







 本文指导如何使用TensorFlow构建一个图像分类模型,基于CIFAR10数据集,包括数据加载、预处理、模型构建(如ResNet50)、性能优化及训练过程。
本文指导如何使用TensorFlow构建一个图像分类模型,基于CIFAR10数据集,包括数据加载、预处理、模型构建(如ResNet50)、性能优化及训练过程。

概述
图像分类是深度学习中的基本任务之一。给定一个包含不同类别图像的数据集,我们创建一个深度学习模型和一个管道来对这些图像进行分类。我们可以在任何库中创建模型,但 TensorFlow 对于初学者来说是一个很好的起点,我们将使用这个库来创建一个 TensorFlow 图像分类模型。
我们在建设什么?
本文将通过创建一个神经网络来解决 TensorFlow 图像分类问题,该神经网络可以对 CIFAR10 数据集中的图像进行分类。我们将探讨预处理、增强和性能优化的概念。我们将学习如何加载数据集、构建模型,最后训练使用数据集创建的模型。我们还将学习如何使用经过训练的模型对自定义图像进行预测。
以下部分介绍了这些概念以及如何使用 TensorFlow 实现它们。
先决条件
在进入实际代码之前,我们必须了解一些先决条件术语。它们在这里解释。
-
数据加载器:
数据加载器是一种实用函数,使 TensorFlow 能够优化数据加载性能。Loader 通过预先分配内存、创建批处理容器以及应用许多其他调整来提高性能来实现此目的。 -
数据增强:
数据增强是一种正则化技术,通过在基础图像上应用转换来提高性能。这些转换使模型能够看到更丰富的数据集,而无需额外的数据收集。数据增强对于中小型数据集非常有用。许多增强包括随机翻转、随机颜色抖动、随机调整大小裁剪等等。

-
Lambda 函数:
Lambda 函数是 TensorFlow 中的特殊函数,允许用户在不显式定义函数调用的情况下创建函数。这些函数可用于提高代码的可读性,并避免为一次性使用定义额外的函数。 -
映射函数:
在深度学习中,很多时候我们需要对一批数据应用一个函数。按顺序执行这些任务非常耗时,因此我们使用 map 函数对任何一批数据并行应用函数。
我们将如何构建它?
在本文中,我们将构建一个 TensorFlowimage 分类模型。加载所需的库后,我们首先加载数据。在这里,我们将使用 CIFAR10 数据集。加载数据后,我们将其拆分为训练、测试和验证组件,然后创建相同的批处理。我们还将使用缓存和预取来优化性能。创建所需的数据加载器后,我们可以创建模型。该演示将使用带有 Adam 优化器和稀疏交叉熵损失函数的 ResNet50 模型。加载数据和模型后,我们最终可以在数据上对其进行训练并评估其性能。以下各节详细介绍了所有这些步骤。
最终输出
最终输出是一个 TensorFlow 图像分类模型,该模型可以识别给定图像的类别。我们的模型从 CIFAR10 数据集中学习,并最终准确理解所有十个类。
例如,如果我们将这张 64x64 的图像传递给模型,它应该将其归类为一匹马。

要求
在创建 TensorFlow 图像分类模型之前,必须了解一些概念。
- 了解 TensorFlow 库。
- 了解 Keras 包作为 TensorFlow 包装器,用于简化神经网络构建。
- 熟悉 TensorFlow 数据集,以便快速加载和预处理数据集。
构建分类器
现在,我们可以继续使用导入的库构建 TensorFlow 图像分类管道。以下部分介绍如何加载数据集、对其进行预处理、优化数据集以供使用,以及如何将其传递给模型。我们还探讨了如何使用 TensorFlow 创建模型,以及如何在 CIFAR10 数据集上对其进行训练。最后,我们还将学习如何在测试数据集上评估经过训练的模型。
下载并浏览数据集
在本文中,我们将使用 CIFAR10 数据集。此数据集有 60000 32x32彩色图像分为十类。在创建模型之前,我们必须加载和预处理数据集。图像示例如下所示。

