







压缩软件:
给定一篇文章,只含有英文大小写字母和空格,统计该文件中各种字符的频率,对各字符进行Huffman编码,将该文件翻译成Huffman编码文件,再将Huffman编 码文件翻译成源文件。
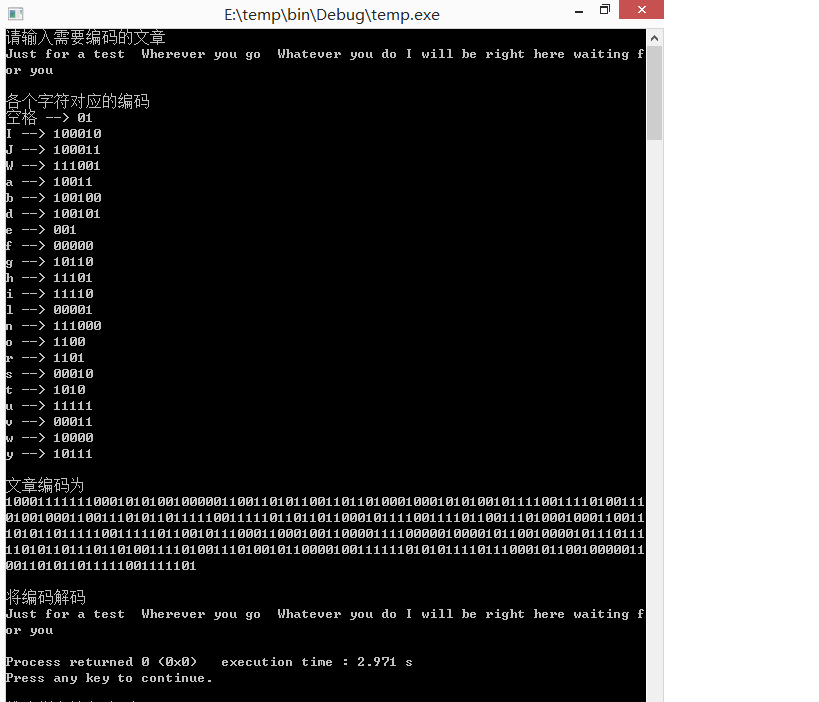
运行结果如下
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
typedef struct
{
int value;
int p,l,r;
}HTNode,*HuffTree;
struct fact //因为不是每一篇文章中所有字符都会出现
{ //所以结构体数组存储数组下标真正对应的字符ch以及权值weight
char ch;
int weight;
};
typedef char * * HuffCode; // 字符指针数组用于存储各个字符对应的编码
typedef char * CHAR;
void select(HuffTree &HT,int n,int &s1,int &s2); //查找HT中未被使用的权值最小的连个点的下标
void HUFFTREE(HuffTree &HT,fact *ww,int n,HuffCode &HC); //建树函数,附带完成每一个字符对应的编码
void BecomeCode(HuffCode &HC,int n,CHAR &Code,char *Text,int *match); //由已知的各个字符的编码完成全文的编码
void Code_ToBe_Artical(CHAR &Code,HuffTree &HT,fact *Fact,int n); //由全文的编码,用已经建立的哈弗曼 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









