







1、BP人工神经网络
人工神经网络(artificialneuralnetwork,ANN)指由大量与自然神经系统相类似的神经元联结而成的网络,是用工程技术手段模拟生物网络结构特征和功能特征的一类人工系统。神经网络不但具有处理数值数据的一般计算能力,而且还具有处理知识的思维、学习、记忆能力,它采用类似于“黑箱”的方法,通过学习和记忆,找出输入、输出变量之间的非线性关系(映射),在执行问题和求解时,将所获取的数据输入到已经训练好的网络,依据网络学到的知识进行网络推理,得出合理的答案与结果。
岩土工程中的许多问题是非线性问题,变量之间的关系十分复杂,很难用确切的数学、力学模型来描述。工程现场实测数据的代表性与测点的位置、范围和手段有关,有时很难满足传统统计方法所要求的统计条件和规律,加之岩土工程信息的复杂性和不确定性,因而运用神经网络方法实现岩土工程问题的求解是合适的。
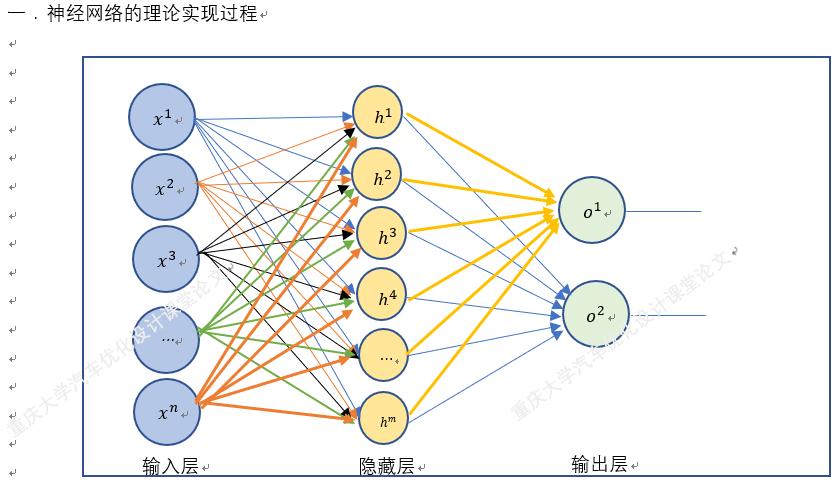
BP神经网络模型是误差反向传播(BackPagation)网络模型的简称。它由输入层、隐含层和输出层组成。网络的学习过程就是对网络各层节点间连接权逐步修改的过程,这一过程由两部分组成:正向传播和反向传播。正向传播是输入模式从输入层经隐含层处理传向输出层;反向传播是均方误差信息从输出层向输入层传播,将误差信号沿原来的连接通路返回,通过修改各层神经元的权值,使得误差信号最小。
BP神经网络模型在建立及应用过程中,主要存在的不足和建议有以下四个方面:
(1)对于神经网络,数据愈多,网络的训练效果愈佳,也更能反映实际。但在实际操作中,由于条件的限制很难选取大量的样本值进行训练,样本数量偏少。
(2)BP网络模型其计算速度较慢、无法表达预测量与其相关参数之间亲疏关系。
(3)以定量数据为基础建立模型,若能收集到充分资料,以定性指标(如基坑降水方式、基坑支护模式、施工工况等)和一些易获取的定量指标作为输入层,以评价等级作为输出层,这样建立的BP网络模型将更准确全面。
(4)BP人工神经网络系统具有非线性、智能的特点。较好地考虑了定性描述和定量计算、精确逻辑分析和非确定性推理等方面,但由于样本不同,影响要素的权重不同,以及在根据先验知识和前人的经验总结对定性参数进行量化处理,必然会影响评价的客观性和准确性。因此,在实际评价中只有根据不同的基坑施工工况、不同的周边环境条件,应不同用户的需求,选择不同的分析指标,才能满足复杂工况条件下地质环境评价的要求,取得较好的应用效果。
谷歌人工智能写作项目:小发猫

2、基于BP 神经网络的环境影响评价方法
基于BP神经网络的环境影响评价模型的建立过程如下:
(1)样本选择
根据表3.7、表3.8、表3.9提取建模所需的样本数据(表3.11)
表3.11 8组基坑环境影响工程数据
(2)BP神经网络结构设计
