








在开放域关键词提取中捕获全局信息
Si Sun 1 ? , Zhenghao Liu 2 ? , Chenyan Xiong 3 , Zhiyuan Liu 4 ?? , and Jie Bao 1 ?? 1 Department of Electronic Engineering, Tsinghua University, China 2 Department of Computer Science and Technology, Northeastern University, China 3 Microsoft Research, USA 4 Department of Computer Science and Technology, Tsinghua University, China Institute for Artificial Intelligence, Tsinghua University, China Beijing National Research Center for Information Science and Technology, China s-sun17@mails.tsinghua.edu.cn ; liuzhenghao@cse.neu.edu.cn chenyan.xiong@microsoft.com ; { liuzy, bao } @tsinghua.edu.cn
摘要开放域关键短语提取(KPE)旨在从没有域或质量限制的文档中提取关键短语,例如具有不同域和质量的网页。最近,神经方法由于其强大的建模能力,在许多KPE任务中显示出良好的结果。
然而,我们的经验表明,大多数神经KPE方法倾向于从开放域文档中提取具有良好短语的关键短语,例如短的和实体风格的n-gram,而不是全局信息的关键短语。本文提出了一种基于预先训练的语言模型的开放域KPE体系结构JointKPE,它可以在提取关键短语时同时捕获局部短语和全局信息。
JointKPE通过评估关键短语在整个文档中的信息量来学习对关键短语进行排名,并在关键短语组块任务中接受联合训练的,以确保关键短语候选词的措辞准确。在两个具有不同领域的大型KPE数据集(OpenKP和KP20k)上的实验表明,在开放领域场景中,联合KPE对不同预训练变量的有效性。进一步的分析揭示了JointKPE在预测长的和非实体的关键短语方面的显著优势,这对以前的神经KPE方法是一个挑战。我们的代码公开于https://github.com/thunlp/BERT-KPE。
1引言
能够提供文档简洁摘要的关键短语在改进许多自然语言处理(NLP)和信息检索(IR)任务方面显示出了潜力,如摘要[29]、建议[28]和文档检索[14]。高质量的关键短语有两个特点,即短语性和信息性[32]:短语性是指一系列单词在文档的局部上下文中可以作为一个完整语义单元的程度;信息性表明一个文本片段能够很好地抓住整个文档的全局主题或突出概念【18】。以前的许多研究都利用这两个特性来提高KPE的性能[20,10]。
随着神经网络的发展,神经KPE方法在为科学出版物提取关键短语方面取得了令人信服的性能【23,31,25】。
近年来,许多研究人员已经开始通过考虑具有不同内容质量的不同提取域(如web KPE),使神经KPE适应开放域场景[39]。现有的神经KPE方法通常将关键短语提取表述为单词级序列标记任务【40】、n-gram级分类任务【39】和基于广度的提取任务【25】。尽管这些神经方法取得了成功,但它们似乎更注重对关键短语的局部语义特征进行建模,这可能导致它们在提取关键短语时优先考虑局部短语,而不是全局文档的信息性。
因此,他们倾向于从开放域文档中提取具有语义完整性的关键短语,如短n-gram和head-ish实体,而长尾短语有时传递更关键的信息[6]。
在本文中,我们提出了JointKPE,它服务于开放域关键字短语提取场景。在多任务训练体系结构下提取关键短语时,它可以同时考虑短语性和信息性。JointKPE首先求助于强大的预先训练的语言模型来对文档进行编码,并估计其所有n-gram的本地化信息量。对于具有相同词汇字符串但出现在不同上下文中的n-gram,JointKPE进一步计算其在完整文档中的全局信息性得分。最后,JointKPE学习根据这些关键词候选词的全局信息得分对其进行排名,并与关键词组块任务联合训练,以捕获局部短语和全局信息。
在两个大型KPE数据集OpenKP【39】和KP20k【23】上进行的实验,以及网页和科学论文,证明了JointKPE与广泛使用的预训练模型BERT【7】及其两个预训练变体SpanBERT【15】和RoBERTa【19】的鲁棒性。我们的实证分析进一步表明,JointKPE在预测开放域场景中的长关键短语和非实体关键短语方面具有优势。
2相关工作
