










Ceph——统一的分布式存储系统

1.存储设备有哪些?
知识回顾。
#存储设备有哪些?
DAS 直接骨架存储: IDE, SATA, SCSI, SASS, USB (类似这种直连的存储设备)
NAS 网络骨架存储: NFS, CIFS (类似这种网络存储设备,这种是网络文件系统,大多数都是文件系统接口,)
SAN 村粗局域网络: 与NAS不同的是,SAN提供给客户端主机使用的接口是以“块”级别的。 SAN存储结构中大多使用的是SCSI协议,这个和tcp协议很像,但是这个scsi只用来进行存取操作。延申到。FC SAN, iSCSI 这两种协议。 FC SAN借助分布式光纤通道传输SCSI协议。 iSCSI是利用internet来传输SCSI协议。因为SCSI自身只能用SCSI线传输,只能传一两米而已,所以才有后面的延申。
#
一般文件系统都不会在节点级冗余会在分片级别冗余。
2.一部分文件系统介绍
分布式存储1: 分布式文件存储HDFS =======================================================
全称:hadoop distributed fileSystem
他是山寨谷歌的GFS而来,是根据谷歌的一篇论文,开源社区使用java语言重新实现了一份。
淘宝根据HDSF有进行了二次开发,开发了TDFS,用来存储海量的图片数据。
#这种分布式文件系统的缺点之一是,读写受限, 虽然可以随机的读,但是只能顺序的写,甚至早期的HDFS不支持修改操作,追加都不行,后来允许了追加。所以导致应用受限。
#HDFS提供的是一个文件系统接口。 在分布式系统中最为常见。
分布式存储2:分布式对象村粗 =======================================================
#背景:
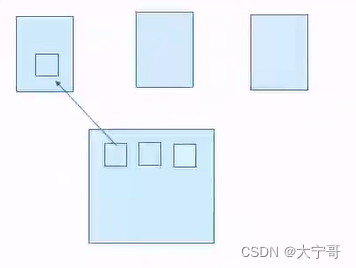
因为有些应用程序确实使用的不应该是文件系统接口。 例如KVM虚拟机启动的时候需要一个磁盘镜像文件,这个磁盘镜像可以直接用在设备上。如果放在文件里保存,这个文件就是被虚拟化成磁盘使用的,这样就不好了,有可能都不适用。而直接存储镜像文件,那么就可以接入裸设备过来用啦。
另外,如果在一个分布式的空间中(有很多主机),很多个主机上有可能运行很多个KVm虚拟机, 主机可以把自己的存储系统虚拟成为一个个块,例如在一个块中保存一个虚拟镜像,那么这个块就可以直接当成磁盘用的。
分布式对象存储示意图。
3.什么是ceph?
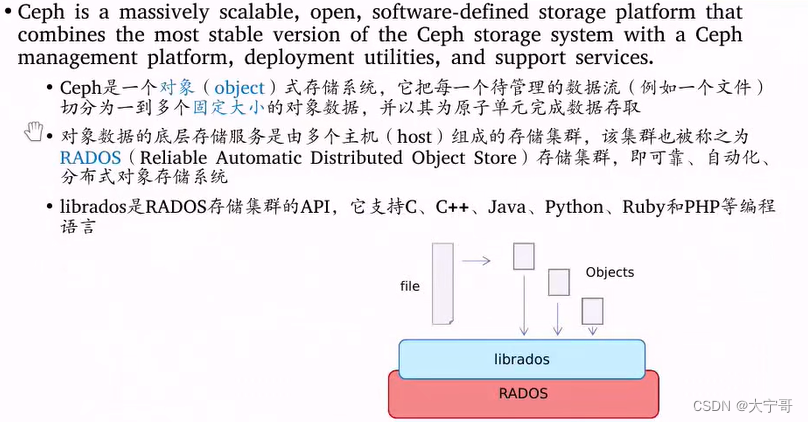
1. ceph 就是一个分布式存储服务。且是一个分布式对象存储。
