







在实际应用中,对高效、轻量级的超分辨率(SR)提出了很高的要求。然而,大多数专注于减少模型参数和FLOP数量的现有研究可能不一定会导致移动设备上更快的运行速度。在这项工作中,我们提出了一种可重新参数化的构建块,即面向边缘的卷积块(ECB),用于高效的SR设计。在训练阶段,ECB提取多个路径中的特征,包括正常的3×3卷积、通道扩展和压缩卷积,以及来自中间特征的一阶和二阶空间导数。在推理阶段,可以将多个运算合并为一个单独的3×3卷积。ECB可以被视为一种减少替换,以提高正常3×3卷积的性能,而不会在推理阶段引入任何额外的成本。然后,我们提出了一种基于ECB的移动设备高效SR网络,即ECBSR。在五个基准数据集上进行的大量实验证明了ECB和ECBSR的有效性和效率。我们的ECBSR实现了与最先进的轻量级SR型号相当的PSNR/SSIM性能,同时它可以在商品移动设备上实时超分辨率从270p/540p到1080p的图像,例如Snapdragon 865 SOC和Dimensity 1000+SOC。code:GitHub - xindongzhang/ECBSR: Edge-oriented Convolution Block for Real-time Super Resolution on Mobile Devices, ACM Multimedia 2021
我们为SR任务设计了一个更有效的重新参数化块,即面向边缘的卷积块(ECB)。具体来说,我们的ECB由四种精心设计的算子组成:正常的3×3卷积、通道扩展和压缩卷积、从中间特征中提取一阶和二阶空间导数。这种设计可以更有效地提取边缘和纹理信息,这对SR任务很重要。如图6所示,1,我们基于ECB的SR模型(ECBSR)不仅可以实现高SR质量,而且可以保持高推理速度。
我们的贡献可以总结如下:
1)我们首次研究了SR任务的结构可参数化技术,并提出了一种面向边缘的卷积块(ECB)。ECB可以用来提高任何SR模型的SR性能,而不会给推理带来任何额外的负担
2) 在ECB的基础上,我们进一步设计了一个超高效、轻量级的SR模型,即ECBSR,用于移动设备上的实时SISR。大量的实验和比较验证了我们提出的ECB和ECBSR的有效性。ECBSR可以在移动设备上实时将图像从270p/540p提升到1080p,同时保持良好的SR质量
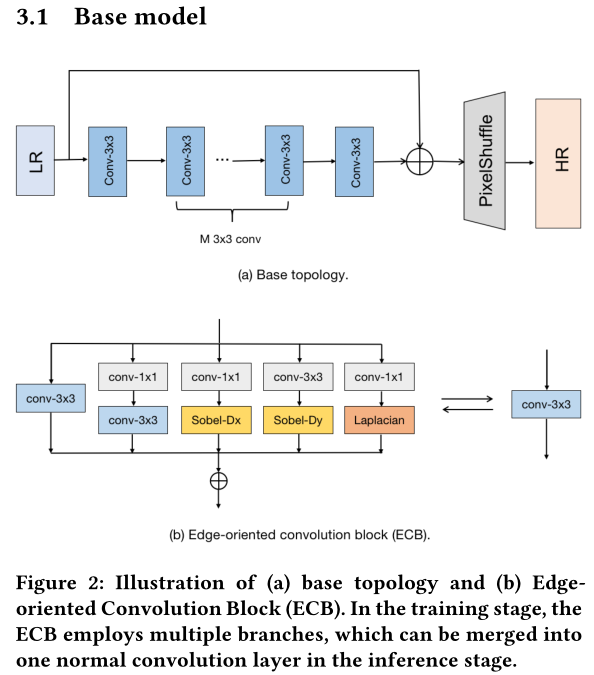
Neat Topology. 尽管复杂的拓扑结构,如多个分支[1,16,17,31]和密集连接[46,49],可以在不引入许多FLOP的情况下丰富特征表示,但这种拓扑结构会导致更高的内存访问成本(MAC)并牺牲并行度,这严重降低了推理速度。由于DDR1的低带宽,移动设备上的情况甚至更糟。例如,使用普通拓扑的FSRCNN[13]比使用复杂拓扑的IMDNRTC[16]具有略高的FLOP,但在SnapDragon 865上运行540p到1080p的升级速度快约两个数量级,如图所示。1。考虑到有限的带宽,我们选择一个几乎平坦的拓扑作为基本模型,并在三通道图像空间(而不是高维特征空间)中只使用一个跳过连接,以保持我们模型的MAC尽可能低。