我们将数据集拆分为训练、测试和验证,并使用 as_supervised 选项加载带有标签的数据集。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import tensorflow_datasets as tfds
import os
train_dataset, validation_dataset, test_dataset = tfds.load(
"cifar10",
split=["train[:40%]", "train[40%:50%]", "train[50%:60%]"],
as_supervised=True,
)
使用 Keras 实用程序加载数据
为了验证我们是否正确加载了数据,我们检查了刚刚创建的拆分的大小。如果它们不是零或微小的数字,我们可以知道我们的代码到目前为止已经工作。
print("Number of training samples: %d" % tf.data.experimental.cardinality(train_dataset))
print(
"Number of validation samples: %d" % tf.data.experimental.cardinality(validation_dataset)
)
print("Number of test samples: %d" % tf.data.experimental.cardinality(test_dataset))
配置数据集以提高性能
只需加载数据并将其传递给模型即可开箱即用,但会导致性能急剧下降。我们需要进行一些调整,以确保我们以最佳方式使用我们的资源。
我们首先将图像大小定义为128 x 128x3像素,并使用 lambda 函数将数据集中的所有图像调整为此图像大小。 我们执行的下一个优化是将数据集转换为 64 个样本的批次,并通知 Keras 我们希望缓存数据并预取 10 个样本。
预取数据通过预分配和提取一些额外的样本来减少将数据传递到内存所需的时间,以便下次调用模型。
size = (128, 128)
bs = 64
train_dataset = train_dataset.map(lambda x, y: (tf.image.resize(x, size), y))
validation_dataset = validation_dataset.map(lambda x, y: (tf.image.resize(x, size), y))
test_dataset = test_dataset.map(lambda x, y: (tf.image.resize(x, size), y))
train_dataset = train_dataset.cache().batch(bs).prefetch(buffer_size=10)
validation_dataset = validation_dataset.cache().batch(bs).prefetch(buffer_size=10)
test_dataset = test_dataset.cache().batch(bs).prefetch(buffer_size=10)
创建模型
由于我们希望最大限度地提高性能,我们还使用了两种简单的数据增强技术。第一个沿水平轴随机翻转图像,以确保模型学习一些空间信息。我们使用的第二个增强是随机旋转。我们只想将其应用于某些图像,因此我们使用较低的概率。将其应用于每个图像可能会使模型性能变差。
在本文中,我们使用 TensorFlow 图像分类模型 ResNet50。此模型使用跳过连接的概念来提高性能。我们不会从头开始创建模型,而是使用 Keras 实现。我们必须将我们希望使用预训练模型的权重传递给函数调用。由于我们在这里从头开始训练模型,因此我们将该选项作为 None 传递。如果我们使用迁移学习,我们将使用“imagenet”选项。我们还需要传递图像大小(128 x 128x3)、类的数量 (10),以及我们是否要包含整个模型。最后一个选项仅对迁移学习有帮助。
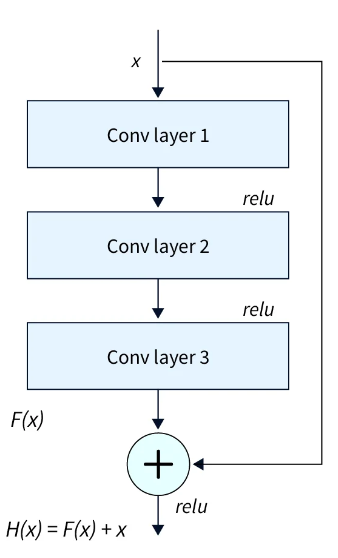
加载模型后,我们创建一个输入,将当前批次传递到增强中,最后,创建一个大小为 10 的全连接 (FC) 层(CIFAR10有 10 个类)。我们将使用这个最终模型来训练我们的数据。
我们将使用汇总函数来检查图层,以验证我们是否正确创建了模型。
aug_transforms = keras.Sequential(
[layers.RandomFlip("horizontal"), layers.RandomRotation(0.1),]
)
model_base = keras.applications.ResNet50(
weights=None,
input_shape=(128, 128, 3),
classes = 10,
include_top=True
)
inputs = keras.Input(shape=(128, 128, 3))
x = aug_transforms(inputs)
x = model_base(x, training=False)
outputs = keras.layers.Dense(10)(x)
final_model = keras.Model(inputs, outputs)
final_model.summary()
训练模型
我们终于可以继续在CIFAR10数据上训练我们的模型了。由于我们已经定义了模型,因此我们必须定义训练它所需的所有参数。
本文将使用带有默认参数的 Adam 优化器。我们在这里使用的指标是分类准确性指标,用于检查分类器在所有类中的表现。我们选择稀疏分类交叉熵函数作为损失函数,因为这是一个多类分类问题。
