLER-RABIN 需要执行
O
(
s
β
)
O(s\beta)
O(sβ) 次算术运算和
O
(
s
β
3
)
O(s \beta^3)
O(sβ3) 次位操作,因为从渐近意义上说,它需要执行的工作仅是
s
s
s 次模取幂运算。
8.4 Miller-Rabin 素性测试的出错率
如果 MILLER-RABIN 返回 PRIME ,则它仍有一种很小的可能性会产生错误。然而,不像 PSEUDOPRIME ,出错的可能性并不依赖于
n
n
n ;对该过程而言,也不存在坏的输入。相反,它取决于
s
s
s 的大小和在选取基值
a
a
a 时“抽签的运气”。另外,由于每次测试都比「简单地检查等式
(
31.40
)
(31.40)
(31.40) 」更严格,因此从总的原则上,对随机选取的整数
n
n
n ,其出错率应该是很小的。下列定理阐述了一个更精确的论点。
定理31.38 如果
n
n
n 是一个奇合数,则
n
n
n 为合数的证据的数目至少为
n
−
1
2
\dfrac{n-1}{2}
2n−1 。
证明:证明过程说明了非证据的个数最多为
n
−
1
2
\dfrac{n - 1}{2}
2n−1 ,这蕴含着定理成立。
首先我们断言,任何非证据都必须是
Z
n
∗
\Z^*_n
Zn∗ 的一个成员。为什么呢?考虑任意的非证据
a
a
a ,它必须满足
a
n
−
1
≡
1
(
m
o
d
n
)
a^{n-1} \equiv 1 \pmod n
an−1≡1(modn) ,或者等价地
a
⋅
a
n
−
2
≡
1
(
m
o
d
n
)
a \cdot a^{n - 2} \equiv 1 \pmod n
a⋅an−2≡1(modn) 。因此,方程
a
x
≡
1
(
m
o
d
n
)
ax \equiv 1\pmod n
ax≡1(modn) 有一个解,即
a
n
−
2
a^{n - 2}
an−2 。由推论31.21可知,
g
c
d
(
a
,
n
)
∣
1
gcd(a, n) \mid 1
gcd(a,n)∣1 ,这反过来蕴含着
g
c
d
(
a
,
n
)
=
1
gcd(a, n) = 1
gcd(a,n)=1 。因此,
a
a
a 是
Z
n
∗
\Z^*_n
Zn∗ 的一个成员,所有的非证据都属于
Z
n
∗
\Z^*_n
Zn∗ 。
为了完成证明,要说明:所有的非证据不仅都被包含在
Z
n
∗
\Z^*_n
Zn∗ 中,而且它们都被包含在
Z
n
∗
\Z^*_n
Zn∗ 的一个真子群
B
B
B 中(回顾:如果
B
B
B 是
Z
n
∗
\Z^*_n
Zn∗ 的一个子群、但
B
≠
Z
n
∗
B \ne \Z^*_n
B=Zn∗ ,则
B
B
B 是
Z
n
∗
\Z^*_n
Zn∗ 的一个真子群)。根据推论31.16,有
∣
B
∣
≤
∣
Z
n
∗
∣
/
2
|B| \le | \Z^*_n | / 2
∣B∣≤∣Zn∗∣/2 。因为
∣
Z
n
∗
∣
≤
n
−
1
|\Z^*_n| \le n - 1
∣Zn∗∣≤n−1 ,所以得到
∣
B
∣
≤
(
n
−
1
)
/
2
|B| \le (n - 1) / 2
∣B∣≤(n−1)/2 。因此,非证据的个数至多是
(
n
−
1
)
/
2
(n - 1) / 2
(n−1)/2 ,所以证据的个数必须至少有
(
n
−
1
)
/
2
(n - 1) / 2
(n−1)/2 。下面说明,如何找出一个「
Z
n
∗
\Z^*_n
Zn∗ 的包含所有非证据的真子群
B
B
B 」。具体分为两种情况。
情况一:存在一个 x ∈ Z n ∗ x \in \Z^*_n x∈Zn∗ ,使得: x n − 1 ≡ 1 ( m o d n ) x^{n - 1} \cancel{\equiv}\ 1 \pmod n xn−1≡ 1(modn) 即, n n n 不是一个 Carmichael 数。如我们先前注意到的,因为 Carmichael 数极少,情况一是由“实际”所产生的主要情况(例如,这里 n n n 已经被随机选取,而且在被测试其素性)。
令 B = { b ∈ Z n ∗ ∣ b n − 1 ≡ 1 ( m o d n ) } B= \{ b \in \Z^*_n \mid b^{n - 1} \equiv 1 \pmod n \} B={b∈Zn∗∣bn−1≡1(modn)} 。显然, B B B 是非空的,因为 1 ∈ B 1 \in B 1∈B 。因为 B B B 在模 n n n 的乘法下是封闭的,所以由定理31.14, B B B 是 Z n ∗ \Z^*_n Zn∗ 的一个子群。注意,每个非证据都属于 B B B ,因为一个非证据 a a a 满足 a n − 1 ≡ 1 ( m o d n ) a^{n - 1} \equiv 1 \pmod n an−1≡1(modn) 。因为 x ∈ Z n ∗ − B x \in \Z^*_n - B x∈Zn∗−B ,所以 B B B 是 Z n ∗ \Z^*_n Zn∗ 的一个真子群。