自动关键词提取(KPE)涉及从文档中自动提取一组重要的主题短语[33,26]。在KPE的整个历史中,最早的带注释的关键词抽取语料库来自科学领域,包括技术报告和科学文献[17,2,3]。这是因为科学KPE语料库很容易管理,其关键短语已经由作者提供。除了科学语料库外,一些研究人员还从互联网和社交媒体收集了KPE语料库,例如新闻文章[34]和现场聊天[16],但这些语料库规模有限,在领域和主题方面缺乏多样性。最近,一个名为OpenKP[39]的大规模开放域KPE数据集已经发布,其中包括大约10万个域和主题分布广泛的带注释的web文档。基于上述语料库,提出并研究了广泛的自动KPE技术。
现有的KPE技术可分为无监督方法和有监督方法[26]。无监督KPE方法主要基于统计信息[9,11,4]和基于图的排序算法[24,21,30]。有监督的KPE方法通常将关键短语提取描述为短语分类[36,22,5]和学习对任务排序[13,20,41]。在许多KPE基准测试中,监督KPE方法,尤其是使用神经网络的KPE方法,在许多KPE基准测试中,都比最先进的无监督方法具有显著的性能优势【17,23,39】。
最早的神经KPE方法通常将KPE视为序列到序列学习[23]和序列标记[40]任务,采用基于RNN的编码器框架。这些方法的性能受到文本数据的浅层表示的限制。最近,Xiong等人将KPE描述为一个n-gram级的关键词组块任务,并提出了BLING-KPE。它将深度预训练的表示合并到卷积transformer体系结构中,以实现模型n-gram表示。与以前的方法相比,BLING-KPE取得了很大的改进。此外,最近的工作【1】将Transformers的完全自我注意力替换为本地全局注意力,这大大提高了长文档的KPE性能。最近,Wang等人[35]还表明,在网页中加入多模态信息,如字体、大小和DOM特征,可以进一步改进开放域web KPE。
3方法
给定文档D,JointKPE首先通过枚举文档的n-gram从文档中提取所有关键短语候选p,并利用层次结构对n-gram表示进行模型。JointKPE基于n-gram表示,利用信息排名网络对多个出现短语的局部信息性得分进行整合,以估计其在整个文档中的全局信息性得分。在训练期间,JointKPE与关键短语组块任务【39】联合接受训练的,以更好地平衡短语和信息量。
N-gram表示法。JointKPE first利用预先训练好的语言模型,如BERT[7],对文档进行编码,并输出一系列单词嵌入:
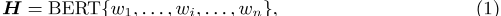
,其中h i是文档D中第i个单词w i的单词嵌入。
为了列举文档D的关键短语候选,由于关键短语通常以n-gram的形式出现,因此使用一组卷积神经网络(CNN)将单词嵌入集成到n-gram表示中。第i个k-gram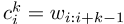 的表示计算为:
的表示计算为:
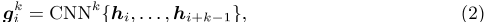
,其中每个k-gram由其相应的CNN k组成,窗口大小为k(1≤ K≤ K)。K是提取的n克的最大长度。
信息性排名。为了估计本地上下文中n-gram c k i的信息性,JointKPE采用前馈层将其上下文特定表示g k i投影到可量化分数:
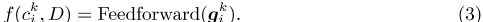
我们进一步计算在文档不同上下文中多次出现的短语的全局信息性分数。具体地说,让短语p k是文档D中长度为k的多出现短语。该短语出现在文档的不同上下文中,从而导致不同的局部信息性得分。对于该多发生短语,JointKPE在估计文档D中所有短语的全局信息性得分后,对其局部信息性得分应用最大池,以确定全局信息性得分,JointKPE可以学习使用成对排名损失在文档级别根据这些短语的全局信息性得分对其进行排名:
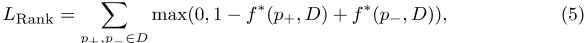
,其中排名损失L排名强制JointKPE将关键短语p+排在非关键短语p之前− 在同一文档D中。
关键词组块。为了增强ngram级别的短语测量,JointKPE结合关键词组块任务【39】,通过优化二元分类损失L组块
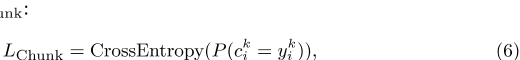
,直接学习预测n-gram的关键词概率,其中y k i是二元标签,表示n-gram c k i是否与文档中注释的关键词字符串精确匹配。
多任务训练。JointKPE的最终训练目标是最小化信息排名损失L排名和关键短语组块损失L组块的线性组合:

在推理阶段,具有最高全局信息性得分的排名靠前的短语被预测为给定文档的关键短语。
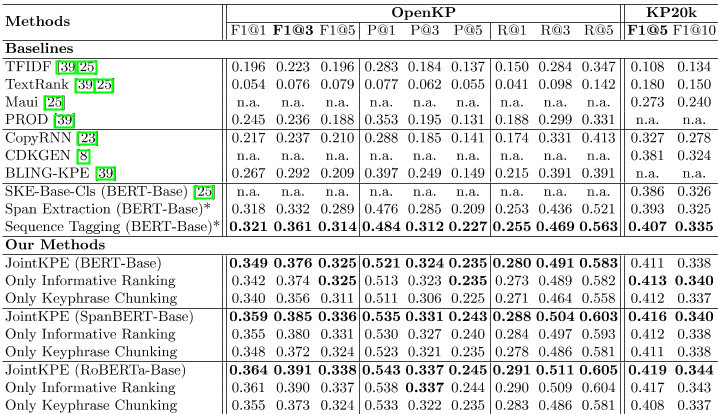
表1:。关键词提取的总体准确性。OpenKP上JointKPE的所有分数都来自于盲测试的官方排行榜。KP20k的基线评估结果来自相应的论文,带星号的基线*是我们的实现。大胆的F1@3和F1@5分别是OpenKP和KP20k的主要评估指标。
4实验方法