2. 他把每一个待管理的数据流(例如一个文件)切分为若干个固定大小的对象数据,并且以其为原子单元完成数据存储。
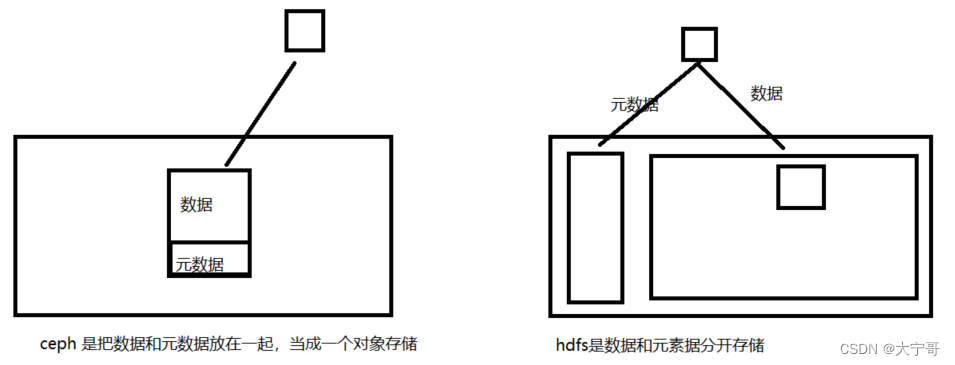
#对象自身会自带元数据: 就是说在ceph中,每个数据是当成一个对象(或者说)来存的, 每个对象包含数据部分和元数据部分,既就是说数据和元数据是在一起存的。也就是说每个数据流或者数据自带数据和元素据【下图1】。 这里和hdfs不一样,hdfs是数据与元素据分开存储的。
#这就是为什么每一个数据流(例如一个文件)就是一个对象: 因为其中的数据包含数据和元素据 也就是一个完整的数结构。每一个对象有自我管理的全部内容。
#ceph将一个待管理的数据流(例如一个文件)切分为若干个固定大小的对象数据 : 也就是说被切分后的所有对象数据的大小都是一样的,且这个大小是可以配置的,默认是4M, 因此如果一个文件小于4M,则他也需要4M的对象来存储。
#在ceph上,每一个对象都是一个基础的原子管理单元。 这个有点类似于k8s中的pod, 基础单元,也就是不可再切分单元。
图1: ceph 与 hdfs 对文件存储的结构差异。
3.对象数据怎么存?-> 对象数据的底层存储服务是由多个主机(host)组成的存储集群,该集群被成为RADOS(Reliable Automatic Distributed Object Store)存储集群。既 可靠、自动化、分布式 对象存储系统。
4.librados是RADOS存储集群的APi.支持很多编程语言。
6.解决了如hdfs存储访问速度的瓶颈。
#瓶颈:都知道hdfs访问文件系统的时候是先访问NameNode, 当有万个访问请求同时访问hdfs文件系统时候,那么在这些访问都需要去访问NameNode,这就会造成访问的性能瓶颈。
#Ceph是如何解决这一块的访问瓶颈的?-> ceph在存一个对象到RADOS上时候,他不需要去查询自己要存储在哪里。 ceph使用‘类似于一致性hash计算逻辑’通过对数据进行计算hash从而知道数据存写应该在哪一台机子上。这样就避免了出现元数据中心的存在而成为性能的瓶颈。这里涉及到ceph的关键组件crush。 (crush: ceph内部用来通过计算的方式完成文件路由映射的计算算法。)
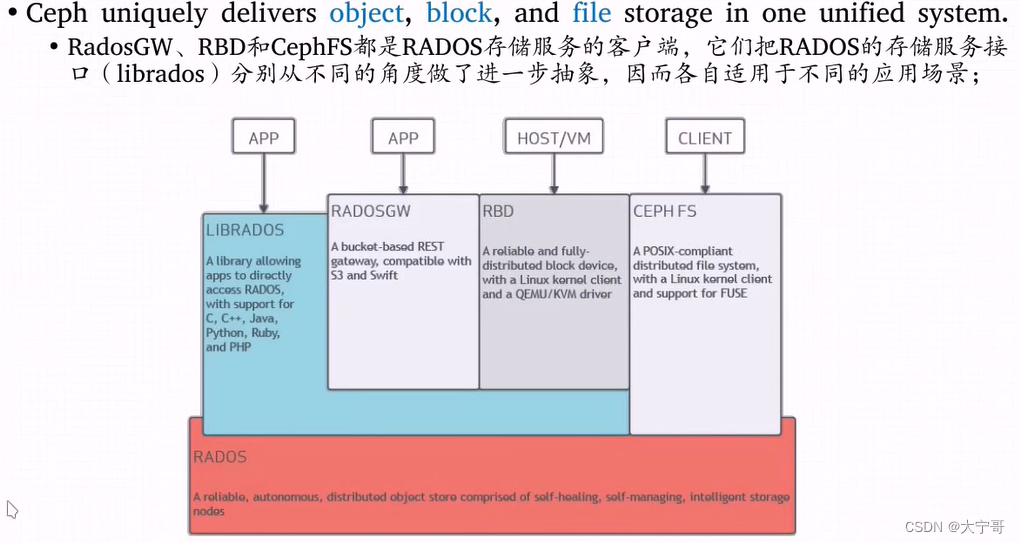
4. ceph在存储接口之上提供了几个抽象接口
ceph在抽象接口之上,提供了几个抽象接口,以便也能像传统意义上使用存储功能。
1.librados 就是前面提到的rados操作api, 支持多种语言的连接。
2.radosgw : 在librados基础之上开发的。他是一个更抽象的,可以跨互联网使用的一个对象存储。这里的对象和ceph内部的对象有区别。ceph内部的对象是固定大小的存储块,通常只在ceph集群中使用。而radosgw是针对的是文件作为一个对象,这个可以理解为在ceph上层。一个是面向内部的,一个是面向互联网的云存储服务。