Basic Operations. 与GPU服务器不同,DSP/GPU/NPU在移动设备上优化的操作目前非常有限,并且因设备而异。不支持的操作必须在CPU上处理,不仅处理速度很低,而且还引入了额外的MAC。因此,我们只采用M个3×3标准卷积,对于移动设备上的大多数DSP/GPU/NPU都得到了很好的支持和高度优化[6,20]。更具体地说,LR图像首先由M个序列3×3卷积C通道。最后的3×3卷积将特征投影到所需的维度,并通过LR输入的快捷方式添加输出特征。PixelShuffle[40]运算符用于生成最终的HR图像。
所提出的基本模型非常适合移动场景,具有较高的效率和灵活性。简洁的拓扑结构和低MAC允许在移动设备上进行超快速推理,基本操作使其易于支持跨设备部署。通过控制M和C, 可以方便地缩放模型的复杂性,以在不同设备上实现性能和运行速度之间的良好权衡。
3.2 Edge-oriented convolution block
尽管普通基础模型是有效的,但与那些复杂的模型相比,其SR性能不太令人满意。因此,我们采用了重新参数化技术来丰富基础模型的表示能力。重新参数化在几个高级视觉任务上取得了有希望的结果[2,9-11,53]。然而,直接应用那些为高级视觉任务设计的可重新参数化块在SR任务中几乎没有得到改善。我们设计了一个更合适的重新参数化块,即面向边缘的卷积块(ECB),它可以更有效地提取SR任务的边缘和纹理信息。如图2(b)所示,ECB由四种精心设计的运算符组成,总结如下。
Component I: a normal 3×3 convolution
我们首先使用普通的3×3卷积来确保基本性能。与之前在高级视觉任务中的重新测量块不同,高级视觉任务在正常之后使用批处理归一化(BN)[19]层,卷积,我们不使用BN层,因为它阻碍了SR性能。正常卷积表示为:
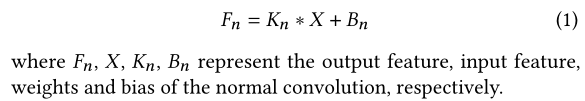
Component II: expanding-and-squeezing convolution
更宽的特征可以显著提高表达能力,并有助于在SR任务[52]上获得更好的性能,因此我们设计了一个扩展和压缩卷积作为第二个组件。

Component III: sequential convolution with scaled Sobel filters
边缘信息已被证明对SR任务非常有帮助[32]。与[32]不同的是,[32]使用Sobel滤波器显式地提取一阶空间导数,并使用额外的网络分支来处理边缘信息,我们将一阶导数的提取隐式地纳入我们的ECB的设计中。由于模型很难自动学习尖锐的边缘滤波器,我们可以选择使用预定义的边缘滤波器并学习每个滤波器的比例因子。

Component IV: sequential convolution with scaled Laplacian filters
除了一阶导数外,我们还使用拉普拉斯滤波器提取二阶空间导数,该滤波器对边缘信息提取的噪声更稳定和鲁棒[42]。类似地,输入特征X先使C ×C × 1 × 1卷积,然后使用提取二阶空间导数,一个拉普拉斯滤波器如下

