






一、group by
分组原理
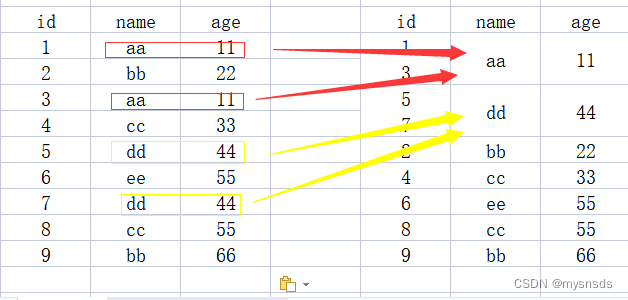
通过单个元素分组(name)
select * from student group by name
左边是实表(student),右边是经group by之后生成的虚拟表
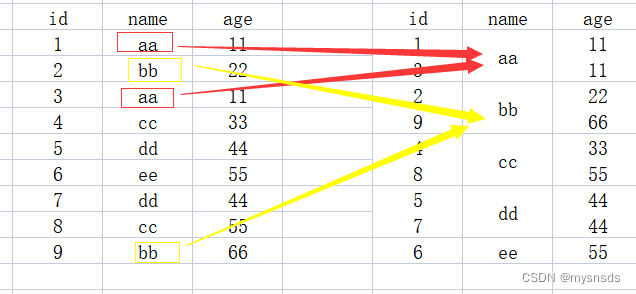
多个元素分组(name,age)
select * from student group by name,age
左边是实表(student),右边是经group by之后生成的虚拟表
(1)如果执行select 的话,那么返回的结果应该是虚拟表,可是id和age中有的单元格里面的内容是多个值的,而关系数据库就是基于关系的,单元格中是不允许有多个值的,所以执行select 语句就报错了。
(2)name列,每个单元格只有一个数据,所以我们select name的话,就没有问题了。为什么name列每个单元格只有一个值呢,因为我们就是用name列来group by的。
(3)那么对于id和age里面的单元格有多个数据的情况怎么办呢?答案就是用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如cout(id)而每个聚合函数的输入就是每一个多数据的单元格。
(4)group by 多个字段该怎么理解呢:如group by name,age,我们可以把name和age 看成一个整体字段,以他们整体
二、distinct
在查询时可以使用distinct过滤重复数据
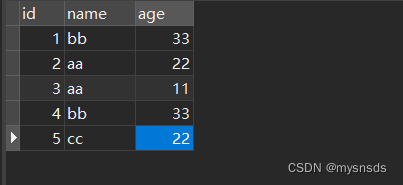
被distinct修饰的字段,一般情况下需要将distinct放在第一位
过滤单个字段
select distinct aaa.name from aaa
过滤多个字段
将两个字段看成一个整体去匹配重复的字段
select distinct aaa.name,aaa.age FROM aaa
distinct和聚合函数使用时,要将distinct放在聚合函数里面,
select count(DISTINCT aaa.age,aaa.name) from aaa
distinct和聚合函数一起使用,则distinct修饰的字段可以不用放在第一位
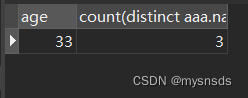
select aaa.age,count(distinct aaa.name) from aaa
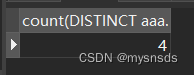
**count()**函数返回字段的数量














 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