3.rbd : 在librados基础之上开发的。将ceph提供的空间模拟成一个有一个独立的块设备使用,每个块设备就叫做一个image,每个块可就像一个传统的硬盘一样。
4.CEPH FS: 是独立于librados的 '文件系统' 比librados诞生还早,早期版本就有, 它不会有上面几种方式的性能瓶颈,因为他使用动态hash指数分割的方式,能够将一个目录树的子树分到不同服务器节点上分别提供服务。
#小结:
ceph 这个大一统的文件系统,不管你是要`文件系统接口`、`块存储接口`、`云存储接口` 它都有。 三大主流存储接口,ceph都有。
所以说ceph是新时代的sds(软件定义存储的代表性)的代表产品。
5.ceph存储
1.很容易相到ceph集群的存储空间是每个节点的本地磁盘,那么每个节点磁盘是以什么方式供给的呢?是文件系统吗?
#是存到节点的磁盘,但是不是存在节点磁盘格式化分区好的文件系统中,因为如果存在这 岂不是又存成文件了,这个是以前的ceph版本,后来ceph版本就直接存在物理磁盘上,ceph直接管理磁盘。
2. ceph有两种存储引擎
FileStore :文件存储引擎
BlueStore : 蓝擎。 (新版本)
RADOS存储空间是如何被调用、如何被管理的。
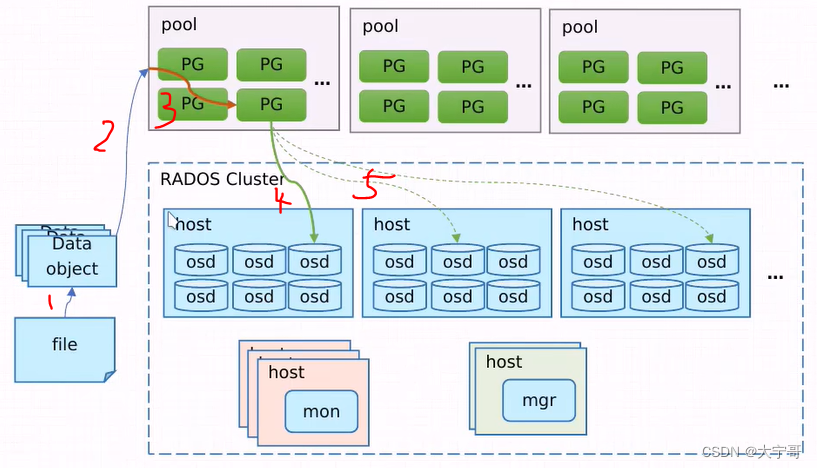
一、RADOS集群============================================================
1.RADOS 集群中有很多台主机。每个主机上有很多osd(osd(对象存储设备)bluestore模式下理解为磁盘,如果是filestore模式的话,这里ods就代表的是目录。)
2.集群元数据: 集群中还有mon(叫做元数据节点,这里别迷糊,不是说元数据不是分开的存储的吗?)。他是`监视器`。 监视器用来管理真个集群,例如:一共有多少个节点,每个节点上面有多少个osd,每一个osd是否健康。它会持有整个集群的运行图(运行状态), 它虽然叫元数据,但是它是集群元数据,而不是数据元数据。离开这个节点,集群内部就无法协调了,所以说我们要对这个节点服务做高可用。这个高可用它的内部直接使用 Paxos(帕克索斯)协议 来实现数据冗余,任何一个mon宕了 其他mon节点上都是副本。(如果每个节点上都可以写,写完同步给其他节点,这样就会出现同时写的冲突,这里它使用了分布式一致性协作一种。帕克索斯协议就可以避免这种情况。)
#mon 不太适合周期性采集数据监控操作,因为消耗的代价很大。但是监控是mon必须的,所以新版本引入mgr。(?)
