






The architecture of neural networks 神经网络的结构
In the next section I’ll introduce a neural network that can do a pretty good job classifying handwritten digits. In preparation for that, it helps to explain some terminology that lets us name different parts of a network. Suppose we have the network:
在下个章节我将介绍可以很好识别手写数字的神经网络。在开始之前需要解释一下网络各部分的术语。设想我们有下面这样一张网络:
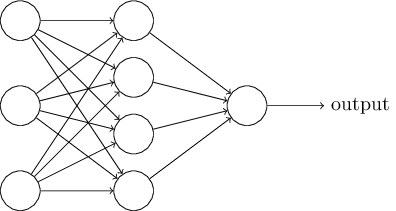
As mentioned earlier, the leftmost layer in this network is called the input layer, and the neurons within the layer are called input neurons. The rightmost or output layer contains the output neurons, or, as in this case, a single output neuron. The middle layer is called a hidden layer, since the neurons in this layer are neither inputs nor outputs. The term “hidden” perhaps sounds a little mysterious - the first time I heard the term I thought it must have some deep philosophical or mathematical significance - but it really means nothing more than “not an input or an output”. The network above has just a single hidden layer, but some networks have multiple hidden layers. For example, the following four-layer network has two hidden layers:
正如之前介绍的,网络最左边的一层被称为输入层,这一层的神经元被称为输入神经元。最右边一层或称之为输出层包含输出神经元,或者如这个示例一样只有一个输出神经元。中间层被称为隐含层,这些层上的神经元既不是输入也不是输出。“隐含”也许听起来有点神秘——一开始我听到这个名词我就想它一定有某些哲学的或数学的含义——但是它真的就是表示“不是输入也不是输出”。上面的网络仅仅只有一个隐含层,但是其他网络具有多个隐含层。例如下面的这个四层网络有两个隐含层:
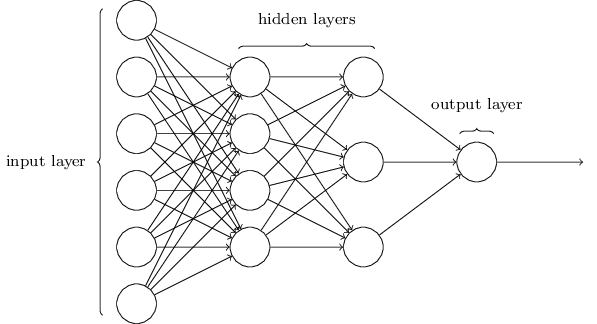
Somewhat confusingly, and for historical reasons, such multiple layer networks are sometimes called multilayer perceptrons or MLPs, despite being made up of sigmoid neurons, not perceptrons. I’m not going to use the MLP terminology in this book, since I think it’s confusing, but wanted to warn you of its existence.
多少会有些困惑,而且基于历史原因,这样的多层网络有时候被称为多层感知器或者MLPs,尽管它们由sigmoid神经元而不是感知器构成。我不准备在本书中使用MLP,因为我认为它是混淆不清的,但是还是要提醒你它的存在。
The design of the input and output layers in a network is often straightforward. For example, suppose we’re trying to determine whether a handwritten image depicts a “9” or not. A natural way to design the network is to encode the intensities of the image pixels into the input neurons. If the image is a
64
by
64
greyscale image, then we’d have
4,096=64×64
input neurons, with the intensities scaled appropriately between
0
and
1
. The output layer will contain just a single neuron, with output values of less than
0.5
indicating “input image is not a 9”, and values greater than
0.5
indicating “input image is a 9 “.
网络中输入层和输出层的设计通常是直截了当的。例如,设想我们尝试鉴别一个手写数字是否是“9”。一个设计这个网络很自然的方法就是将图片每个像素的灰度输入神经元。如果这个图片是
64
乘
64
像素的灰度图,那么我们将有
4,096=64×64
个输入神经元,其输入是缩放到
0,1
之间的灰度。输出层只有一个神经元,输出值小于
0.5
代表“输入图片不是9”,输出值大于
0.5
代表“输入图片是9”。
While the design of the input and output layers of a neural network is often straightforward, there can be quite an art to the design of the hidden layers. In particular, it’s not possible to sum up the design process for the hidden layers with a few simple rules of thumb. Instead, neural networks researchers have developed many design heuristics for the hidden layers, which help people get the behaviour they want out of their nets. For example, such heuristics can be used to help determine how to trade off the number of hidden layers against the time required to train the network. We’ll meet several such design heuristics later in this book.
不同于网络中输入层和输出层的设计通常是直截了当的,设计隐含层实在是个艺术。通常来说,很难用仅仅几条经验法则来总结隐含层的设计过程。相反,神经网络的研究者开发了许多试探方法来设计隐含层,这些方法帮助人们获得他们想要网络拥有的性能。例如,这些方法可以被用来帮助决定如何权衡隐含层的数量和网络的训练时间。我们将在本书的后续章节接触一些这样试探方法。
Up to now, we’ve been discussing neural networks where the output from one layer is used as input to the next layer. Such networks are called feedforward neural networks. This means there are no loops in the network - information is always fed forward, never fed back. If we did have loops, we’d end up with situations where the input to the
σ
function depended on the output. That’d be hard to make sense of, and so we don’t allow such loops.
目前为止,我们已经讨论了神经网络中一层的输出被用作下一层的输入。这样的网络被称为前馈神经网络。这意味着在网络中不存在环——信息总是向前传播的,永远不向后。如果我们确实拥有环,我们必须结束于
σ
函数的输入依赖于输出的情况。这个很难被理解,所以我们不允许这样的环。
However, there are other models of artificial neural networks in which feedback loops are possible. These models are called recurrent neural networks. The idea in these models is to have neurons which fire for some limited duration of time, before becoming quiescent. That firing can stimulate other neurons, which may fire a little while later, also for a limited duration. That causes still more neurons to fire, and so over time we get a cascade of neurons firing. Loops don’t cause problems in such a model, since a neuron’s output only affects its input at some later time, not instantaneously.
但是,还是有其他人工神经网络模型也许有反馈环。这些模型被称为循环神经网络。这些模型的思路是其中有的神经元可以在休眠之前激活有限的时间。这种激活可以激励其他神经元,因此久而久之我们得到了串联的神经元激活。在这种模型中环路不会引起问题,因为这些神经元的输出延迟一段时间才影响它的输入,而不是立即的。
Recurrent neural nets have been less influential than feedforward networks, in part because the learning algorithms for recurrent nets are (at least to date) less powerful. But recurrent networks are still extremely interesting. They’re much closer in spirit to how our brains work than feedforward networks. And it’s possible that recurrent networks can solve important problems which can only be solved with great difficulty by feedforward networks. However, to limit our scope, in this book we’re going to concentrate on the more widely-used feedforward networks.
循环神经网络没有前馈神经网络有影响力,部分是因为它的学习算法目前为止能力较弱。不过循环神经网络仍然是非常有趣的。他们比前馈神经网络更贴近于人脑的工作模式。并且也许循环神经网络可能可以解决目前前馈神经网络很难解决的重要问题。但是限于本书我们将聚焦于被更广泛使用的前馈神经网络。
转自:http://blog.csdn.net/forrestyanyu/article/details/54860561















 1602
1602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









