







介绍
CycleGAN网络具有很强大的风格迁移功能。能够实现非常深层次的风格转换。比如男性图片女性化或者女性图片男性化。
先上效果图:

下面简单谈一谈实现原理。
网络结构
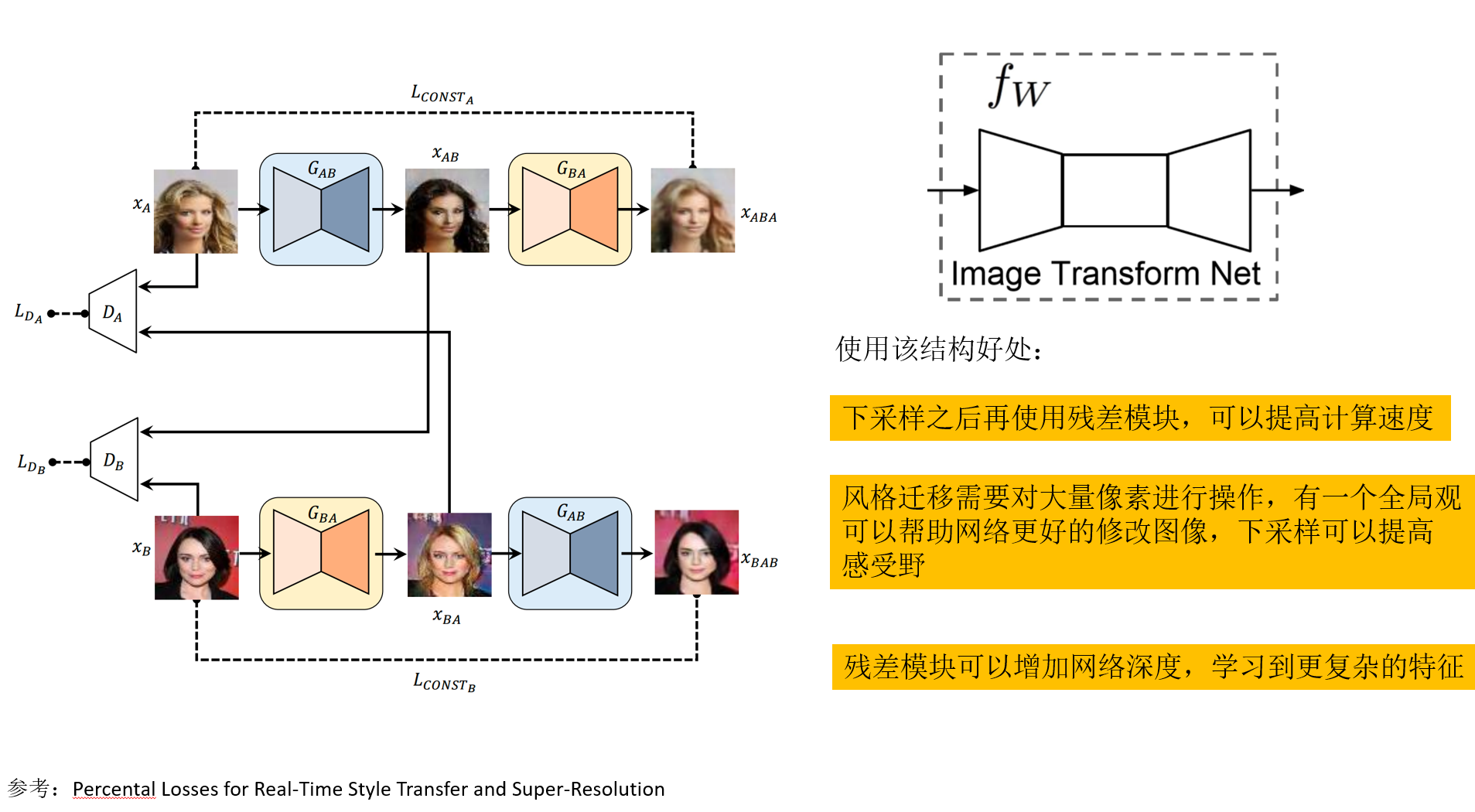
网络结构如图所示,通过两个循环使用的生成器来进行风格迁移。由此实现了非常神奇的效果。
下面结合代码来详细解释一下网络结构。训练生成对抗网络的深度学习框架为Pytorch。
1. 残差模块定义
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
# 残差模块不改变shape
conv_block = [ nn.ReflectionPad2d(1), # 构建残差模块的时候使用映射填充的形式
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features), # 不使用BatchNorm而是使用InstanceNorm
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features) ]
self.conv_block = nn.Sequential(*conv_block)
def forward(self, x):
return x + self.conv_block(x)
残差模块的定义没有太多需要说明的地方,就是有一点需要注意的是。我们在风格迁移中,不再使用BatchNorm而是使用InstanceNorm。
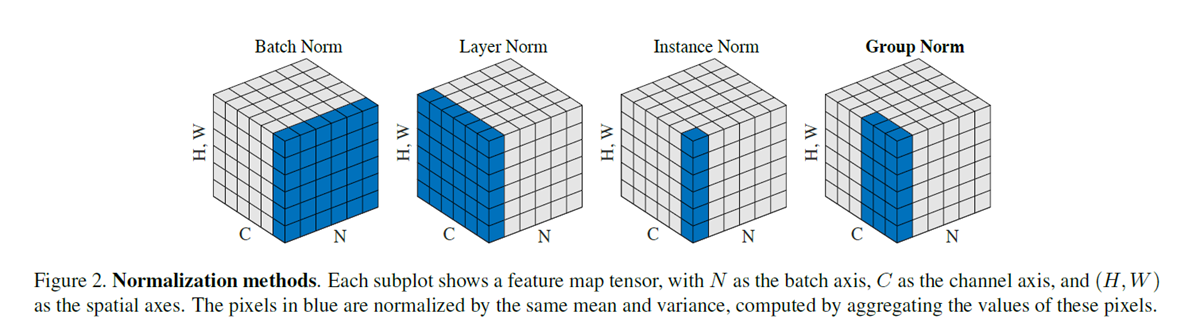
BN是将每一个batch的每一个通道的每一组图片求mean和var, IN是将单独一个图片的一个通道的数据求mean和var。 区别就是一个是对batch求,一个是对一个图片求。风格迁移中,为了保证风格,通常都对每一个图片单独处理。 CycleGAN网络中,每一个batch只有一张 图片,所以使用InstanceNorm。
2. 定义生成器
class Generator(nn.Module):
def __init__(self, input_nc, output_nc, n_residual_blocks=9):
"""
定义生成网络
参数:
input_nc --输入通道数
output_nc --输出通道数
n_residual_blocks --残差模块数量
"""
super(Generator, self).__init__()
# 初始化卷积模块
# 因为使用ReflectionPad扩充
# 所以输入是3*256*256
# 输出是64*256*256
model = [ nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, 64, 7),
nn.InstanceNorm2d(64),
nn.ReLU(inplace=True) ]
# 进行下采样
# 第一个range:输入是64*256*256,输出是128*128*128
# 第二个range:输入是128*128*128,输出是256*64*64
in_features = 64
out_features = in_features*2
for _ in range(2):
model += [ nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True) ]
in_features = out_features
out_features = in_features*2
# 使用残差模块
# 输入输出都是256*64*64
for _ in range(n_residual_blocks): # 默认添加9个残差模块
model += [ResidualBlock(in_features)]
# 进行上采样
# 第一个range:输入是256*64*64,输出是128*128*128
# 第二个range:输入是128*128*128,输出是64*256*256
out_features = in_features//2