3.3 Re-parameterization for efficient inference

4 EXPERIMENTS
在本节中,我们首先进行了广泛的实验,以验证我们的ECBSR模型在五个SR基准数据集上的卓越性能及其在两个典型硬件上的高效性。然后,我们进行全面的消融研究,以使我们提出的ECB的设计有效。
4.1 Datasets and implementation details
我们使用800个训练图像在DIV2K数据集[45]上训练我们的模型。DIV2K的验证集以及几个标准基准数据集,包括Set5[4]、Set14[54]、BSD100[34]和Urban100[15],用于性能评估。我们使用PSNR和SSIM[50]作为评估度量,并在将RGB转换为YCbCr格式后在Y通道上计算它们。我们从LR图像中随机裁剪32个大小为64×64的补丁,作为每个训练小批量的输入。执行数据扩充在训练集中,例如90的随机旋转◦, 180◦ 和270◦, 和水平翻转。所有模型都由ADAM[23]优化器使用标准进行训练퐿700个时期的1次损失。学习率设置为常数5×10−4。通过在NVIDIA特斯拉P100 GPU上使用Pytorch[37]工具箱进行模型训练。
4.2 Benchmark results
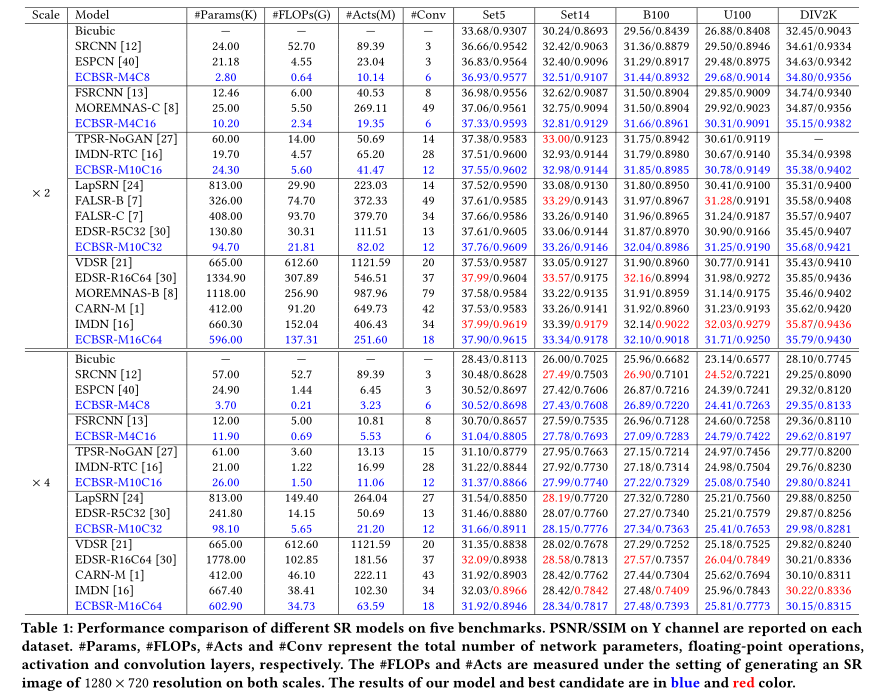
我们将所提出的ECBSR与具有代表性的SR模型进行了比较,包括SRCNN[12]、FSRCNN[13]、ESPCN[40]、VDSR[21]、LapSRN[24]、CARN-M[1]、MoreMNAS-{B,C}[8]、FALSR-{B,C}[7]、TPSR-NoGAN[27]、EDSR[30]和IMDN[16],针对×2和×4的升级任务。由于EDSR和IMDN的默认版本是为GPU服务器设计的,并且具有非常深入或复杂的拓扑结构,我们将EDSR精简为两个轻量级版本,EDSR-R5C32和EDSR-R16C64,并报告IMDN-RTC(IMDN的轻量级版本)进行比较。EDSR-R5C32含有5个残差快每个卷积层具有32个通道。为了与以前的模型进行公平的比较,我们将我们的ECBSR扩展到五个不同的复杂度级别:ECBSR-M4C8、ECBSR-M4C16、ECBSRM10C16、ECBSR-Mo10C32和ECBSR-M16C64。
表中总结了不同SR模型在5个基准数据集上的性能比较。1.除了PSNR/SSIM索引外,我们还列出了参数、FLOP、激活和卷积层的数量,以进行更全面的比较。在×2和×4任务中将图像放大到1280×720分辨率的设置下,计算FLOP的数量和激活。最近的研究表明,激活次数比参数数量和FLOP[38,55]更适合评估模型效率。
