







HashMap
1、null作为key只能有一个,作为value可以有多个
2、容量:
- 1.7:默认16
- 1.8:初始化并未指定容量大小,第一次put才初始化容量
3、负载因子 默认0.75,扩容触发:元素个数 > 容量 * 负载因子,扩容
4、哈希算法:
- 首先获取key的哈希值h
- 将h高16位和低16为进行异或运算,让高16位参与hash,减少哈希冲突
5、底层结构:
- 1.7:数组+链表
- 1.8:数据+链表/红黑树
为什么引入链表
HashMap底层是数组,当进行put操作时,会进行hash计算,判断元素位置。当多个元素在同一个数组位置时,会引起hash冲突,因此引入链表,解决hash冲突
为什么jdk1.8会引入红黑树
当链表长度大于8时,遍历查找效率较慢,故引入红黑树
链表长度>8,且数组长度>64,才变成红黑树
为什么一开始不就使用红黑树?
红黑树相对于链表维护成本大,红黑树在插入新数据之后,可能会通过左旋、右旋、变色来保持平衡,造成维护成本过高,故链路较短时,不适合用红黑树
HashMap的底层数组取值的时候,为什么不用取模,而是&
i = (n - 1) & hash,计算机运算时,&比取模运算快
数组的长度为什么是2的次幂
1、减少hash冲突
数据均匀分布,可以减少hash冲突,所以使用hash%n可以最大程度的平均分配。当n为2的次幂时,(n-1)&hash=hash%n
2、&运算速度比%快,Java中快10倍左右
3、保证索引值在capacity中不会超出数组长度
如果指定数组的长度不为2的次幂,就破坏了数组的长度是2的次幂的这个规则吗
不会的,HashMap 的tableSizeFor方法做了处理,能保证n永远都是2的次幂
tableSizeFor(initialCapacity)
6、put方法流程:
-
计算key的哈希值
-
判断数组是否为空
-
- 是:扩容,进行初始化
- 否:查找哈希值对应的数组下标
-
判断下标元素是否为空
-
- 是:创建新元素
- 否:步骤4
-
判断底层结构是否是红黑树
-
- 是:执行红黑树新增逻辑
- 否:说明是链表结构,新增元素到链表尾
-
判断链表属性,链表长度是否≥8,数组长度是否≥64
-
- 是:链表转红黑树,判断size≥threshold,是执行扩容
- 否:执行扩容逻辑
7、HashMap为什么线程不安全
- HashMap扩容的时候,是会将原先的链表迁移至新的链表数组中,在迁移过程中多线程情况下会有造成链表的死循环情况(JDK1.7之前的头插法)
- 在多线程插入的时候也会造成链表中数据的覆盖导致数据丢失
8、解决哈希冲突的方法
- 链地址法:冲突值链接成一个链表,HashMap
- 线性探测法:发生冲突,继续向下遍历,直到找到空闲内置T,hreadLocal
- 再哈希法:冲突后,再使用一个新的哈希算法计算,直到不发生冲突
9、扩容:
1.7:
size>=threshold,且新建的Entry刚好落在一个非空的桶上,扩容为2倍容量
threshold=loadFactor*capacity
扩容过程:先计算新的容量和threshold,再创建一个新hash表,最后将旧hash表中元素rehash到新的hash表中
1.8:(与1.7的区别)
- 第一次调用put方法,初始化扩容为16
- 插入数据时size>=threshold就扩容为原来的2倍(不管有没有空位都扩容,1.7是没有空位才扩容)
- 使用尾插法扩容(1.7是头插法扩容)
计划用HashMap存1k条数据,构造时传1000会触发扩容吗
HashMap 初始容量指定为 1000,会被 tableSizeFor() 调整为 1024;但是它只是表示 table 数组为 1024;负载因子是0.75,扩容阈值会在 resize() 中调整为 768(1024 * 0.75)会触发扩容,如果需要存储1k的数据,应该传入1000 / 0.75(1333)。tableSizeFor() 方法调整到 2048,不会触发扩容
用HashMap存1w条数据,构造时传10000会触发扩容吗
当我们构造HashMap时,参数传入进来 1w,经过 tableSizeFor() 方法处理之后,就会变成 2 的 14 次幂 16384负载因子是 0.75f,可存储的数据容量是 12288(16384 * 0.75f)完全够用,不会触发扩容
ConcurrentHashMap
1、存储结构
1.7:segment数组+链表
segment默认16,默认最多支持16个线程并发,并且segment初始化后不能更改
1.8:Node数组+链表/红黑树
2、锁:
1.7:分段锁
1.8:Synchronized+CAS,锁粒度更小
线程安全问题
1、HashMap线程不安全
- HashMap扩容的时候,是会将原先的链表迁移至新的链表数组中,在迁移过程中多线程情况下会有造成链表的死循环情况(JDK1.7之前的头插法)
- 在多线程插入的时候也会造成链表中数据的覆盖导致数据丢失
线程安全:HashTable、ConcurrentHashMap
2、HashTable线程安全
问题:实现线程安全的代价大,所有可能产生竞争的方法里都加上了synchronized,导致在出现竞争时,只能一个线程进行操作,其他线程都需要阻塞等待当前取到锁的线程执行完成
3、ConcurrentHashMap线程安全
1.7:分段锁,对每一个segment加锁
数组有大数组segment,小数组HashEntry,HashEntry的每个元素是一个链表,加锁是通过给Segment加ReentrantLock重入锁来保证线程安全
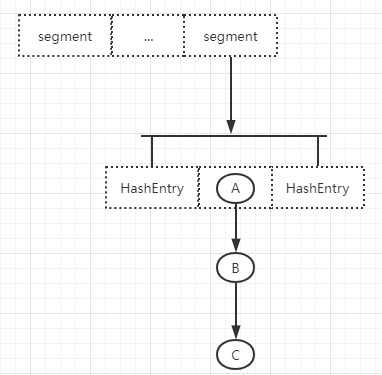
get():HashEntry中采用volatile来修饰HashEntry的当前值和next元素的值,所以在获取数据时不需要加加锁,大大提高了执行效率
put():先尝试获取锁(tryLock()),如果获取失败,说明存在竞争,那么通过scanAndLockForPut()方法自旋,当自旋次数达到MAX_SCAN_RETRIES时会执行阻塞锁,直到获取锁成功
1.8:采用CAS+synchronized的方法来保证线程安全
put():
1、计算出hash值
2、判断当前数据结构是否从未放过数据,即是否未初始化,为空则先执行初始化
3、通过key的hash判断当前位置是否为null
4、如果当前位置为null,则通过CAS写入,如果CAS写入失败,通过自旋保证写入成功
5、当前hash值等于MOVED(-1)时,需要进行扩容
6、当上面的内容都不满足时,采用synchronized阻塞锁,来将数据进行写入
7、如果数量大于TREEIFY_THRESHOLD(8),需要转化为红黑树
get():
1、根据key的hash寻找到具体的位置
2、如果是红黑树就按照红黑树的方式去查找数据
3、如果是链表就按照链表的方式去查找数据














 1309
1309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