对于BP网络,对于任何在闭区间内的一个连续函数都可以用单隐层的BP网络逼近,因而一个三层BP网络就可以完成任意的n维到m维的映射bp神经网络的评价指标。根据网络结构简单化的原则,确定采用三层BP网络结构,即输入层为支护刚度、岩土性质、降水方式、水文地质边界、基坑侧壁状态、边载分布、后续使用年限、基础型式和差异沉降δ九个参数,输出层为环境等影响级,隐层层数为1层。隐层的神经元数目选择是一个十分复杂的问题,往往需要根据设计者的经验和多次实验来确定,因而不存在一个理想的解析式来表示。隐单元的数目与问题的要求,与输入、输出单元的数目有直接的关系。隐单元数目太多会导致学习时间过长,误差不一定最佳,也会导致容错性差、不能识别以前没有看到的样本,因此一定存在一个最佳的隐单元数。研究通过一次编程比较了隐层神经元个数分别为5、10、15、20、25、30、40时训练速度及检验精度。
(3)网络训练及检验
BP网络采用梯度下降法来降低网络的训练误差,考虑到基坑降水地面沉降范围内沉降量变化幅度较小的特点,训练时以训练目标取0.001为控制条件,考虑到网络的结构比较复杂,神经元个数比较多,需要适当增加训练次数和学习速率,因此初始训练次数设为10000次,学习速率取0.1,中间层的神经元传递函数采用S型正切函数tansig,传输函数采用logsig,训练函数采用trainlm,分别抽取表3.11中的7组数据作为训练样本,剩余1组作为检验样本。使用MATLAB6.0编程建立基于BP神经网络的基坑降水环境影响评价模型,考虑到样本量较小,预测结果不稳定,取预测20次评价结果的平均值作为最终评价结果。经试算最终确定当隐层神经单元为10,结果如下:
表3.12 基坑降水环境影响评价模型检验结果
结果表明基于BP神经网络的基坑降水环境影响评价结果大部分与实际监测结果相符,部分结果偏于危险。
3、神经网络BP模型
一、BP模型概述
误差逆传播(Error Back-Propagation)神经网络模型简称为BP(Back-Propagation)网络模型。
Pall Werbas博士于1974年在他的博士论文中提出了误差逆传播学习算法。完整提出并被广泛接受误差逆传播学习算法的是以Rumelhart和McCelland为首的科学家小组。他们在1986年出版“Parallel Distributed Processing,Explorations in the Microstructure of Cognition”(《并行分布信息处理》)一书中,对误差逆传播学习算法进行了详尽的分析与介绍,并对这一算法的潜在能力进行了深入探讨。
BP网络是一种具有3层或3层以上的阶层型神经网络。上、下层之间各神经元实现全连接,即下层的每一个神经元与上层的每一个神经元都实现权连接,而每一层各神经元之间无连接。网络按有教师示教的方式进行学习,当一对学习模式提供给网络后,神经元的激活值从输入层经各隐含层向输出层传播,在输出层的各神经元获得网络的输入响应。在这之后,按减小期望输出与实际输出的误差的方向,从输入层经各隐含层逐层修正各连接权,最后回到输入层,故得名“误差逆传播学习算法”。随着这种误差逆传播修正的不断进行,网络对输入模式响应的正确率也不断提高。
BP网络主要应用于以下几个方面:
1)函数逼近:用输入模式与相应的期望输出模式学习一个网络逼近一个函数;
2)模式识别:用一个特定的期望输出模式将它与输入模式联系起来;
3)分类:把输入模式以所定义的合适方式进行分类;
4)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