从表中可以得出一些有趣的观察结果。1.作为我们模型的最小版本,ECBSR-M4C8在所有五个基准上都以很大的优势优于SRCNN[12]和ESPCN[40],同时使用的参数分别减少了约12×/10×,FLOP减少了92×/9×,激活减少了9×/2×。只需多一点计算和内存,ECBSR-M4C8就可以实现比双三次上采样更好的性能。同样,在大多数情况下,ECBSRM4C16、ECBSR-M10C16和ECBSR-M0C32在性能和模型复杂性方面都比竞争对手表现出明显的优势。值得一提的是,MOREMNASC、FALSR-B和FALSR-C是使用神经结构搜索获得的。我们的ECBSR模型要么与它们相当,要么比它们更好,同时具有更小的模型大小、计算和内存消耗。我们还将我们的ECBSR扩展到M16C64,以便与一些更复杂的SR模型进行比较。使用相似数量的层和少得多的参数、FLOP和激活,ECBSR-M16C64在所有五个数据集上都以很大的优势优于VDSR。我们的ECBSR-M16C64可以获得与EDSR-R16C64、CARN-M和IMDN相当的性能,但它要小得多,重量轻得多。尽管进一步提高ECBSR的块和特征信道的数量可以带来更好的性能,但对于移动设备来说,计算和内存成本将过于沉重,这将在下一节中讨论。
4.3 Hardware running speed
由于模型大小、参数、FLOP和激活不能忠实地反映SR模型的实际运行速度,我们进一步评估了它们在两个移动设备上的实际运行速率。我们选择了两款具有代表性的旗舰移动SoC进行评估,Dimensity 1000+的GPU和SnapDragon 865的DSP。由于SDK在推理速度方面也起着重要作用,我们在相同的设置下使用相同的SDK运行所有模型。我们使用人工智能基准应用程序[18]来执行模型。选择TFLITE GPU和Hexagon NN作为推理机的代表。此外,所有模型都是量化的,并以8位算术执行。表2中报告了在×2和×4任务中将图像放大到1080p分辨率的运行速度。
可以看出,大多数比较的SR模型在两个移动设备上都不是实时的。我们的ECBSR-M4C8和ECBSRM4C16非常高效,在两种设备上都能实现实时速度。在大多数情况下,ECBSR-M10C16和ECBSR-M10C32也可以实现几乎实时的性能,而ECBSR-M16C64对于这两种移动设备来说都太重了。关于所比较的模型,只有ESPCN和FSRCNN能够在某些情况下(×4任务)实现实时性能,因为它们的拓扑结构非常整洁。尽管使用了整洁的拓扑结构,但由于其预上采样策略,SRCNN的速度要慢得多,这大大增加了内存和计算消耗。即使使用轻量级版本,EDSR-R5C32和IMDN-RTC也无法在这两种设备上达到接近实时的速度,因为它们的密集连接和多分支拓扑引入了太多MAC并降低了执行并行性。其他模型也存在同样的问题,速度甚至更慢。
4.4 Qualitative results
在本节中,我们进一步对不同模型的SR质量进行了定性比较。由于我们专注于移动设备上的实时SR,我们只比较可以达到实时或接近实时速度的SR模型,包括双三次上采样、FSRCNN、ESPCN、ECBSR-M4C8、ECBSRM4C16、ECBSRM10C16和ECBSRM10C32。Urban100的两个典型示例图像的×2 SR结果如图所示。3。可以看出,ESPCN、FSRCNN和ECBSR-M4C8的视觉质量仅略好于双三次上采样,并且由于它们的拓扑结构非常浅,所有这些都无法在图像033上恢复足够清晰的边缘。通过改进拓扑的深度和宽度,ECBSR-M4C16、ECBSR-M10C16和ECBSR-M0C32可始终获得更好的视觉质量,边缘更清晰,纹理更清晰。对于img004的结果,ESPCN和FSRCNN在平滑区域引入了稍微不希望的纹理,并在晶格周围引入了波浪形天花板图案。所提出的ECBSR比ESPCN和FSRCNN具有更好的感知结果。ECBSR-M10C32在所有模型中表现最好,并忠实地恢复了晶格的结构和边缘细节