本节介绍我们的实验设置,包括数据集、评估指标、基线和实现细节。
数据集。实验中使用了两个大型KPE数据集。它们是OpenKP[39]和KP20k[23]。OpenKP是一个具有各种域和主题的开放域关键短语提取数据集,其中包含超过150000个真实世界的web文档以及由专家注释生成的最相关的关键短语。我们将OpenKP作为我们的主要基准,并遵循其训练(134k文档)、开发(6.6k)和测试(6.6k)集的官方划分。KP20k是一个计算机科学领域的科学KPE数据集,包含550000多篇文章,其中包含作者指定的关键短语。我们遵循原始工作对训练(528K文档)、开发(20K)和测试(20K)集的划分【23】。
评估指标。前N个关键短语预测的精度(P)、召回率(R)和F-度量(F1)用于评估KPE方法的性能。根据之前的研究【39,23】,我们在OpenKP上使用N={1,3,5},在KP20k上使用N={5,10},并考虑F1@3和F1@5分别作为OpenKP和KP20k的主要指标。对于KP20k,我们使用波特词干分析器(Porter Stemmer)[27]来确定两个短语的匹配,这与之前的工作一致[23]。
基线。我们在实验中比较了两组基线,包括传统KPE基线和神经KPE基线。
传统的KPE基线。与之前的工作【23,39,25】保持一致,我们将JointKPE与四种传统KPE方法进行了比较。它们是两种流行的无监督KPE方法TFIDF和TextRank【24】,以及两种在OpenKP和KP20k上表现良好的基于特征的KPE系统,分别命名为PROD【39】和Maui【22】。对于这些基线,我们采用其报告的性能。
神经KPE基线。我们还将我们的方法与六种神经KPE基线进行了比较:先前关于OpenKP、BLING-KPE的最新方法【39】和关于KP20k的三种高级神经KPE方法,包括CopyRNN【23】、CDKGEN【8】和SKE-Base Cls【25】,以及我们重建的两种基于BERT的KPE方法,包括跨度提取和序列标记。他们将KPE分别表述为跨度提取和序列标记任务。
实施细节。BERT[7]、斯潘伯特[15]和RoBERTa[19]的基本版本根据预先训练的权重进行初始化,用于实现JointKPE。我们的所有方法都使用Adam进行了优化,学习率为5e-5,预热比例为10%,批量为64。我们将最大序列长度设置为512,并简单地保持两个训练损失(公式7)的权重相同。根据之前的工作【23,39】,最大短语长度设置为5(K=5)。训练使用了两台特斯拉T4 GPU,分三个阶段进行,耗时约25小时。我们的实现基于PyTorch Transformers【37】。
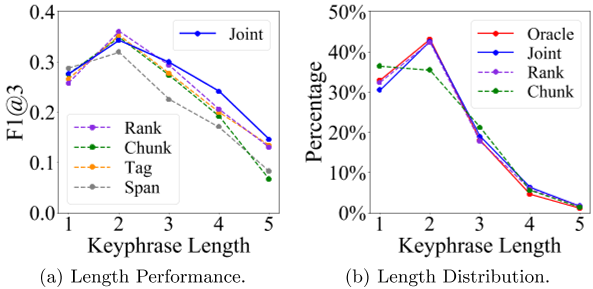
图1:。关键词长度分析。图1(a)展示了F1@3不同关键短语长度下OpenKP上不同神经KPE方法的得分。图1(b)展示了JointKPE(联合)预测的关键短语的长度分布及其两个删减版本:仅信息排名(Rank)和仅关键短语组块(Chunk)。序列标记和Span提取方法分别缩写为Tag和Span。
5结果和分析
在本节中,我们将介绍JointKPE的评估结果,并进行一系列分析和案例研究,以研究其有效性。
表2:。OpenKP数据集中实体和非实体关键短语的示例。

5.1总体精度
联合KPE和基线的评估结果如表1所示。
总的来说,JointKPE在开放领域和科学KPE基准上的所有评估指标上都稳定地优于所有基线。与最好的基于功能的KPE系统PROD[39]和Maui[22]相比,JointKPE的性能大大优于它们。JointKPE的表现也优于强大的神经基线BLING-KPE[39]和CDKGEN[8],后者是之前OpenKP和KP20k的最新技术;他们的F1@3和F1@5分别提高了22.8%和7.9%。
这些结果证明了JointKPE的有效性。
此外,即使使用相同的预训练模型,JointKPE仍然比那些主要基于局部特征的神经KPE方法(如SKE Base Cls[25]、跨度提取和序列标记)取得更好的性能。这些结果表明,JointKPE的有效性,除了从预先训练的模型中获得的好处外,还源于它在提取关键短语时结合局部和全局特征的能力。
正如JointKPE的消融结果所示,如果没有信息排名或关键词组块,其准确性会下降,尤其是在开放域OpenKP数据集上没有信息排名的情况下。结果表明,多任务学习的好处以及在开放域关键词提取场景中捕获全局信息的关键作用。
此外,JointKPE的有效性可以通过SpanBERT【15】和RoBERTa【19】的初始化进一步提高,这两个BERT变体具有更新的预训练策略,这表明JointKPE能够利用更好的预训练模型的优势。此外,我们观察到,由于信息排名性能的提高,我们的方法在RoBERTa的基础上取得了更显著的改进,而SpanBERT和RoBERTa对关键短语组块任务的改进相对接近5。
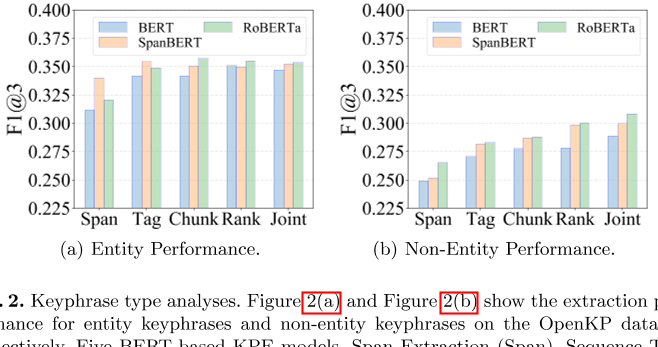
