







前插入:
回调函数:回调函数是函数中调用函数指针指向的函数。
1. 结构体类型:结尾有
结尾要加“;” 加分号
匿名结构体类型变量:在最后加名字,只能用一次,只用一次才考虑

虽然p类型结构体内容和ss内容一样,但编译器认为他们不一样,匿名的只能用一次。
匿名结构体不能用指针存,会有警告,这里 ps = &ss,ss是匿名结构体。
自引用:自己要找到和自己同类型的数据

以上错误
结构体里面包含一个同类型结构体时,这种写法是错的,如上图,在main()中,定义一个Node类型,而这个node类型中又有一个node类型成员,这种写法是错误的,因为你该开多大空间的问题没有解决,所以当1想找2,应该把地址给它,这就不会产生连环调用的问题了,比如node中包含:数据域和指针域。
下面正确

类型重命名, stuct class写起来繁琐
即使重命名,struct内部也需要全写
重命名
typedef struct Node{
// 注意内部需要全写
struct Node* next;
}Node, *pNode;
在末尾加 *pNode相当于: struct Node*
普通结构体使用:

视频11
结构体的内存对齐
- 问题引入:上图中,结构体只是换了类型数据位置,大小就不一样了?
结构体这种对象,在内存中间开辟空间时,有内存对齐这种机制
结构体内存对齐
结构体存储规则:
- 规则1. 第一个成员在结构体变量地址偏移量为0的地址,C1只占右侧0开始1个字节
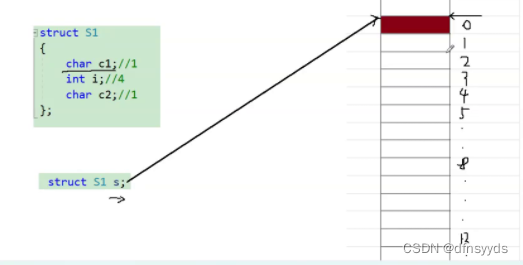
- 规则2. 其他成员变量开始,要对齐到某个数字(对齐数)的整数倍地址处,编译器默认对其书和该成员大小的较小值。
分析上图i,VS编译器默认大小为8,Linux下没有默认对齐数,自身大小就是对齐数,int i是4,所以选4,向下找偏移量为4(对齐数的整数倍)的位置,
存法如下:
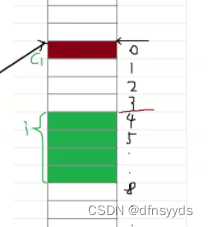
c2只占一个字节,但它只能往下走,内存0到4字节之间空间只能浪费了,虽然也给了s,但没有使用,只能c2寸下面,如下图,总共占了9个字节
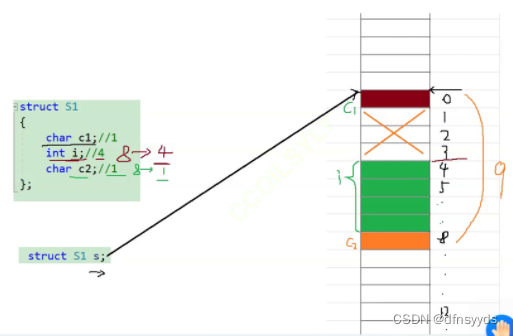
但是最终结果是12,而不是9,因为有规则3::每个成员最大对齐数,为4 - 规则3: 结构体的总大小应该为4的倍数,12,如下图
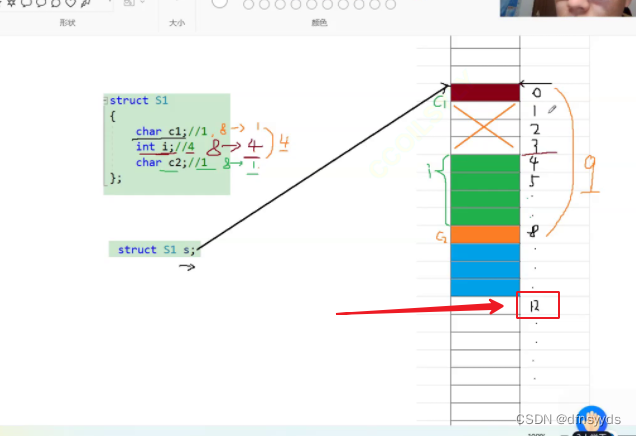
总之,开辟的空间如下,但是蓝色部分都浪费掉了,所以最终大小为12字节,如下
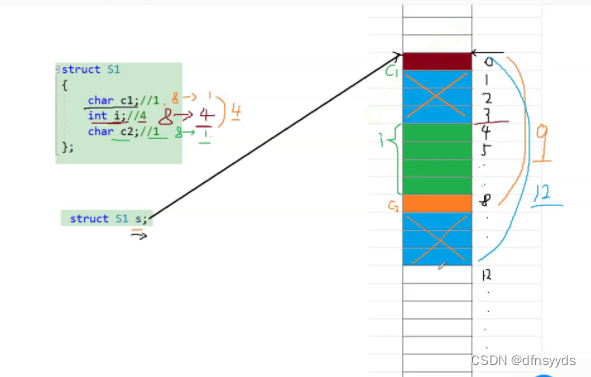
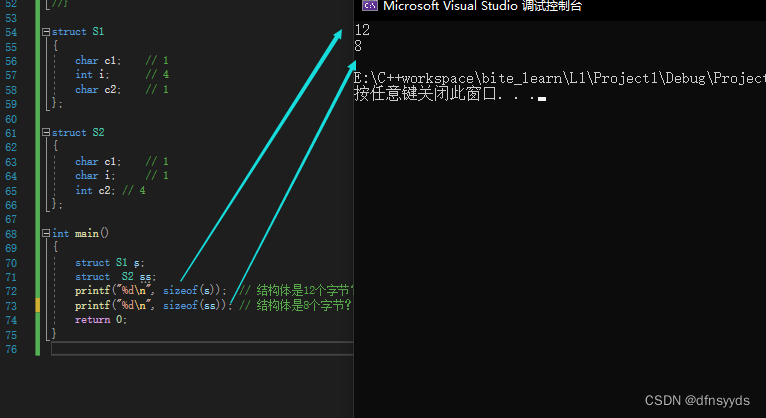
分析S2:
char到第一个位置,而第二个也是char,对齐数是min(编译器默认8,1)=1,地址需要是对齐数整数倍位置,所以在1存,然后int i对齐数是4,对齐数的整数倍所以选地址4处开始存int,最终到8之前,所以占字节为8,它也浪费了2个字节空间