3.mgr(manager 管理器): 这个组件专门用来维护查询操作,它先把查询缓存下来,如果有人来做监控,它可以及时响应。
二、一个文件如何存到RADOS集群?========================================
1.接入RADOS : 要接入RADOS集群,必须要通过一个客户端实现,要么是LIBRADOS、RADOSGW、RBD、CEPHFS 要么是借助LIBRADOS开发的。
2.把数据切割成对象 : 通过RADOS接口的API 切分成固定大小的存储对象。
3.这些存储对象存储到哪里?: 把大的空间,切分成若干个小的空间。 注意:所有对象都是存在同一个平面的,因为它没有目录这一说。 因此ceph把整个大空间(整个集群)切分为多个类似于分区的东西,这个东西称为存储池,存储池的大小取决于底层的存储空间,它和真正意义上的分区不一样, 每个存储池还可以进一步划分为名称空间。
4.每个存储池内部会有多个PG(归置组)存在。 注意:存储池、pg都是抽象的概念。
5.数据放到哪个osd上?: 数据最终放到哪一个osd上,是靠crush来完成的。
#当一个对象被存储时, 1.先向某个存储池请求 =》 2.把对象的名字进行一致性hash计算 =》 3.一致性hash计算完毕之后可以落到某个PG上 =》 把PG保存到OSD上(根据pool的冗余数量 以及pool的类型,知道足量的osd去存。) 注意:一个pg中的所有对象是放在同一个ods上的(一个pg中可能有多个对象的)
#上图画的有点不方便理解:应该是PG先把数据落在osd上,然后osd去同步两个副本(因为pg是个逻辑结构)
#补充,ceph也支持另外一种存储池叫做’纠删码池‘:
#自总:上图中数据在第2步(图上标记)已经写入磁盘了, 第2步(图上标记)的同时知道数据在那个存储池,第3步(图上标记)数据映射给PG, 第4步(图上标记)是数据映射给OSD, 第5步(图上标记)是osd上的数据拷贝。 以上这个2345 这个步骤过程就是由crush算法来完成的。
6.ceph存储集群
ceph(RADOS Cluster)上分为三类主机。
第一类主机:OSD服务主机 既正常的存储服务器节点。
第二类主机:监视器主机mon。 一般是奇数个。
第三类主机:manager主机,冗余一个个就够了。
#

ceph的4种类部署方式,需要用到哪一种就部署哪一种。
1. 通过api 直接连接librados
2. 通过http协议和radowgs接口交互
3. 通过librbd对rbd当成一个磁盘使用
4.