现在,我们将训练 TensorFlow 图像分类模型 5 个 epoch。我们可以通过增加 epoch 的数量来执行进一步的训练。
final_model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
num_epochs = 5
final_model.fit(train_dataset, epochs=num_epochs, validation_data=validation_dataset)Epoch 1/5
313/313 [==============================] - 110s 304ms/step - loss: 2.3147 - sparse_categorical_accuracy: 0.0984 - val_loss: 2.3061 - val_sparse_categorical_accuracy: 0.1054
Epoch 2/5
313/313 [==============================] - 87s 279ms/step - loss: 2.3034 - sparse_categorical_accuracy: 0.0997 - val_loss: 2.3037 - val_sparse_categorical_accuracy: 0.0968
Epoch 3/5
313/313 [==============================] - 87s 278ms/step - loss: 2.3028 - sparse_categorical_accuracy: 0.1011 - val_loss: 2.3036 - val_sparse_categorical_accuracy: 0.0968
Epoch 4/5
313/313 [==============================] - 87s 279ms/step - loss: 2.3028 - sparse_categorical_accuracy: 0.1006 - val_loss: 2.3036 - val_sparse_categorical_accuracy: 0.0968
Epoch 5/5
313/313 [==============================] - 87s 278ms/step - loss: 2.3028 - sparse_categorical_accuracy: 0.1009 - val_loss: 2.3036 - val_sparse_categorical_accuracy: 0.0968
<keras.callbacks.History at 0x7fcc002f1b20>
评估模型
五个 epoch 非常小,因为我们没有使用迁移学习,而且它只是作为演示完成的。训练模型后,我们可以通过对测试数据集进行预测来执行全面评估。在执行推理时,我们可以增加批量大小,因为我们不是在训练网络。 我们可以使用 Keras 的 evaluate 函数来执行此评估。
results = final_model.evaluate(test_dataset, batch_size=128)
print("test loss, test acc:", results)79/79 [==============================] - 5s 66ms/step - loss: 2.3032 - sparse_categorical_accuracy: 0.1008
test loss, test acc: [2.3031554222106934, 0.10080000013113022]
可以使用以下代码执行单个预测。
from PIL import Image
import numpy as np
from skimage import transform
#cifar10 labels
list_labels = ["airplane","automobile","bird","cat","deer","dog", "frog", "horse", "ship", "truck"]
dict_labels = {i: list_labels[i] for i in range(len(list_labels))}
def load(filename):
np_image = Image.open(filename)
np_image = np.array(np_image).astype('float32')/255
np_image = transform.resize(np_image, (128, 128, 3))
np_image = np.expand_dims(np_image, axis=0)
return np_image
im = Image.open('plane.jpg').resize((128,128));print(dict_labels[int(np.argmax(final_model.predict(image)))]); im

结论
- 本文教我们如何构建 TensorFlow 图像分类模型。
- 本文介绍了如何加载CIFAR10数据集并对其进行预处理以进行训练。
- 它还解释了如何创建一个简单的 ResNet50 模型以及如何在 CIFAR10 数据集上训练它。
- 本文还解释了如何使用经过训练的模型评估模型和执行推理。


















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