情况二:对所有的 z ∈ Z n ∗ z \in \Z^*_n z∈Zn∗ , x n − 1 ≡ 1 ( m o d n ) (31.41) x^{n - 1} \equiv 1 \pmod n \tag{31.41} xn−1≡1(modn)(31.41) 即 n n n 是一个 Carmichael 数。这种情况实际上非常少。然而,正如现在要说明的,Miller-Rabin 测试(不同于伪素数测试)可以有效地确定 Carmichael 数是合数。
在这种情况下, n n n 不可能是一个素数幂。为了明白为什么,反之我们假设 n = p e n = p^e n=pe ,其中 p p p 是一个素数, e > 1 e > 1 e>1 ,按如下方式推出矛盾。因为 n n n 假设是奇数,所以 p p p 也必须是奇数。定理31.32蕴含 Z n ∗ \Z^*_n Zn∗ 是一个循环群:它包含一个生成元 g g g ,使得 o r d n ( g ) = ∣ Z n ∗ ∣ = ϕ ( n ) = p e ( 1 − 1 / p ) = ( p − 1 ) p e − 1 ord_n(g) = | \Z^*_n | = \phi(n) = p^e(1 - 1/ p) = (p - 1)p^{e - 1} ordn(g)=∣Zn∗∣=ϕ(n)=pe(1−1/p)=(p−1)pe−1( ϕ ( n ) \phi(n) ϕ(n) 的公式来自于等式 ( 31.20 ) (31.20) (31.20) )。根据式 ( 31.41 ) (31.41) (31.41) ,有 g n − 1 ≡ 1 ( m o d n ) g^{n - 1} \equiv 1 \pmod n gn−1≡1(modn) 。则离散对数定理(定理31.33,取 y = 0 y =0 y=0 )蕴含着 n − 1 ≡ 0 ( m o d ϕ ( n ) ) n - 1\equiv 0 \pmod { \phi(n) } n−1≡0(modϕ(n)) ,或者: ( p − 1 ) p e − 1 ∣ p e − 1 (p - 1) p^{e - 1} \mid p^e - 1 (p−1)pe−1∣pe−1 这对 e > 1 e > 1 e>1 是一个矛盾,因为 ( p − 1 ) p e − 1 (p - 1) p^{e - 1} (p−1)pe−1 可以被素数 p p p 整除,但是 p e − 1 p^e - 1 pe−1 不能(?)。因此, n n n 不是一个素数幂。
因为奇合数 n n n 不是一个素数幂,我们把它分解为一个积 n 1 n 2 n_1n_2 n1n2 ,其中 n 1 , n 2 n_1, n_2 n1,n2 都是大于 1 1 1 的奇数、且互质(有多种方法来做这个分解,选择哪一种并没有关系。例如,如果 n = p 1 e 1 p 2 e 2 … p r e r n = p_1^{e_1} p_2^{e_2} \dots p_r^{e_r} n=p1e1p2e2…prer ,则可以选择 n 1 = p 1 e 1 , n 2 = p 2 e 2 p 3 e 3 … p r e r n_1 = p_1^{e_1},\ n_2 = p_2^{e_2} p_3^{e_3} \dots p_r^{e_r} n1=p1e1, n2=p2e2p3e3…prer )。
回顾一下,定义
t
,
u
t ,u
t,u 使得
n
−
1
=
2
t
u
n - 1 = 2^t u
n−1=2tu ,其中
t
≥
1
t \ge 1
t≥1 、
u
u
u 是奇数,且对于输入
a
a
a ,过程 WITNESS 计算序列:
X
=
⟨
a
u
,
a
2
u
,
a
2
2
u
,
…
,
a
2
t
u
⟩
X = \langle a^u, a^{2u}, a^{2^2 u} , \dots, a^{2^t u} \rangle
X=⟨au,a2u,a22u,…,a2tu⟩ (所有的计算都是根据模
n
n
n 计算的)。
如果
v
∈
Z
n
∗
,
j
∈
{
0
,
1
,
…
,
t
}