这4中接口和rados之间的交互都是离不开存储池 逻辑结构的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BSPZim0j-1666545674650)(大数据组件的安装&使用.assets/image-20221023235949825.png)]](https://img-blog.csdnimg.cn/edba7a98fb0a4aca8fb57b4dfe9c9d62.png)
1.各个组件功能
ceph有4个组件:OSDs,Monitros, Managers, MDSs
#OSDs
继续探讨OSD, OSD不是一个节点,假设一个节点上挂载10个盘,其中2个盘用来装操作系统,另外8个盘用来做OSD,每个盘做一个OSD。那么iu意味着这个服务器节点上就有6个osd。 ceph为了让每个ods被单独的管理,那么每个osd都有一个单独的守护进程。所以这台服务器上要运行8个osd进程,每一个进程用来专门管理一个osd。
1.OSD会有编号, OSD本身用来存数据,包括数据复制,数据回复,数据的重新平衡。
2.一个集权应该至少三个OSD 一主两从,确保高可用,不是三个主机昂。
3.设置故障率(也就是故障转移率,故障冗余率)
#Monitors
1.它是一个主机上运行的守护进程,这个守护进程扮演者监视整个集群所有组件状态的角色。整个集群运行图的持有者。
monitor map, manager map, OSD map, CRUSH map, PG map
2.认证功能。 客户端要连接RADOS集群的存储池之前都应该先去提供账号密码等信息过来认证。Monitor需要维护整个集群的认证,包括有多少用户名密码等。 以及集群组件之间的内部认证,这个认证协议叫做cephX协议。 Monitor用来维护认证信息,并且执行认证。
3.至少应该有3个Monitor,1)高可用备份 2)认证压力分摊。
#Managers
1.跟踪运行时候的指标数据。例如:每个节点的cpu使用率,osd磁盘剩余,集群的状态,存储空间利用率,当前的性能指标,节点的负载等。
2.Manager内建功能的扩展。
3.至少两台
#MDSs
1.为了ceph的文件系统而存在的守护进程。如果没有ceph文件系统,就可以不用启动了。
2.只有CEPH FS接口,就需要用这个进程。
补充: 如果是RBD模式是不需要单独为其开启一个守护进程的。如果是使用radowgs接口,则需要启动radowgs守护进程的。

2.管理节点

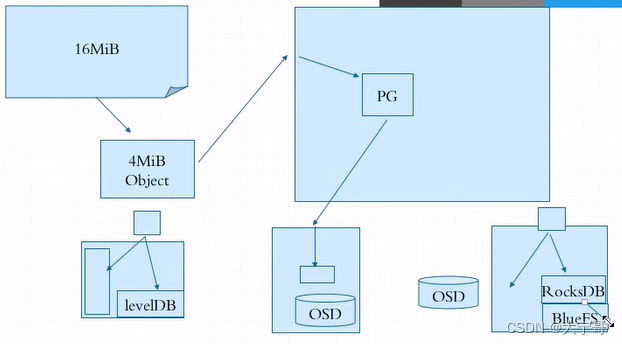
每一个对象有一个对象ID, 每个对象有他自己数据, 每个对象有其元数据。
例子说明:
#例如有一个文件a.txt 其大小为16M。
1.不管是通过哪一个接口,都要提交给ceph存储池,存储池会根据设置的默认对象切分大小(假设4M)进行切分。那么文件就会被切分为4个对象(16 = 4 * 4)。 每个对象都是分开独立管理的。
2.这四个对象都会被提交给RADOS, 首先会被提交给存储池,存储池映射给PG, PG然后映射给OSD, OSD然后又被备份到其他OSD上。
#fileStore: 对象的元数据存储在levelDB中了。 对象文件存在操作系统文件系统中的文件的元数据保存在文件系统的元数据区。
#blueStore:磁盘没有被格式化为文件系统。 每个osd进程直接把整个osd存储空间内部先做一个leavlDB用来存储对象的元数据(和fileStore这里一样。)
后来脸书对leavlDB做了升级,制作了RocksDB, 又因为当前OSD是一个裸设备不支持RockSDB,所以RocksDB下还有一个文件系统,为此ceph专门为他开了个问价系统 叫做BlueFS, 因此RocksDB+BlueFS 就是当今的BlueStore。 因此BlueStore模式存储对象的时候,对象数据本身存在OSD中,对象的元数据就存在了RocksDB中。
至此,关于ceph的理论入门部分学习完毕, 关于ceph理论方面还有很多复杂的地方,还需要循序渐进的学习下去。 此时可能会问自己,现在做的这些技术的学习对若干年后的自己有什么意义? 这个确实看不了这么远,对于每一个技术人来说,我觉得首先应该做好当下,做一个幽默、温柔、谦逊、潇洒的程序员。

。
。
。
。
下期预告:ceph的部署
















 6166
6166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