图2:。关键词类型分析。图2(a)和图2(b)分别显示了OpenKP数据集上实体关键短语和非实体关键短语的提取性能。比较了五种基于BERT的KPE模型:Span提取(Span)、序列标记(Tag)、两种消融版本(Chunk和Rank)和JointKPE(Joint)的完整模型。
5.2 w.r.t.关键词不同长度的表现
开放域KPE中的一个挑战是长关键字提取场景【39】。
在本实验中,我们使用开放域OpenKP数据集比较了JointKPE和其他基于BERT的KPE方法在提取不同长度的关键短语方面的行为和效果。
如图1(a)所示,所有神经KPE方法对短关键短语的提取性能都优于长关键短语。然而,与其他方法相比,JointKPE对不同长度的关键短语具有更稳定的提取能力,并且在预测更长的关键短语(长度≥ 4) 。
值得注意的是F1@3JointKPE的得分比它的两个被删减的版本,Rank(仅信息性排名)和Chunk(仅关键词组块)高17%,关键词长度为4。这些结果表明,JointKPE对短语性和信息性的联合建模有助于缓解开放域抽取场景中的长关键字挑战。
图1(b)进一步说明了JointKPE预测的关键短语的长度分布及其两个被删除的版本,Chunk和Rank。仅使用关键词组块任务(Chunk)[39]训练的ablated模型(训练的)倾向于预测更多的单字短语。相比之下,我们的完整模型(联合)及其仅排名版本(Rank)预测的关键短语长度分布更符合地面真实长度分布。结果进一步表明,全局捕获信息量可以指导神经提取器更好地确定真值关键短语的边界。
5.3 w.r.t.关键词不同类型的表现
关键短语和实体之间的主要区别之一是,并非所有关键短语都是知识图实体,尤其是在开放域KPE场景中。根据我们对OpenKP的观察,大约40%的地面真相关键短语不是实体,这占了很大一部分。如表2所示,非实体关键短语通常具有更高的变体形式,从上下文中识别可能更复杂。本实验研究了联合KPE对非实体关键短语的有效性,其中使用了其两个烧蚀版本和另两个基于BERT的KPE基线作为比较。
图2(a)和图2(b)说明了实体关键短语和非实体关键短语上基于BERT的不同KPE方法的性能,其中实体由CMNS链接器识别【38】。毫不奇怪,所有带有预训练模型的KPE方法都能很好地提取实体关键短语。实体风格的关键短语具有独特和独立的存在,很容易从上下文中识别出来。此外,预先训练的模型可能已经捕获了实体信息,其上的简单层可以有效地识别实体关键短语。
然而,在提取非实体关键短语时,所有方法的准确率都会急剧下降,这显然表明了在识别这种高度变异的关键短语时所面临的挑战。尽管存在挑战,JointKPE及其信息量排名版本(Rank)在预测非实体关键短语方面明显优于其他方法。结果表明,使用学习排名来捕获关键字短语候选的全局信息有助于克服非实体关键字短语提取的一些困难。
5.4案例研究
表3展示了从JointKPE及其OpenKP数据集的两个烧蚀版本中提取长关键字和非实体关键字的一些情况。
前两个案例显示了长关键字短语提取场景。在第一种情况下,所有三种方法都成功预测了双克关键词“walter lagraves”,但较长的关键词“蚊子控制板竞赛”仅由JointKPE提取。此外,JointKPE在第二种情况下成功地预测了较长的关键词“盈余线出口资格”,而其两个被删除的版本只提取了较短的一个“合规角”。
其余案例为非实体示例。与实体关键短语相比,非实体关键短语具有更多的可变形式,在给定文档的上下文中出现的频率可能较低,例如,第三种情况下为实体“消防港”和非实体“dv到笔记本电脑”,第四种情况下为实体“north country realty”和非实体“the beauty of the north”。这三种方法都成功地预测了实体关键短语,但非实体关键短语仅由JointKPE的完整版本提取。
6结论
本文提出了JointKPE,一种基于预先训练好的开放域KPE语言模型的多任务体系结构,它可以在提取关键短语时同时捕获局部短语和全局信息。我们的实验证明了JointKPE在开放领域和科学场景以及不同预训练模型上的有效性。综合实证研究进一步表明,JointKPE可以缓解以往神经KPE方法中倾向于较短和实体风格的关键短语的问题,并在不同长度和不同类型的关键短语上表现出更平衡的性能。
表3:。针对OpenKP的长关键字和非实体关键字的预测案例。基本真相关键短语在文件中加下划线。展示了JointKPE(Joint)及其两个烧蚀版本(Rank和Chunk)的前三个预测[行]。这三种方法都提取了蓝色的关键短语,而红色的关键短语只能通过JointKPE的完整版本进行预测。

确认书
本研究部分得到了国家自然科学基金(NSFC)61872074和61772122的资助;北京国家信息科学技术研究中心(BNR2019ZS01005)。
参考文献
