





為了完整起見,我這裡再用一些例子加以說明 ${ } 的一些特異功能:
假設我們定義了一個變量為:
file=/dir1/dir2/dir3/my.file.txt
我們可以用 ${ } 分別替換獲得不同的值:
${file#*/}:拿掉第一條 / 及其左邊的字串:dir1/dir2/dir3/my.file.txt
${file##*/}:拿掉最後一條 / 及其左邊的字串:my.file.txt
${file#*.}:拿掉第一個 . 及其左邊的字串:file.txt
${file##*.}:拿掉最後一個 . 及其左邊的字串:txt
${file%/*}:拿掉最後條 / 及其右邊的字串:/dir1/dir2/dir3
${file%%/*}:拿掉第一條 / 及其右邊的字串:(空值)
${file%.*}:拿掉最後一個 . 及其右邊的字串:/dir1/dir2/dir3/my.file
${file%%.*}:拿掉第一個 . 及其右邊的字串:/dir1/dir2/dir3/my
記憶的方法為:
# 是去掉左邊(在鑑盤上 # 在 $ 之左邊)
% 是去掉右邊(在鑑盤上 % 在 $ 之右邊)
單一符號是最小匹配﹔兩個符號是最大匹配。
${file:0:5}:提取最左邊的 5 個字節:/dir1
${file:5:5}:提取第 5 個字節右邊的連續 5 個字節:/dir2
我們也可以對變量值裡的字串作替換:
${file/dir/path}:將第一個 dir 提換為 path:/path1/dir2/dir3/my.file.txt
${file//dir/path}:將全部 dir 提換為 path:/path1/path2/path3/my.file.txt
利用 ${ } 還可針對不同的變數狀態賦值(沒設定、空值、非空值):
${file-my.file.txt} :假如 $file 沒有設定,則使用 my.file.txt 作傳回值。(空值及非空值時不作處理)
${file:-my.file.txt} :假如 $file 沒有設定或為空值,則使用 my.file.txt 作傳回值。 (非空值時不作處理)
${file+my.file.txt} :假如 $file 設為空值或非空值,均使用 my.file.txt 作傳回值。(沒設定時不作處理)
${file:+my.file.txt} :若 $file 為非空值,則使用 my.file.txt 作傳回值。 (沒設定及空值時不作處理)
${file=my.file.txt} :若 $file 沒設定,則使用 my.file.txt 作傳回值,同時將 $file 賦值為 my.file.txt 。 (空值及非空值時不作處理)
${file:=my.file.txt} :若 $file 沒設定或為空值,則使用 my.file.txt 作傳回值,同時將 $file 賦值為 my.file.txt 。 (非空值時不作處理)
${file?my.file.txt} :若 $file 沒設定,則將 my.file.txt 輸出至 STDERR。 (空值及非空值時不作處理)
${file:?my.file.txt} :若 $file 沒設定或為空值,則將 my.file.txt 輸出至 STDERR。 (非空值時不作處理)
tips:
以上的理解在於, 你一定要分清楚 unset 與 null 及 non-null 這三種賦值狀態.
一般而言, : 與 null 有關, 若不帶 : 的話, null 不受影響, 若帶 : 則連 null 也受影響.
還有哦,${#var} 可計算出變量值的長度:
${#file} 可得到 27 ,因為 /dir1/dir2/dir3/my.file.txt 剛好是 27 個字節...
在这里记录写shell编程中常用到的东西,可能容易混淆的一些参数什么的,一点点补充吧
一、文件判断
if [ -f "$file" ] -f是判断文件是否存在,即这个路径下是否有这个文件。
if [ -d "path" ] -d是判断这个路径是否存在,可以理解为这个路径下是否有该文件夹
二、关于排序
由于时常会使用awk等命令来提取字符信息,有时候会提取数字或者字母,这时候就要用到了排序
排序并不会去截取你排序的区间,而是你整块的信息
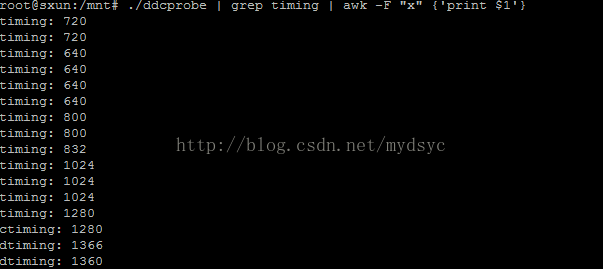
如下是截取的显示器支持的分辨率的X轴
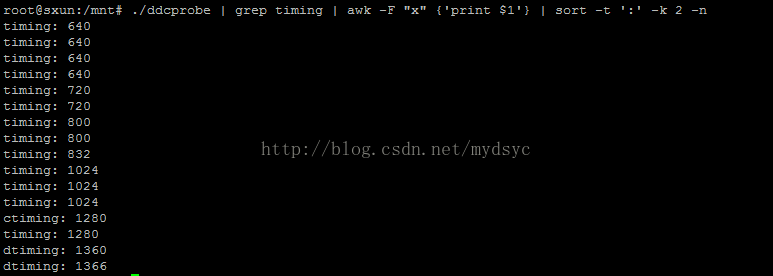
我想要以高低分辨率排序则执行 ./ddcprobe | grep timing | awk -F "x" {'print $1'} | sort -t ':' -k 2 -n 其中-t 为分隔符,-k 表示的是分隔符的第二块区间,由于要比对纯数字,所以使用-n,表示比对纯数字。比对结果如下
由于取到的值可能会有重复的,所以这时候如果需要的话可以去掉重复的行,只需要再使用命令uniq过滤即可
./ddcprobe | grep timing | awk -F "x" {'print $1'} | awk -F ":" {'print $2'} | sort -n | uniq
三、输出行列
常常我们会截取行列,常用的有awk,这个东西非常多的内容常用的方法也比较清楚了吧,我这里记录一个sed的用法,sed -n '1p;$p',这个用法可以将第一行和最后一行给输出,当然可以多个输出,或者单独输出。

















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