v \in \Z^*_n,\ j \in \{ 0, 1, \dots, t\}
v∈Zn∗, j∈{0,1,…,t} 且
v
2
j
u
≡
−
1
(
m
o
d
n
)
v^{2^j u} \equiv -1 \pmod n
v2ju≡−1(modn) ,则称整数对
(
v
,
j
)
(v, j)
(v,j) 为可接受的 acceptable 。可接受的对是肯定存在的,因为
u
u
u 是奇数;我们能选择
v
=
n
−
1
,
j
=
0
v = n - 1,\ j = 0
v=n−1, j=0 ,使得
(
n
−
1
,
0
)
(n - 1, 0)
(n−1,0) 是一个可接受对。现在挑选最大可能的
j
j
j 使得存在一个可接受对
(
v
,
j
)
(v, j)
(v,j) ,并调整
v
v
v 使得
(
v
,
j
)
(v, j)
(v,j) 是一个可接受对。令:
B
=
{
x
∈
Z
n
∗
∣
x
2
j
u
≡
±
1
(
m
o
d
n
)
}
B = \{ x \in \Z^*_n \mid x^{2^j u} \equiv \pm 1\pmod n\}
B={x∈Zn∗∣x2ju≡±1(modn)}
因为
B
B
B 在模
n
n
n 的乘法下是封闭的,故它是
Z
n
∗
\Z^*_n
Zn∗ 的一个子群。因此由定理31.15,
∣
B
∣
|B|
∣B∣ 整除
∣
Z
n
∗
∣
| \Z^*_n |
∣Zn∗∣ 。每个非证据都必定是
B
B
B 的成员,因为由一个非证据产生的序列
X
X
X 必须或全为
1
1
1 、或在第
j
j
j 个位置及之前包含一个
−
1
-1
−1(根据
j
j
j 的最大性 maximality )(如果
(
a
,
j
′
)
(a, j')
(a,j′) 是可接受的,其中
a
a
a 是一个非证据,根据我们选择
j
j
j 的方式,我们必有
j
′
≤
j
j' \le j
j′≤j )。
我们现在,利用 v v v 的存在性说明,存在一个 w ∈ Z n ∗ − B w \in \Z^*_n - B w∈Zn∗−B ,且因此 B B B 是 Z n ∗ \Z^*_n Zn∗ 的一个子群。因为 v 2 j u ≡ − 1 ( m o d n ) v^{2^j u} \equiv -1 \pmod n v2ju≡−1(modn) ,根据中国余数定理的推论31.29,有 v 2 j u ≡ − 1 ( m o d n 1 ) v^{2^j u} \equiv -1 \pmod {n_1} v2ju≡−1(modn1) 。根据推论31.28,存在一个 w w w ,同时满足 w ≡ v ( m o d n 1 ) w ≡ 1 ( m o d n 2 ) w \equiv v \pmod {n_1} \\ w \equiv 1 \pmod {n_2} w≡v(modn1)w≡1(modn2)
因此, w 2 j u ≡ − 1 ( m o d n 1 ) w 2 j u ≡ 1 ( m o d n 2 ) \begin{aligned}w^{2^j u} &\equiv -1 &\pmod {n_1 } \\ w^{2^j u } &\equiv 1 &\pmod{ n_2 }\end{aligned} w2juw2ju≡−1≡1(modn1)(modn2)
由推论31.29, w 2 j u ≡ 1 ( m o d n 1 ) w^{2^j u}\ \cancel{\equiv}\ 1 \pmod {n_1} w2ju ≡ 1(modn1) 蕴含着 w 2 j u ≡ 1 ( m o d n ) w^{2^j u}\ \cancel{\equiv}\ 1 \pmod n w2ju ≡ 1(modn) ,而且 w 2 j u ≡ − 1 ( m o d n 2 ) w^{2^j u }\ \cancel{\equiv}\ -1 \pmod {n_2} w2ju ≡ −1(modn2) 蕴含着 w 2 j u ≡ − 1 ( m o d n ) w^{2^j u }\ \cancel{\equiv}\ -1 \pmod n w2ju ≡ −1(modn) 。因此,得到结论: w 2 j u ≡ ± 1 ( m o d n ) w^{2^j u} \ \cancel{\equiv} \ \pm 1\pmod n w2ju ≡ ±1(modn) ,所以 w ∉ B w \notin B w∈/B 。
