——此次操作需要linux相关指令,如有疑惑,请先学习linux再看此篇文章。 @ Author 云天河Blog 找寻优化思路 -> sql语句优化 -> 索引优化
更新时间2016年7月30日 11:12:19
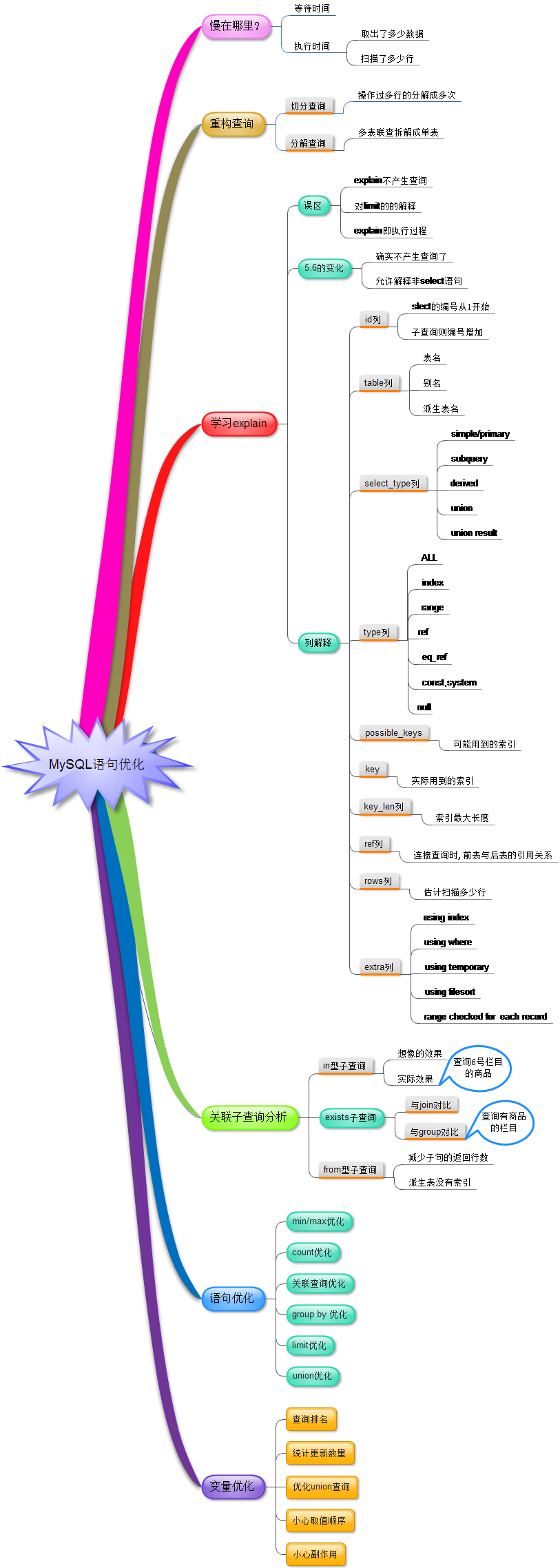
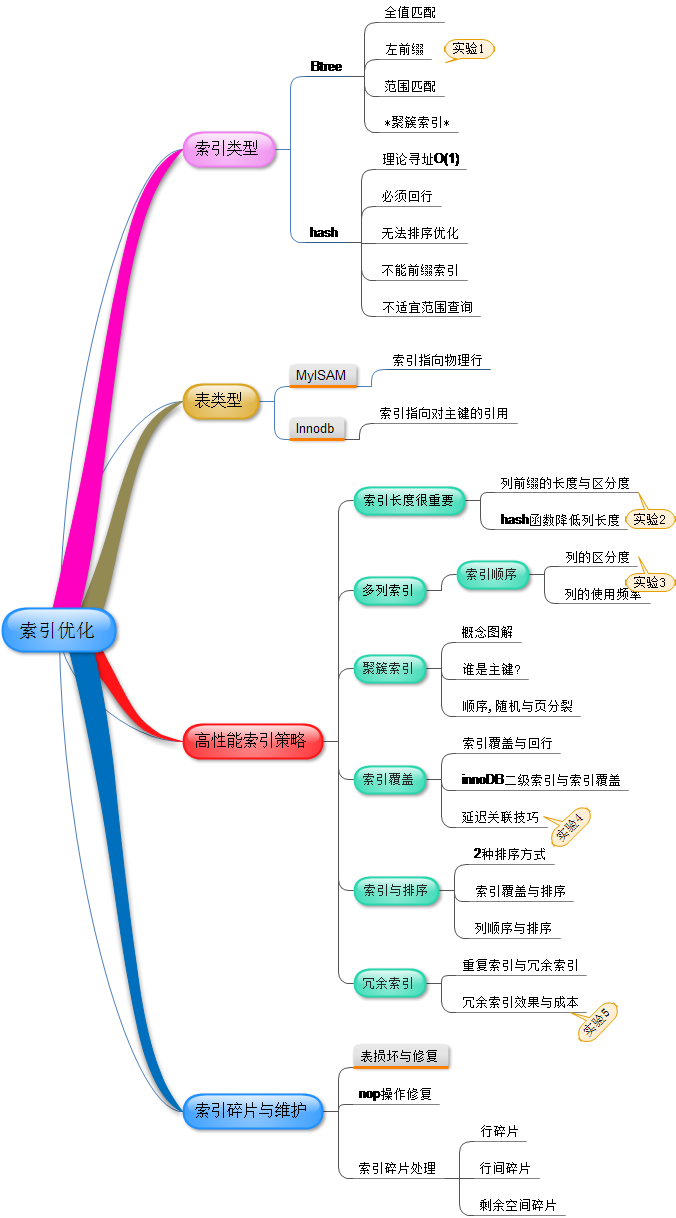
MySQL服务器调优思路
Awk脚本
>擅长处理--多行多列的数据
[示例 ] 我在a.txt文件中存储的内容是
id name score
1 hlz 90
2 leo 66
3 lance 80
类似正则匹配,$0表示全部内容 $1表示第一列的数据 $2表示第二列的数据 $3表示第三列的数据
// 把 a.txt 的全部 列进行输出 // 把 a.txt 的第二列 进行输出 // 把 a.txt 的含有na 的一列进行输出
awk ‘{printf“%s\n” , $0}’ a.txt awk ‘{printf“%s\n” , $2}’ a.txt awk ‘/na/{printf“%s\n” , $0}’ a.txt
//输出结果 //输出结果 //输出结果
id name score name name hlz hlz leo leo lance lance
awk脚本 统计mysql服务器信息,并写入日志
[ 示例 ] mysql -hlocalhost -u帐号 -p密码 -e "show status" >> mysql_status.txt
InnoDB与Myisam的六大区别
MyISAM
InnoDB
构
成
上
的
区
别:
每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。
基于磁盘的资源是InnoDB表空间数据文件和它的日志文件,InnoDB 表的大小只受限于操作系统文件的大小,一般为 2GB
事务
处理
上
方面:
MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持
