






数据预处理:
import os
os.makedirs(os.path.join('..','data'),exist_ok=True) #自动读取该代码文件的文件位置,并返回上级目录创建data文件
data_file = os.path.join('..','data','house_tiny.csv') #创建CSV文件
with open(data_file, 'w') as f: #打开data_file,并指定以写入模式('w')打开文件。在这个文件对象上可以使用.write()方法来写入数据
f.write('NumRooms,Alley,Price\n') #每一列的名字
f.write('NA,Pave,127500\n') #NA表示未知
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')1. `os.makedirs(os.path.join('..','data'), exist_ok=True)`:
- `os.makedirs()`是一个函数,用来创建文件夹。
- 这个函数中的`'..'`意味着上一级目录,`'data'`是文件夹的名字。
- `exist_ok=True`的意思是如果文件夹已经存在,就不会报错。
2. `data_file = os.path.join('..','data','house_tiny.csv')`:
- `os.path.join()`也是一个函数,用来拼接路径。
- 这个函数中的`'..'`意味着上一级目录,`'data'`是文件夹的名字,`'house_tiny.csv'`是文件的名字。
- 这一行代码的作用是将上一级目录中的`data`文件夹下的`house_tiny.csv`文件的路径赋值给`data_file`这个变量。
从创建的CSV文件中加载原始数据集:
import pandas as pd
data = pd.read_csv(data_file)
print(data)NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
读取csv文件最常用的库是panda库,用该库的read_csv函数读取刚刚写的data_file这个csv文件,并将其赋值给data这个变量。
为了处理缺失数据,典型方法包括:插值和删除,这里我们考虑插值
如果对于删除来说的话就是缺一个数据就把这个样本这一行丢掉,但是会造成数据量的减少,所以不考虑。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.iloc[1:].mean()) #fillna 是 Python 语言中的一个函数,通常用于处理缺失值(NaN)。它可以用于填充缺失值,以使数据集中的数据更加完整和有价值。
print(inputs)
NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
对于填充缺失值,您可以使用fillna()函数来填充inputs中除了第一行以外的缺失值。
- `data.iloc[:,0:2]`是选择了`data`这个数据集的所有行,以及第0列到第1列(不包括第2列)的数据。这表示选择了数据集中的前两列作为输入。
- `data.iloc[:,2]`则选择了`data`这个数据集的所有行,以及第2列的数据。这表示选择了数据集中的第2列作为输出。
`iloc`是Pandas库中的一个方法,用于通过行索引和列索引来选择数据。它是基于整数位置进行索引的。
`iloc`的语法是`data.iloc[行索引, 列索引]`。
- 行索引可以是单个整数、整数列表、整数切片或布尔值列表。例如,`[0]`表示选择第一行,`[1:3]`表示选择第二行到第三行,`[True, False, True]`表示根据布尔条件选择行。
- 列索引可以是单个整数、整数列表、整数切片或布尔值列表。例如,`[0]`表示选择第一列,`[1:3]`表示选择第二列到第三列,`[True, False]`表示根据布尔条件选择列。
通过使用`iloc`方法,可以根据整数位置来对数据集进行切片和选择操作,这对于数据预处理、特征选择等任务非常有用。
inputs = pd.get_dummies(inputs,dummy_na=True,dtype = int)
print(inputs)NumRooms Alley_Pave Alley_nan
0 3.0 1 0
1 2.0 0 1
2 4.0 0 1
3 3.0 0 1
这段代码的作用是对`inputs`进行独热编码,并将结果显示为0和1的形式,并且将数据类型设置为整数(int)。
`pd.get_dummies()`函数用于进行独热编码,将分类变量转换为二进制的特征向量表示。通过设置`dummy_na=True`,函数会为缺失值创建一个额外的列,并将缺失值表示为1,非缺失值表示为0。同时,通过设置`dtype=int`,将结果的数据类型设置为整数。
因此,`print(inputs)`将显示经过独热编码后的数据,其中缺失值表示为1,非缺失值表示为0,并且数据类型为整数。
如果没有dtype = int,那么编译出来的1就显示True,0就显示False。
现在 inputs 和 outputs 中的所有条目都是数值类型,它们可以转换为张量格式。
import torch
x,y = torch.tensor(inputs.values),torch.tensor(outputs.values)
x,y 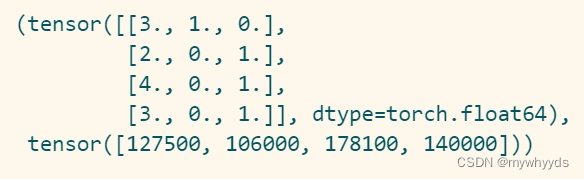















 777
777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