接下来还要证明 w ∈ Z n ∗ w \in \Z^*_n w∈Zn∗ 。首先分别对模 n 1 n_1 n1 和模 n 2 n_2 n2 进行处理。对模 n 1 n_1 n1 ,注意到因为 v ∈ Z n ∗ v \in \Z^*_n v∈Zn∗ ,有 g c d ( v , n ) = 1 gcd(v, n) = 1 gcd(v,n)=1 ;如果 v v v 与 n n n 没有任何公约数,它当然不会与 n 1 n_1 n1 有任何公约数。因为 w ≡ v ( m o d n 1 ) w \equiv v\pmod {n_1} w≡v(modn1) ,我们看到 g c d ( w , n 1 ) = 1 gcd(w, n_1 ) = 1 gcd(w,n1)=1 。对模 n 2 n_2 n2 ,观察到 w ≡ 1 ( m o d n 2 ) w \equiv 1 \pmod {n_2} w≡1(modn2) 蕴含着 g c d ( w , n 2 ) = 1 gcd(w, n_2) = 1 gcd(w,n2)=1 。结合这些结果,利用定理31.6,这蕴含着 g c d ( w , n 1 n 2 ) = g c d ( w , n ) = 1 gcd(w, n_1 n_2) = gcd(w, n) = 1 gcd(w,n1n2)=gcd(w,n)=1 。也就是 w ∈ Z n ∗ w \in \Z^*_n w∈Zn∗ 。
因此 w ∈ Z n ∗ − B w \in \Z^*_n - B w∈Zn∗−B ,而且以 B B B 是 Z n ∗ \Z^*_n Zn∗ 的一个真子群的结论,完成情况二。
在两种情况中的任何一个,我们发现, n n n 为合数的证据的数目都至少为 ( n − 1 ) / 2 (n - 1)/2 (n−1)/2 。 ■ \blacksquare ■
定理31.39 对于任意奇数
n
>
2
n > 2
n>2 和正整数
s
s
s ,MILLER-RABIN(n, s) 出错的概率至多为
2
−
s
2^{-s}
2−s 。
证明:利用定理31.38,可以看到如果
n
n
n 是合数,则每次执行第
1
∼
4
1 \sim 4
1∼4 行的 for 循环,发现
n
n
n 为合数的证据的概率至少为
1
/
2
1 / 2
1/2 。只有当 MILLER-RABIN 运气太差,在主循环总共
s
s
s 次迭代中,每一次都没能发现
n
n
n 为合数的证据时,过程才会出错。而这种每次都错过发现证据 such a sequence of misses 的概率至多为
2
−
s
2^{-s}
2−s 。
■
\blacksquare
■
如果
n
n
n 是素数,MILLER-RABIN 总是输出 PRIME ,而如果
n
n
n 是合数,MILLER-RABIN 输出 PRIME 的概率至多为
2
−
s
2^{-s}
2−s 。
然而,对于一个大随机整数使用 MILLER-RABIN 时,为了正确解释 MILLER-RABIN 的结果,我们需要考虑
n
n
n 是素数的优先概率。假设固定一个位长度
β
\beta
β ,并随机选择了一个长度为
β
\beta
β 位的整数来检测素性。令
A
A
A 表示
n
n
n 是素数的事件。由素数定理(定理31.37),
n
n
n 是素数的概率接近:
P
r
(
A
)
≈
1
ln
n
≈
1.443
β
Pr(A) \approx \dfrac{1}{\ln n} \approx \dfrac{1.443} { \beta}
Pr(A)≈lnn1≈β1.443
现在,令
B
B
B 表示 MILLER-RABIN 返回 PRIME 的事件,我们有
P
r
(
B
‾
∣
A
)
=
0
Pr( \overline{B} \mid A) = 0
Pr(B∣A)=0(或者等价地
P
r
(
B
∣
A
)
=
1
Pr(B \mid A ) =1
Pr(B∣A)=1 )和
P
r
(
B
∣
A
‾
)
≤
2
−
s
Pr(B \mid \overline {A})\le 2^{-s}
Pr(B∣A)≤2−s(或者等价地
P
r
(
B
‾
∣
A
‾
)
>
1
−
2
−
s
Pr( \overline {B} \mid \overline{A} ) > 1 - 2^{-s}
Pr(B∣A)>1−2−s )。但是,在 MILLER-RABIN 返回 PRIME 的情况下,
n
n
n 是素数的概率
P
r
(
A
∣
B
)
Pr(A \mid B)
Pr(A∣B) 是多少呢?通过贝叶斯定理 Bayes's theorem 的变形(算导等式
C
.
18
C.18
C.18 ),有:
P
r
(
A
∣
B
