







Motivation : a limitation of the (supervised) ML framework \scriptsize{\text{: a limitation of the (supervised) ML framework}} : a limitation of the (supervised) ML framework
The current way of training and inference is to train the ML model on some randomly drawn samples and test on some other independently drawn samples. A crucial assumption behind this is that the distribution that we use to train the ML model is exactly the distribution that the model will encounter. In reality, this is not the case as there are various forms of covariate shifts. Due to lack of this assumption, ML (particularly DL) predictions are brittle despite (mostly) accurate.
ML and adversarially robust ML
learning objective
In fact, lack of adversarial robustness is not at odds with what we currently want our ML models to achieve.
- standard generalization (average case performance): E ( x , y ) ∼ D [ l o s s ( θ , x , y ) ] \mathbb{E}_{(x,y)\sim D} [loss(\theta,x,y)] E(x,y)∼D[loss(θ,x,y)]
- adversarial robust generalization (worst-case notion, measure zero event): E ( x , y ) ∼ D [ max δ ∈ Δ l o s s ( θ , x + δ , y ) ] \mathbb{E}_{(x,y)\sim D} [\max_{\delta \in \Delta} loss(\theta,x+\delta,y)] E(x,y)∼D[maxδ∈Δloss(θ,x+δ,y)]
generalization of standard and robust deep networks
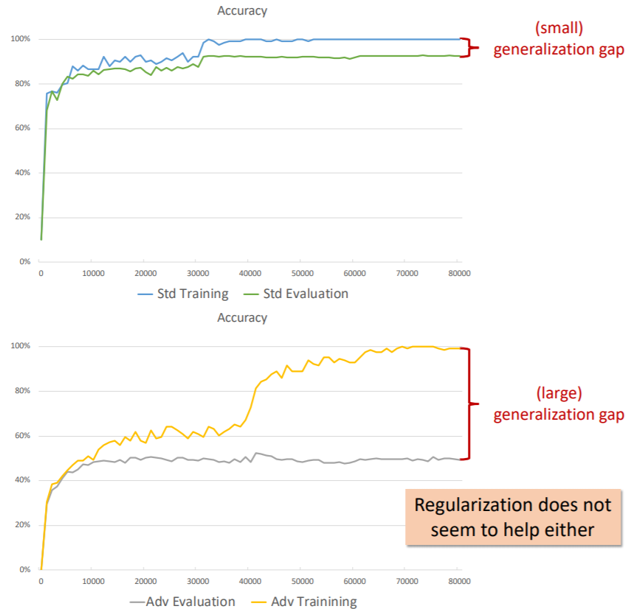
Not only does the optimization problem become more challenging and the model become larger(training), adversarial robustness has a significantly larger sample complexity, thus its generalization requires more data (test).
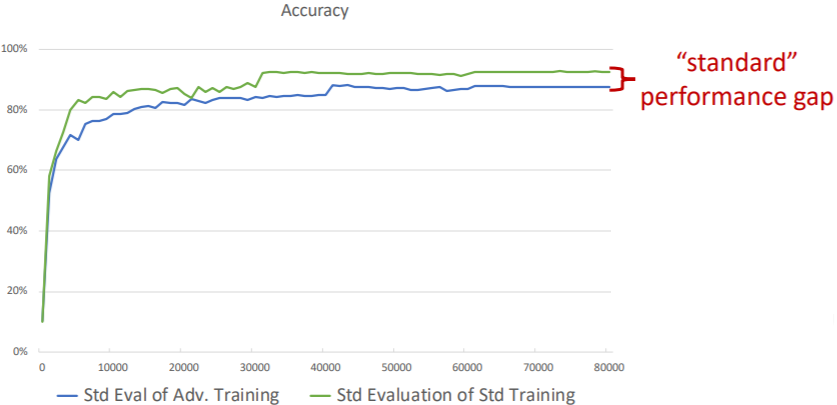
No ‘free lunch’: can exist a trade-off between accuracy and robustness. Intuitively,
- in standard training, all correlation among features is a good correlation (so-called non-robust features in [3]);
- if we want robustness, must avoid weakly correlated features.
interpretability

Adversarial Examples and Verification (inner minimization)
min θ ∑ ( x , y ) ∼ S max δ ∈ Δ L ( θ , x + δ , y ) ⏟ Part I. create AEs or verify it does not exist \min_\theta \sum_{(x,y)\sim S} \underbrace{\max_{\delta \in \Delta} L(\theta,x+\delta,y)}_\text{Part I. create AEs or verify it does not exist} θmin(x,y)∼S∑Part I. create AEs or verify it does not exist δ∈ΔmaxL(θ,x+δ,y)
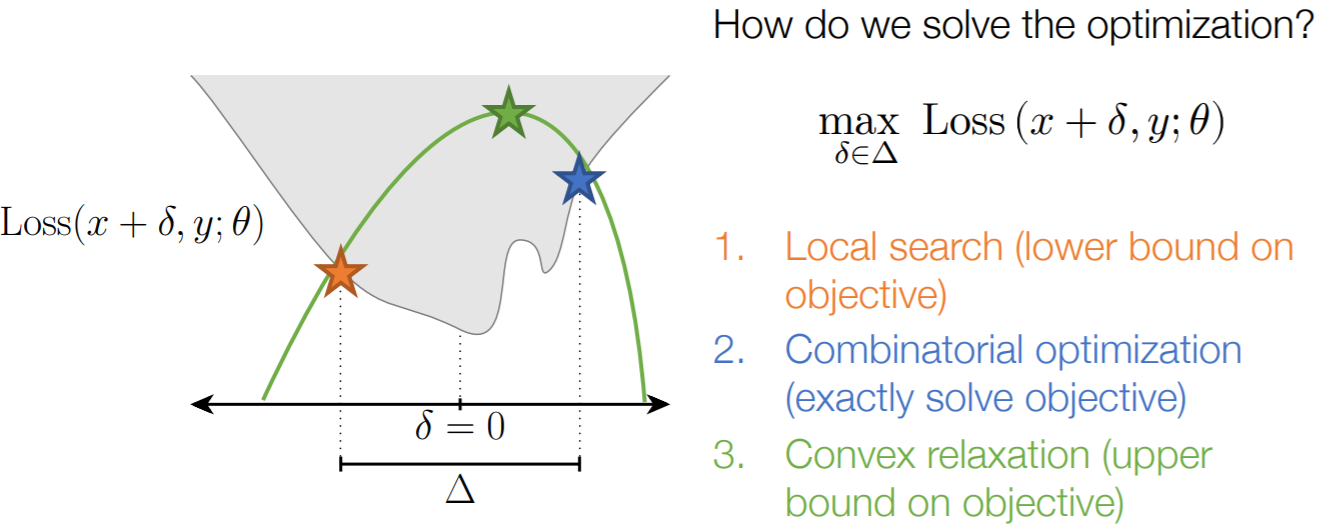
In the linear case with a norm ball perturbation region, the maximization has exact solution based on dual norm; a simple instance of robust optimization. That is,
max δ L ( θ T ( x + δ ) ⋅ y ) = L ( min δ θ T ( x + δ ) ⋅ y ) = L ( θ T x ⋅ y − ∥ θ ∥ ∗ ) \begin{aligned} \max_\delta L(\theta^T (x + \delta) \cdot y) &=L(\min_\delta \theta^T (x + \delta) \cdot y)\\ &=L(\theta^T x \cdot y - \| \theta \|_\ast) \end{aligned} δmaxL(θT(x+δ)⋅y)</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