1. Ainslie, J., Ontanon, S., Alberti, C., Cvicek, V., Fisher, Z., Pham, P., Ravula, A., Sanghai, S., Wang, Q., Yang, L.: ETC: encoding long and structured inputs in transformers. In: Proceedings of EMNLP. pp. 268–284 (2020)
2. Alzaidy, R., Caragea, C., Giles, C.L.: Bi-LSTM-CRF sequence labeling for keyphrase extraction from scholarly documents. In: Proceedings of WWW. pp. 2551–2557 (2019)
3. Boudin, F., Gallina, Y., Aizawa, A.: Keyphrase generation for scientific document retrieval. In: Proceedings of ACL. pp. 1118–1126 (2020)
4. Campos, R., Mangaravite, V., Pasquali, A., Jorge, A.M., Nunes, C., Jatowt, A.: A text feature based automatic keyword extraction method for single documents. In: Proceedings of ECIR. pp. 684–691 (2018)
5. Caragea, C., Bulgarov, F., Godea, A., Gollapalli, S.D.: Citation-enhanced keyphrase extraction from research papers: A supervised approach. In: Proceedings of EMNLP. pp. 1435–1446 (2014)
6. Dalvi, N., Machanavajjhala, A., Pang, B.: An analysis of structured data on the web. In: Proceedings of the VLDB Endowment. vol. 5, pp. 680–691 (2012)
7. Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of NAACL. pp. 4171–4186 (2019)
8. Diao, S., Song, Y., Zhang, T.: Keyphrase generation with cross-document attention. arXiv preprint arXiv:2004.09800 (2020)
9. El-Beltagy, S.R., Rafea, A.: KP-Miner: A keyphrase extraction system for english and arabic documents. Information systems 34 (1), 132–144 (2009)
10. El-Kishky, A., Song, Y., Wang, C., Voss, C.R., Han, J.: Scalable topical phrase mining from text corpora. In: Proceedings of the VLDB Endowment. vol. 8, pp. 305–316 (2014)
11. Florescu, C., Caragea, C.: anew scheme for scoring phrases in unsupervised keyphrase extraction. In: Proceedings of ECIR. pp. 477–483 (2017)
12. Hasan, K.S., Ng, V.: Automatic keyphrase extraction: A survey of the state of the art. In: Proceedings of ACL. pp. 1262–1273 (2014)
13. Jiang, X., Hu, Y., Li, H.: A ranking approach to keyphrase extraction. In: proceedings of SIGIR. pp. 756–757 (2009)
14. Jones, S., Staveley, M.S.: Phrasier: a system for interactive document retrieval using keyphrases. In: Proceedings of SIGIR. pp. 160–167 (1999)