)
=
P
r
(
A
)
P
r
(
B
∣
A
)
P
r
(
A
)
P
r
(
B
∣
A
)
+
P
r
(
A
‾
)
P
r
(
B
∣
A
‾
)
≈
1
1
+
2
−
s
(
ln
n
−
1
)
Pr(A \mid B) = \dfrac{ Pr(A) Pr(B \mid A) } { Pr(A) Pr(B \mid A) + Pr( \overline {A} ) Pr(B \mid \overline {A} ) } \approx \dfrac{1}{ 1+ 2^{-s} (\ln n - 1)}
Pr(A∣B)=Pr(A)Pr(B∣A)+Pr(A)Pr(B∣A)Pr(A)Pr(B∣A)≈1+2−s(lnn−1)1
在
s
s
s 超过
log
(
ln
n
−
1
)
\log (\ln n - 1)
log(lnn−1) 之前,这个概率不超过
1
/
2
1 / 2
1/2 。直观上,为了得到信心(由于不能找到
n
n
n 是合数的证据),来克服「对于
n
n
n 是合数的优先偏好 the prior bias in favor of n being composite 」,我们需要很多次初始测试。对于一个有
β
=
1024
\beta = 1024
β=1024 位的数,初始测试大概需要
log
(
ln
n
−
1
)
≈
log
(
β
/
1.443
)
≈
9
\log ( \ln n - 1)\approx \log (\beta / 1.443) \approx 9
log(lnn−1)≈log(β/1.443)≈9 次。在任何情况下,对几乎所有可以想象到的应用,选取
s
=
50
s = 50
s=50 应该是足够的。
事实上,情况要更好。如果我们尝试通过对随机选取的大奇整数应用 MILLER-RABIN 来找出大素数,则选取较小的
s
s
s 值(如
3
3
3 )也是相当程度上不太可能导致错误的结论(在此不做证明)。原因是,对一个随机选取的奇合数
n
n
n ,
n
n
n 为合数的非证据的预计数目可能要比
(
n
−
1
)
/
2
(n - 1) / 2
(n−1)/2 少得多。
然而,如果整数 n n n 不是随机选取的,则运用改进版本的定理31.38,所能证明的最佳结论是非证据的数目至多为 ( n − 1 ) / 4 (n - 1) /4 (n−1)/4 。并且,确实存在整数 n n n 、使得非证据的数目就是 ( n − 1 ) / 4 (n - 1)/ 4 (n−1)/4 。
9. 整数的因子分解
假设希望将一个整数 n n n 进行因子分解,也就是分解为素数的积。通过上一节讨论的素数测试,可以知道 n n n 是否为合数,但它并不能指出 n n n 的素数因子。对一个大整数 n n n 进行因子分解,似乎要比仅确定 n n n 是素数还是合数要困难得多。即使用当今的超级计算机和现行的最佳算法,要对任意一个 1024 1024 1024 位的数进行因子分解也还是不可行的。
9.1 Pollard 的 rho 启发式方法
对小于等于
R
R
R 的所有整数进行试除,保证完全获得小于等于
R
2
R^2
R2 的任意数的因子分解。下列过程 POLLARD-RHO 用相同的工作量,就能对小于等于
R
4
R^4
R4 的任意整数进行因子分解(除非运气不佳)。由于该过程仅仅是一种启发性方法,因此既不能保证其运行时间、也不能保证其运行成功,尽管该过程在实际应用中非常有效。POLLARD-RHO 过程的另一个优点是,它只使用常量的存储空间(如果愿意,可以很容易在计算机上实现 POLLARD-RHO 、找出小整数的因子)。
其执行过程如下。第一至二行把
i
i
i 初始化为
1
1
1 ,把
x
1
x_1
x1 初始化为
Z
n
\Z_n
Zn 中一个随机选取的值、第五行开始的 while 循环将一直进行迭代来搜索
n
n
n 的因子。在 while 循环的每一次迭代中,第七行使用递归式:
x
i
=
(
x
i
−
1
2
−
1
)
m
o
d
n
(31.43)
x_i = (x_{i - 1} ^ 2 - 1) \bmod n \tag{31.43}
xi=(xi−12−1)modn(31.43) 计算无穷序列
x
1
,
x
2
,
x
3
,
x
4
,
…
(31.44)
x_1, x_2, x_3, x_4, \dots \tag{31.44}
x1,x2,x3,x4,…(31.44) 中
x
i
x_i
xi 的下一个值,其中
i
i
i 的值在第六行中进行相应的自增。为了清楚,伪代码使用了下标变量