4.5 Ablation studies
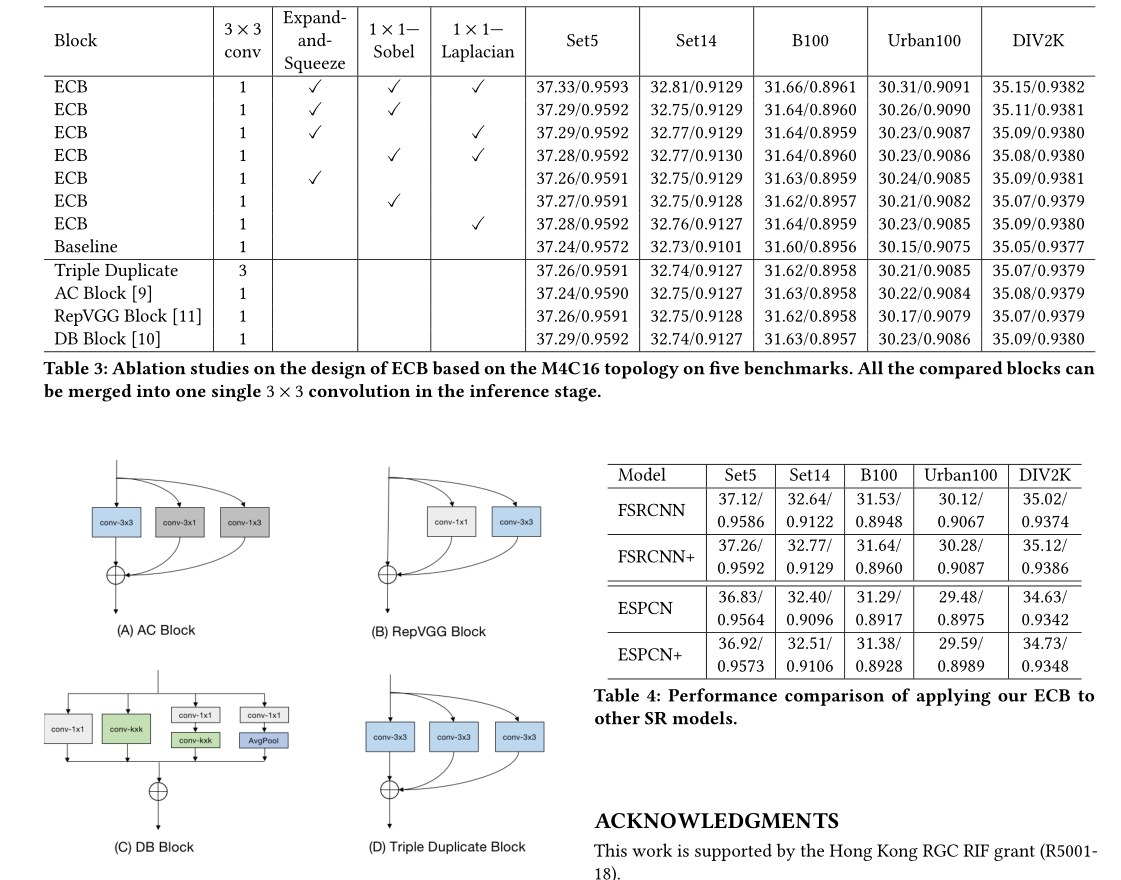
最后,我们对拟议ECB的设计进行了一系列消融研究。具体而言,我们首先消融ECB的一些分支并观察性能的变化,然后将ECB与高级视觉任务中提出的其他一些重新参数化块进行比较,包括AC块[9]、RepVGG块[11]和DB块[10]。三重重复的3×3卷积块也作为基线参考进行比较。考虑到BN会损害SR性能,我们为所有竞争对手BN层。比较的重新参数化块如图所示。表3中报告了五个基准的PSNR/SSIM指数。所有模型都是使用相同的设置从头开始训练的。PSNR/SSIM在×2升级任务上进行评估。
从表3中的结果可以看出,使用这三个组件中的任何一个都可以提高基线模型的性能,而去除ECB中的任何组件都会降低其性能。这意味着ECB中的所有组成部分都有助于SR任务,并且这些组成部分相互补充。对于其他重新参数化块,仅获得三重重复的3×3卷积块、AC块和RepVGG块与基线相比略有改善。DB块实现了稍好的性能,导致PSNR指数的改善小于0.05dB。相比之下,我们的ECB可以在所有数据集上持续提高约0.1dB的PSNR。值得一提的是,所有被比较的块都被合并到一个单独的3×3标准卷积中,并且在推理阶段具有相同的计算和内存成本。ECB的优势验证了我们面向边缘的SR任务设计的有效性。
我们还通过将我们的ECB应用于一些现有的SR拓扑进行了一些实验,以进一步验证ECB的有效性。具体而言,我们用ECB替换了FSRCNN和ESPCN中的3×3正态卷积,并将增强版本分别命名为FSRCNN+和ESPCN+。为了进行公平的比较,我们重新实现了所有模型,并在相同的设置下对它们进行了训练。表中报告了五个数据集上不同模型的PSNR/SSIM比较。4.可以看出,在大多数数据集上,增强模型在PSNR指数上再次获得≥0.1dB的一致性改进。这表明我们的ECB是一个通用的、直接替换的模块,用于提高SR性能,而不引入额外的推理成本
5 CONCLUSION
在本文中,我们提出了一种面向边缘的卷积块(ECB),用于移动设备的高效、轻量级SR设计。在提出的ECB的基础上,我们进一步设计了一个ECBSR模型,旨在平衡硬件效率和PSNR/SSIM指标。在五个基准上进行了广泛的实验,以验证ECBSR相对于最先进的轻量级SR模型的效率和有效性。我们的ECBSR在双挡板移动SoC上实现了实时SR,并保持了高视觉质量。未来,我们将使用网络架构搜索技术来探索更高效、更有效的重新参数化块和网络拓扑。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