15. Joshi, M., Chen, D., Liu, Y., Weld, D.S., Zettlemoyer, L., Levy, O.: SpanBERT: improving pre-training by representing and predicting spans. TACL 8 , 64–77 (2020)
16. Kim, S.N., Baldwin, T.: Extracting keywords from multi-party live chats. In: proceedings of PACLIC. pp. 199–208 (2012)
17. Kim, S.N., Medelyan, O., Kan, M.Y., Baldwin, T.: Automatic keyphrase extraction from scientific articles. Language resources and evaluation 47 (3), 723–742 (2013)
18. Liu, J., Shang, J., Han, J.: Phrase mining from massive text and its applications. Synthesis Lectures on Data Mining and Knowledge Discovery 9 (1), 1–89 (2017)
19. Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V.: RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692 (2019)
20. Liu, Z., Huang, W., Zheng, Y., Sun, M.: Automatic keyphrase extraction via topic decomposition. In: Proceedings of EMNLP. pp. 366–376 (2010)
21. Liu, Z., Li, P., Zheng, Y., Sun, M.: Clustering to find exemplar terms for keyphrase extraction. In: Proceedings of EMNLP. pp. 257–266 (2009)
22. Medelyan, O., Frank, E., Witten, I.H.: Human-competitive tagging using automatic keyphrase extraction. In: Proceedings of EMNLP. pp. 1318–1327 (2009)
23. Meng, R., Zhao, S., Han, S., He, D., Brusilovsky, P., Chi, Y.: Deep keyphrase generation. In: Proceedings of ACL. pp. 582–592 (2017)
24. Mihalcea, R., Tarau, P.: TextRank: Bringing order into text. In: Proceedings of EMNLP. pp. 404–411 (2004)
25. Mu, F., Yu, Z., Wang, L., Wang, Y., Yin, Q., Sun, Y., Liu, L., Ma, T., Tang, J., Zhou, X.: Keyphrase extraction with span-based feature representations. arXiv preprint arXiv:2002.05407 (2020)
26. Papagiannopoulou, E., Tsoumakas, G.: A review of keyphrase extraction. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 10 (2), e1339 (2020)
27. Porter, M.F.: An algorithm for suffix stripping. Program pp. 211–218 (1980)
28. Pudota, N., Dattolo, A., Baruzzo, A., Ferrara, F., Tasso, C.: Automatic keyphrase extraction and ontology mining for content-based tag recommendation. international Journal of Intelligent Systems pp. 1158–1186 (2010)
29. Qazvinian, V., Radev, D., Özgür, A.: Citation summarization through keyphrase extraction. In: Proceedings of COLING. pp. 895–903 (2010)