x
i
x_i
xi ,但即使去掉了所有的下标,程序也以同样的方式执行,因为仅需要保留最近计算出的
x
i
x_i
xi 值。经过这个修改,此过程只使用了一个常量的存储空间。

程序不时地把最近计算出的
x
i
x_i
xi 的值存入变量
y
y
y 中。具体来说,存储的值是那些下标为
2
2
2 的幂的变量:
x
1
,
x
2
,
x
4
,
x
8
,
x
16
,
…
x_1, x_2, x_4, x_8, x_{16}, \dots
x1,x2,x4,x8,x16,… 第三行保存至
x
1
x_1
x1 ,每当
i
=
k
i = k
i=k 时第
12
12
12 行就保存值
x
k
x_k
xk ,并且每当第
12
12
12 行更新
y
y
y 、第十三行就将
k
k
k 的值加倍。因此,
k
k
k 的值序列为
1
,
2
,
4
,
8
,
…
1, 2, 4, 8, \dots
1,2,4,8,… ,并且总是给出要存入
y
y
y 的下一个
x
k
x_k
xk 的下标。
第八到十行尝试用「存入 y y y 的值和 x i x_i xi 的当前值」找出 n n n 的一个因子。特别地,第八行计算出最大公约数 d = g c d ( y − x i , n ) d = gcd(y - x_i, n) d=gcd(y−xi,n) 。如果第九行中发现了 d d d 是 n n n 的非平凡约数,则第十行输出 d d d 的值。
最初,这一寻找因子分解的过程似乎有点神秘,但是注意,POLLARD-RHO 绝不会输出错误的答案;它输出的任何数都是
n
n
n 的一个非平凡约数。尽管 POLLARD-RHO 可能不输出任何信息,也没有保证它能输出约数。不过我们将看到,我们有充足的理由预计:POLLARD-RHO 在 while 循环大约执行
Θ
(
p
)
\Theta( \sqrt{ p})
Θ(p) 次迭代后,会输出
n
n
n 的一个因子
p
p
p 。因此,如果
n
n
n 是合数,我们可以期望这个过程在经过大约
n
1
/
4
n^{1/4}
n1/4 次的更新后,找出足够多的约数来完全因子分解
n
n
n ,这是由于除了可能有的最大的一个素因子外、
n
n
n 的每个素因子
p
p
p 都小于
n
\sqrt{n}
n 。
9.2 算法分析
我们分析一下,要经过多久一个模
n
n
n 的随机序列中才会重复出现一个值,就可以了解这个过程的性能。由于
Z
n
\Z_n
Zn 是有限的,并且序列
(
31.44
)
(31.44)
(31.44) 中的每个值仅仅取决于前一个值,所以序列
(
31.44
)
(31.44)
(31.44) 最终将产生自身重复。一旦我们达到一个
x
i
x_i
xi ,它满足对某个
j
<
i
j < i
j<i 有
x
i
=
x
j
x_i = x_j
xi=xj ,则我们处在一个回路中,因为
x
i
+
1
=
x
j
+
1
x_{i + 1} = x_{j + 1}
xi+1=xj+1 ,
x
i
+
2
=
x
j
+
2
x_{i + 2} = x_{j + 2}
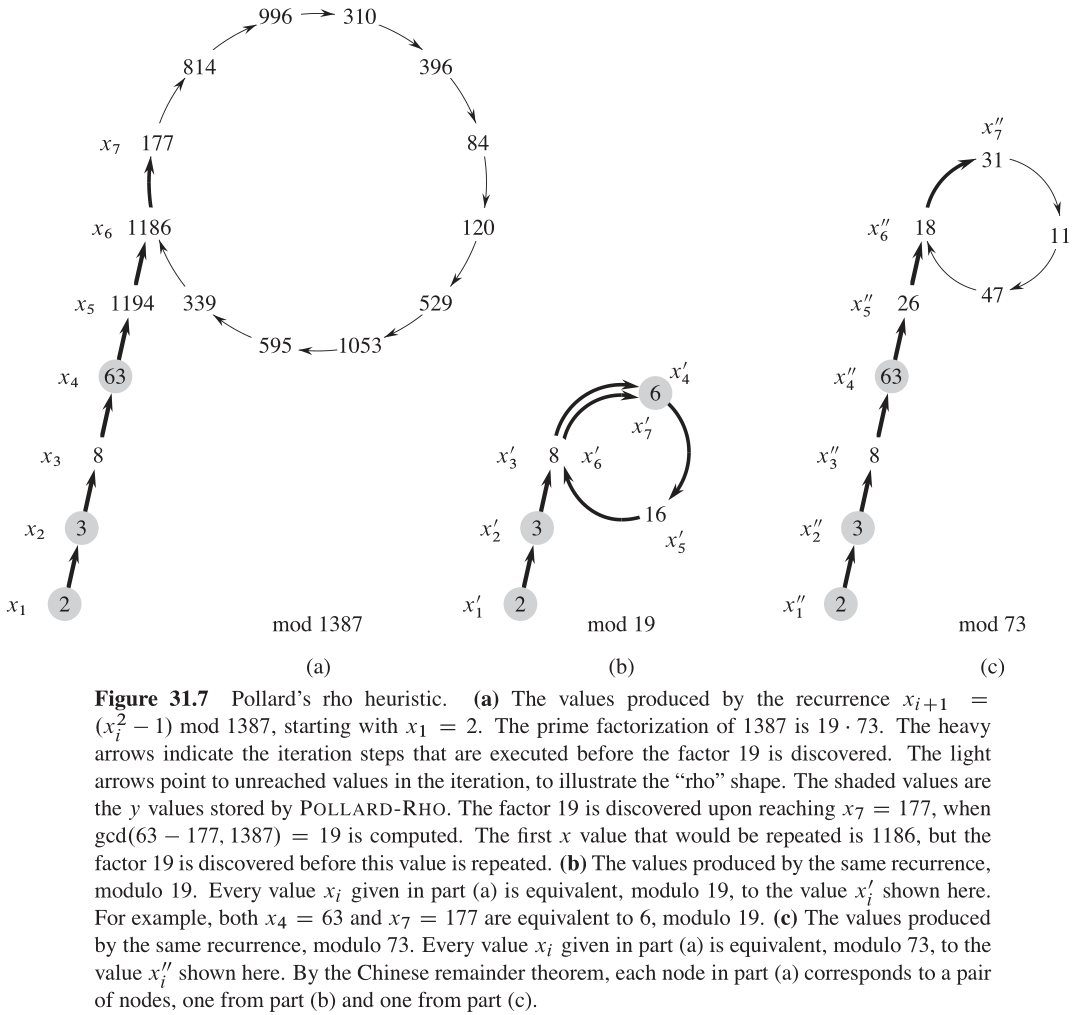
xi+2=xj+2 等等。该过程取名为 rho 启发式方法的原因就在于(如图31-7所示)序列
x
1
,
x
2
,
…
,
x
j
−
1
x_1, x_2, \dots, x_{j - 1}
x1,x2,…,xj−1 可以画成
ρ
\rho
ρ 的尾,而回路
x
j
,
x
j
+
1
,
…
,
x
i
x_j, x_{j + 1}, \dots, x_i
xj,xj+1,…,xi 可以画成
ρ
\rho
ρ 的“体”。
下面考虑一个问题:
x
i
x_i
xi 的序列发生重复需要多久?实际上,这个问题的答案并不是我们恰好需要的,但我们将在后面看到如何修改这个论点。为了进行估算,假定函数:
f
n
(
x
)
=
(
x
2
−
1
)
m
o
d
n
f_n(x)= (x^2 - 1) \bmod n
fn(x)=(x2−1)modn 像一个随机函数那样进行计算,当然它并不是一个真正的随机函数,但由这个假设所得的结论、与我们对 POLLARD-RHO 行为的观察是一致的。我们然后将每个
x
i
x_i
xi 视为「根据
Z
n
\Z_n
Zn 上的一个均匀分布」从
Z
n
\Z_n
Zn 中独立选取的。根据(算导5.4.1节中)对生日悖论的分析,在序列出现回路之前期望要执行的步数为
Θ
(
n
)
\Theta(\sqrt{n})
Θ(n) 。