for _ in range(2):
model += [ nn.ConvTranspose2d(in_features, out_features, 3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True) ]
in_features = out_features
out_features = in_features//2
# 最后输出层
# 输入是64*256*256
# 输出是3*256*256
model += [ nn.ReflectionPad2d(3),
nn.Conv2d(64, output_nc, 7),
nn.Tanh() ]
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
生成器的结构就是最初那幅图中的右侧的样子。进行下采样之后接一个残差模块,再之后进行上采样。生成器期望可以学到比较复杂的特征构造方法,所以网络结构更深,更复杂。判别器结构相对来说要简单很多。
3. 判别器
class Discriminator(nn.Module):
def __init__(self, input_nc):
super(Discriminator, self).__init__()
# 构建卷积分类器
# 输入为3*256*256
# 输出为64*128*128
model = [ nn.Conv2d(input_nc, 64, 4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True) ]
# 输入为64*128*128
# 输出为128*64*64
model += [ nn.Conv2d(64, 128, 4, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2, inplace=True) ]
# 输入为128*64*64
# 输出为256*32*32
model += [ nn.Conv2d(128, 256, 4, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2, inplace=True) ]
# 输入为256*32*32
# 输出为512*31*31
model += [ nn.Conv2d(256, 512, 4, padding=1),
nn.InstanceNorm2d(512),
nn.LeakyReLU(0.2, inplace=True) ]
# 全卷积分类层
# 输入为输出为512*31*31
# 输出为1*30*30
model += [nn.Conv2d(512, 1, 4, padding=1)]
self.model = nn.Sequential(*model)
def forward(self, x):
x = self.model(x)
# 使用平均池化的办法输出预测值
# avg_pool2d(input,kernel_size),这里kernel_size为30
return F.avg_pool2d(x, x.size()[2:]).view(x.size()[0], -1)
就是一个比较普通的分类网络。通过步长为2来逐步缩小尺寸。可能值得注意的是,相比于传统的分类神经网络。我们这里使用全局平均池化的方式进行最终输出预测。没有使用全连接层,减小了网络尺寸。
此外,我还做了一个exe交互程序。可以直接运行,实现图片中头像识别和对应性别转换。可以体验一下生成对抗网络的趣味。
对网络感兴趣,以及想要详细了解原理是具体如何用代码实现,或者想用有趣数据集做出创意应用的功能的话,可以参考这个视频课程:点击链接
————————————————
版权声明:本文为CSDN博主「Einstellung」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Einstellung/article/details/103265731















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