分析S3:
即使32位系统下的double也占8个字节大小
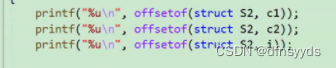
offsetof -宏:计算结构体成员相对于起始位置的偏移量(结构名,成员变量名)
#include<stddef.h>
使用如下图:放结构体名+变量名
- 其实还有规则4:嵌套了结构体,对齐到自己最大对齐数(内部元素中的对齐数中找)的整数倍处—,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
分析S4:

如上图,S3对齐数为S3中最大对齐数(double的对齐数为8),
如下图:S4占32,第二个S3占16,且从8开始,再加最后double8,总共占32
这里是引用

为什么会存在内存对齐
- 平台原因,某些硬件平台读取数据不是可以访问任意地址数据,只能在某些地址处取某些特定类型数据,否则抛出硬件异常。
- 性能原因:为了处理器读取方便,未对齐,处理器读取内存需要访问两次

从性能方面解释:如图,若不对齐,i需要读取两次,上面画了两次红色框,下面读i只要1次,如下:
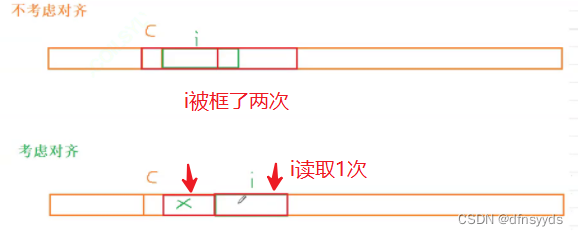
为节省空间,设计结构体时:为了既要对齐,又要节省空间,让占用空间小的成员尽量集中在一起,如开头引入两个结构体,让两个成员char连着放。
也能修改默认对齐数:
pragma pack(4) 没有; 将按4对齐
结构体传参
最基本调用: struct Stu* s = &s1; 直接通过指针调用:s->num…
建议通过指针接受参,因为传参效率高,如下:

拿结构体类型本身S接收参数,调用使用 S点
拿结构体指针* S接收参数,调用使用S-> S箭头(箭头是指针用的)
尽量传结构体地址,大小只为4,效率更高
位段:位说的是二进制位,这种写法需要考虑情况允许

例子:
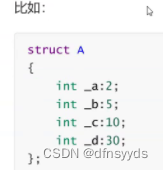
上面_a占2个bit,比特位,_b占5个比特位,这个A下来只占8个字节,但是
这种需要考虑是否能满足需求,比如_a:2,占两个比特位,只能表示4个数,a只有4种情况,才敢考虑用:2;
且它是一种节省空间类型,所以不存在对齐,对齐是为了时间,位段不要在意时间,以空间优先。
- 位段内存分片

这个位段元素大小总共加起来不到2字节,但实际占8字节,下面分析为什么占8:

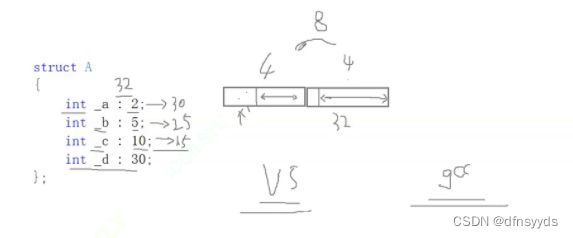
一开始,因为是int a,int一次开辟4字节,32个位,32给了a、b、c,剩余15位。
之后还有30个位,一定需要新开辟空间,int类型d,所以开辟4字节,且是否使用之前剩余15,还是全放在后面新的空间中,这里都可以,C语言没有明确规定。
C语言没有明确规定,某一片空间内剩余如果不够下一个数据存,是否会占用剩余再开新空间,或者不用这片剩余直接全存在新开辟空间种,且位段不跨平台,在不同编译器上有所差异。
标准也没有规定开辟的空间的使用顺序,先用低位还是高位,给a b用完还剩一个比特位,(没有规定,视频说暂时先浪费掉)所以,到c再开辟了一个char字节,即1字节,而C开辟的也剩下3个位,d需要再开一个字节,总共用3字节,但是其实,a开辟和c开辟的剩余4,够d存,但是最后查vs结果,占了3字节,说明vs的规则是,一片连续空间放不下剩余数据,就开辟新的空间,不会去扣让多个字节剩余空间位加起来

位段跨平台问题:
- 不跨平台,不知道有符号还是无符号
- 位段中最大位数目不能确定
- 开辟一片空间,从左向右使用还是从右向左,没有规定
- 第一个位段剩余的位不够时,是舍弃还是利用,也不确定

位段应用在ip数据包

枚举
结构体给值,就会直接打印值,不给值打印会打印按顺序的值。
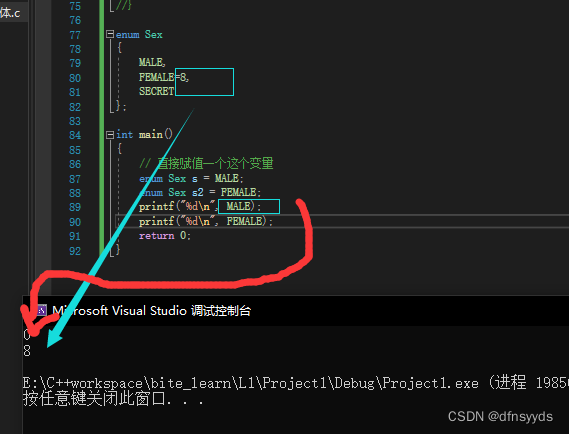
上面给FEMALE=3,是初始化,不是赋值。
枚举类型有严格检查机制,定义枚举变量只能给枚举类下的值,不能给其他值:
enum Color = RED;

联合union:一般称联合体或共用体
联合体内数据成员共用一片内存空间,所以下面打印地址都一样。因为它两个成员,一般同一时间只使用一个数据成员,所以不会有影响,它内部成员只能存在一个,只用一个。
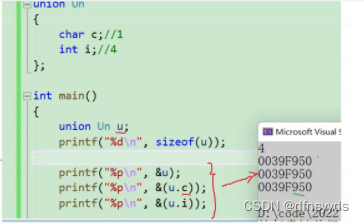
利用联合体判断大端小端:返回的c占1个字节,如果小端,前面1个字节有值,为0则为大端

联合体占内存大小:理论是数据成员中较大的,但结果为8,因为要考虑对齐
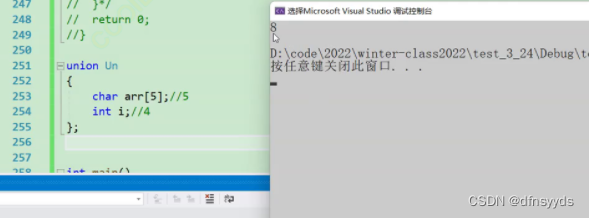
分析:
如果成员是数组,看数组成员,按照数组成员大小对齐。所以arr[5] 对齐数为1
而i 对齐数为4,但是4又不够上面的数组5,所以选8,够arr【5】又能对齐i
同一类型,再一个例子:
short数组每个成员大小为2
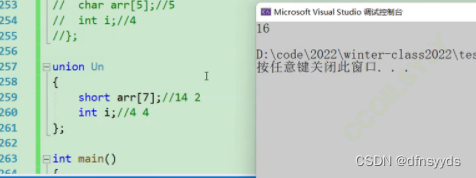
联合体内部数组对齐数:1,int i对齐数:4,选4为对齐数,最小16够放arr[7]
所以结果是16
写一个宏,计算结构体中某变量对于首地址的偏移














 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