现在根据要求进行适当修改。令 p p p 是满足 g c d ( p , n / p ) = 1 gcd(p, n / p)= 1 gcd(p,n/p)=1 的 n n n 的一个非平凡因子。例如,如果 n n n 的因子分解为 n = p 1 e 1 p 2 e 2 … p r e r n = p_1^{e_1} p_2^{e_2} \dots p_r^{e_r} n=p1e1p2e2…prer ,则可以取 p p p 的值为 p 1 e 1 p_1^{e_1} p1e1(如果 e 1 = 1 e_1 = 1 e1=1 ,则 p p p 就是 n n n 的最小素数因子,这是一个好的例子、可以牢记)。
序列
⟨
x
i
⟩
\langle x_i \rangle
⟨xi⟩ 导出 induces 一个相应的模
p
p
p 的序列
⟨
x
i
′
⟩
\langle x_i' \rangle
⟨xi′⟩ ,其中对所有
i
i
i ,有
x
i
′
=
x
i
m
o
d
p
x_i' = x_i \bmod p
xi′=ximodp
更进一步,因为
f
n
f_n
fn 是仅使用模
n
n
n 算术操作(平方和减法)定义的,我们能从
x
i
′
x_i'
xi′ 来计算
x
i
+
1
′
x_{i+1}'
xi+1′ ;这一序列从模
p
p
p 的角度看,是从模
n
n
n 的角度看的一个较小版本:
x
i
+
1
′
=
x
i
+
1
m
o
d
p
=
f
n
(
x
i
)
m
o
d
p
=
(
(
x
i
2
−
1
)
m
o
d
n
)
m
o
d
p
=
(
x
i
2
−
1
)
m
o
d
p
根
据
练
习
31.1
−
7
=
(
(
x
i
m
o
d
p
)
2
−
1
)
m
o
d
p
=
(
(
x
i
′
)
2
−
1
)
m
o
d
p
=
f
p
(
x
i
′
)
\begin{aligned} x_{i+1}' &= x_{i+1} \bmod p \\ &= f_n(x_i) \bmod p \\ &= (( x_i^2 - 1) \bmod n) \bmod p \\ &= ( x_i^2- 1) \bmod p \quad &根据练习31.1-7 \\ &= (( x_i \bmod p)^2 - 1) \bmod p \\ &= ((x_i') ^ 2 - 1) \bmod p \\ &= f_p(x_i') \end{aligned}
xi+1′=xi+1modp=fn(xi)modp=((xi2−1)modn)modp=(xi2−1)modp=((ximodp)2−1)modp=((xi′)2−1)modp=fp(xi′)根据练习31.1−7 因此,虽然我们没有显式计算序列
⟨
x
i
′
⟩
\langle x_i' \rangle
⟨xi′⟩ ,但这个序列是良定义的,而且与序列
⟨
x
i
⟩
\langle x_i \rangle
⟨xi⟩ 有相同的递归式。
像之前一样进行推论,我们可以发现在序列 ⟨ x ′ ⟩ \langle x' \rangle ⟨x′⟩ 重复之前、预计执行的步数是 Θ ( p ) \Theta(\sqrt{ p}) Θ(p) 。如果和 n n n 相比 p p p 更小,则序列 ⟨ x i ′ ⟩ \langle x_i' \rangle ⟨xi′⟩ 的重复可能比序列 ⟨ x i ⟩ \langle x_i \rangle ⟨xi⟩ 的重复要快得多。事实上,只要序列 ⟨ x i ⟩ \langle x_i \rangle ⟨xi⟩ 中的两个元素仅模 p p p 等价、而非模 n n n 等价,序列 ⟨ x i ′ ⟩ \langle x_i' \rangle ⟨xi′⟩ 就发生重复。图31-7(b)和c)说明了这一点。
让 t t t 表示 ⟨ x i ′ ⟩ \langle x'_i\rangle ⟨xi′⟩ 序列中第一个重复出现的值的下标,让 u > 0 u > 0 u>0 表示这样产生的循环回路的长度。这就是说, t t t 和 u > 0 u > 0 u>0 是对所有 i ≥ 0 i \ge 0 i≥0 满足条件 x t + i ′ = x t + u + i ′ x_{t +i}' = x_{t+u+i}' xt+i′=xt+u+i′ 的最小值。根据上面的论证, t , u t, u t,u 的期望值都是 Θ ( p ) \Theta(\sqrt{p}) Θ(p) 。注意,如果 x t + i ′ = x t + u + i ′ x_{t+i}' = x_{t + u + i}' xt+i′=xt+u+i′ ,则 p ∣ ( x t + u + i − x t + i ) p \mid (x_{t + u + i} - x_{t + i}) p∣(xt+u+i−xt+i) 。因此, g c d ( x t + u + i − x t + i , n ) > 1 gcd(x_{t + u + i} - x_{t + i}, n) > 1 gcd(xt+u+i−xt+i,n)>1