InnoDB提供事务支持事务,外部键等高级数据库功能
SELECT UPDATE,INSERT,Delete操作
如果执行大量的SELECT,MyISAM是更好的选择
1. 如果你的数据执行大量的INSERT或UPDATE ,出于性能方面的考虑,应该使用InnoDB表2.DELETE FROM table 时,InnoDB不会重新建立表,而是一行一行的删除。3.LOAD TABLE FROM MASTER 操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用
对AUTO
_INCREMENT
的操作
每表一个AUTO_INCREMEN列的内部处理。MyISAM为INSERT和UPDATE操作自动更新这一列 。这使得AUTO_INCREMENT列更快(至少10%)。在序列顶的值被删除之后就不能再利用。(当AUTO_INCREMENT列被定义为多列索引的最后一列,可以出现重使用从序列顶部删除的值的情况)。
如果你为一个表指定AUTO_INCREMENT列,在数据词典里的InnoDB表句柄包含一个名为自动增长计数器的计数器,它被用在为该列赋新值。AUTO_INCREMENT列在InnoDB里如何工作
表的
具体
行数
select count(*) from table,MyISAM只要简单的读出保存好的行数,注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的
InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行
锁
表锁
提供行锁(locking on row level),提供与 Oracle 类型一致的不加锁读取(non-locking read in
























 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