30. Rousseau, F., Vazirgiannis, M.: Main core retention on graph-of-words for singledocument keyword extraction. In: Proceedings of ECIR. pp. 382–393 (2015)
31. Sun, Z., Tang, J., Du, P., Deng, Z.H., Nie, J.Y.: DivGraphPointer: A graph pointer network for extracting diverse keyphrases. In: Proceedings of SIGIR. pp. 755–764 (2019)
32. Tomokiyo, T., Hurst, M.: A language model approach to keyphrase extraction. In: Proceedings of ACL. pp. 33–40 (2003)
33. Turney, P.D.: Learning algorithms for keyphrase extraction. Information retrieval 2 (4), 303–336 (2000)
34. Wan, X., Xiao, J.: CollabRank: towards a collaborative approach to singledocument keyphrase extraction. In: Proceedings of COLING. pp. 969–976 (2008)
35. Wang, Y., Fan, Z., Rose, C.: Incorporating multimodal information in open-domain web keyphrase extraction. In: Proceedings of EMNLP. pp. 1790–1800 (2020)
36. Witten, I.H., Paynter, G.W., Frank, E., Gutwin, C., Nevill-Manning, C.G.: KEA: Practical automated keyphrase extraction. In: Design and Usability of Digital libraries: Case Studies in the Asia Pacific, pp. 129–152 (2005)
37. Wolf, T., Chaumond, J., Debut, L., Sanh, V., Delangue, C., Moi, A., Cistac, P., Funtowicz, M., Davison, J., Shleifer, S., et al.: Transformers: State-of-the-art natural language processing. In: Proceedings of EMNLP. pp. 38–45 (2020)
38. Xiong, C., Callan, J., Liu, T.Y.: Bag-of-entities representation for ranking. In: Proceedings of ICTIR. pp. 181–184 (2016)
39. Xiong, L., Hu, C., Xiong, C., Campos, D., Overwijk, A.: Open domain web keyphrase extraction beyond language modeling. In: Proceedings of EMNLP. pp. 5178–5187 (2019)
40. Zhang, Y., Li, J., Song, Y., Zhang, C.: Encoding conversation context for neural keyphrase extraction from microblog posts. In: Proceedings of NAACL. pp. 1676– 1686 (2018)
41. Zhang, Y., Chang, Y., Liu, X., Gollapalli, S.D., Li, X., Xiao, C.: MIKE: keyphrase extraction by integrating multidimensional information. In: Proceedings of CIKM. pp. 1349–1358 (2017)
















 3082
3082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