因此,只要 POLLARD-RHO 把「使得
k
≥
t
k \ge t
k≥t 的任何值
x
k
x_k
xk 」都存入变量
y
y
y ,则
y
m
o
d
p
y \bmod p
ymodp 总在模
p
p
p 的回路中 on the cycle modulo p(如果把一个新值存为
y
y
y ,则该值也在模
p
p
p 的回路中)。最终,
k
k
k 将被赋予一个大于
u
u
u 的值,然后过程就在不改变
y
y
y 值的情况下,沿着模为
p
p
p 的回路完成整个一次循环。当
x
i
x_i
xi “遇到”以前存储在
y
y
y 中的模
p
p
p 的值时,即
x
i
≡
y
(
m
o
d
p
)
x_i \equiv y \pmod p
xi≡y(modp) ,就发现了
n
n
n 的一个因子。
假定发现的因子是因子 p p p ,尽管偶尔也可能是 p p p 的倍数。由于 t , u t, u t,u 的期望值都是 Θ ( p ) \Theta(\sqrt{p}) Θ(p) ,所以产生因子 p p p 所要求的期望执行步数为 Θ ( p ) \Theta(\sqrt{p}) Θ(p) 。
该算法可能不会如期望地执行,有两个原因:
- 对运行时间的启发式分析并不严格,模 p p p 的值的回路有可能要比 p \sqrt{p} p 大得多。在这种情况下,虽然算法的执行正确,但其执行速度要比期望低得多。在实际应用中,这似乎还可以讨论。
- 第二,这一算法得出的
n
n
n 的约数可能总是平凡因子
1
1
1 或
n
n
n 。例如,假设
n
=
p
q
n = pq
n=pq ,这里
p
,
q
p, q
p,q 为素数,可能会出现下面的情形:关于
p
p
p 的
t
,
u
t, u
t,u 的值与关于
q
q
q 的
t
,
u
t, u
t,u 的值相等,所以因子
p
,
q
p, q
p,q 总是在相同的
g
c
d
gcd
gcd 运算中被展现。由于两个因子同时被呈现,因此也就呈现出无用的平凡分解
p
q
=
n
pq = n
pq=n
the trivial factor pq D n is revealed, which is useless。这在实际应用中似乎没有意义。如果需要,可用一个不同形式的递归式 x i + 1 = ( x i 2 − c ) m o d n x_{i+1} = (x_i^2 - c) \bmod n xi+1=(xi2−c)modn 来重新开始运行该启发式过程(值 c = 0 , c = 2 c = 0, c = 2 c=0,c=2 应该被避免,其原因这里不做说明,但对其他值没有问题)。
当然,上述分析过程是启发式的、而不是严格的,因为递归式并不真是随机的。然而,这个过程可以在实际应用中良好地运行,并且似乎和我们在上面的启发式分析中说明的一样有效。它是一种找出大整数的小素数因子的、可供选择的方法 It is the method of choice for finding small prime factors of a large number 。
为了对一个
β
\beta
β 位合数
n
n
n 完全分解因子,仅需找出所有小于
⌊
n
1
/
2
⌋
\lfloor n^{1/2} \rfloor
⌊n1/2⌋ 的素数因子就可以了,因此我们期望 POLLARD-RHO 需执行的算术运算至多为
n
1
/
4
=
2
β
/
4
n^{1/4} = 2^{ \beta / 4}
n1/4=2β/4 次,位操作至多为
n
1
/
4
β
2
=
2
β
/
4
β
2
n^{1/4} \beta^2 = 2^{\beta / 4} \beta^2
n1/4β2=2β/4β2 次。POLLARD-RHO 最具吸引力的特点就是,它可以在期望的
Θ
(
p
)
\Theta(\sqrt{p})
Θ(p) 次算术运算内,找出
n
n
n 的一个小因子
p
p
p 。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











