






目录
关于Largest-Triangle-Three-Bucket(LTTB)算法
DynamicX-Largest-Triangle-Three-Bucket(DLTTB)算法
介绍
经过多年的开发,MSChart Extension for WinForms应用程序在显示大数据大小方面的性能问题仍未解决。在应用程序上刷新图表时,我们希望它尽可能快地绘制,以最大程度地减少用户等待时间并最大限度地减少内存消耗。在WinForms中使用Microsoft图表控件(MSChart)时,随着数据大小的增加,绘制图表的内存量和时间会变长。FastLine系列具有更好的性能,但当数据大小增长超过100K数据点时,性能仍然会受到影响。
此外,在屏幕上以有限的像素绘制大数据点会导致所有数据点和线条重叠,从而导致对用户信息的误解。下面的示例显示了具有100K数据点恒定频率的正弦波与具有500个数据点的下采样图表的比较。

具有100k数据点的正弦波

Sinewave下采样至500个数据点
关于Largest-Triangle-Three-Bucket(LTTB)算法
很明显,我们需要某种下采样策略,在屏幕上绘制足够的数据点,以获得更好的速度,同时保留波形的峰值和谷值。请务必记住,下采样数据仅用于数据可视化目的,而不是用于定量分析。
在MSChart扩展中,我们决定实现Sveinn Steinarsson在他的硕士论文中描述的Largest-Triangle-Three-Bucket(LTTB)算法。关于不同程序语言的完整论文和实现可在Sveinn Steinarsson GitHub页面中找到。MSChartExtension中的实现基于Adrian Seeley的C#代码。
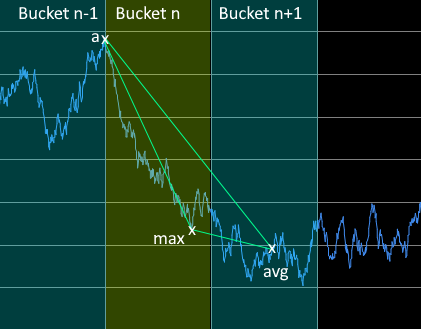
该算法一次处理三个桶,并从左到右从分割的桶开始,选择一个有效面积最大的点来表示下载采样数据中的每个桶。下面的示例显示了具有5000个数据点的随机数据序列,并将相同序列的下载采样为500个数据点。

随机数据5000点

随机数据下采样至500个点
对于所选桶n的每个点,每个点的三角形面积用点a和avg计算,其中点a是前一个桶中的选定点,而点avg是前方下一个桶的临时点。将选择存储桶n中面积最大的数据点。

Largest Triangle Three Bucket计算
该算法的实现方式如下,window[x]是每个桶中的选定点。
我们在代码中进行了进一步的优化,删除了0.5的乘法,因为在使用三角形面积和正方形面积计算之间选择的点没有影响。
double max_area = double.MinValue;
for (int n = bucket_start; n < bucket_end; n++)
{
// Calculate triangle area over three buckets
double area = Math.Abs((a_x - avg_x) *
(array[n].Y - a_y) - (a_x - n) * (avg_y - a_y));
if (area > max_area)
{
max_area = area;
max_area_point = array[n];
next_a = n; // Next a is this b
}
}
// Pick this point from the Bucket
window[w++] = max_area_point;DynamicX-Largest-Triangle-Three-Bucket(DLTTB)算法
如果您关注Sveinn Steinarsson的论文和GitHub页面,您应该知道LTTB有以下限制。
- 不支持数据数组中的间隙(null值)。
- X值必须严格按递增顺序排列。
我们决定更进一步,解决原始LTTB算法中描述的限制。
改进的DyanmicX-Largest-Triangle-Three-Bucket(DLTTB)算法不是按数据索引将数据点划分为存储桶,而是以固定的X间隔将数据点划分和分组到每个存储桶中。每个存储桶中的数据点数可能因数据而异。如果存储桶的边界之间没有一个数据点x值,则存储桶可能没有数据。
while (array[start].X < bucketBoundary) { start++; }
bucketBoundary += bucketSizeX;
end = start;
if (end <= (array.Length - 1)) //Prevent buffer overrun
{
while (array[end].X < bucketBoundary)
{
end++;
if (end == array.Length) break;
}
}不会绘制数据点为零的存储桶,而其他存储桶的下采样数据将基于LTTB算法计算。考虑到某些存储桶可能是空的,DLTTB算法的下采样数据的数据点可能小于定义的显示数据大小。
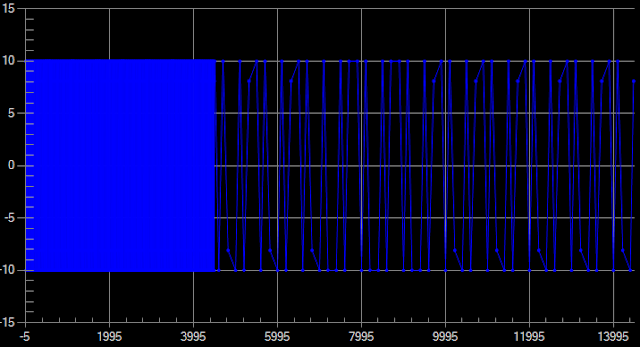
下面的示例显示了5000个正弦波数据点,具有2个不同的间隔,其中前4500个数据的x增加了1,而后500个数据点的x增加了20。查看前4500个数据点中的数据量,这些数据点被绘制为实心块。

具有5000点的原始数据
下图显示了使用LTTB算法将原始数据下采样到800个数据点。最后500个数据点看起来很丑陋,并且丢失了重要细节,因为LTTB不知道数据中不同的X间隔。

使用LTTB对800个点进行下采样
下图显示了使用DLTTB算法将序列下采样到800个数据点,看起来更好。

使用DLTTB对800个点进行下采样
DLTTB和LTTB的性能相同,因为两种算法都使用单通方法,不涉及复杂的乘法计算。
MSChart扩展中的实现
LTTB和DLTTB算法在MSChartExtension的DownSampling类中实现。在true(DLTTB)和false(LTTB)之间设置dynamicX以选择不同的算法。在ChartOption类中引入了一个名为BufferedMode的新选项。
要使用缓冲模式,请先启用BufferedMode并当调用EnableZoomAndPanControls方法时在ChartOption中设置DisplayDataSize,如下所示:
new ChartOption()
{
...
BufferedMode = true,
DisplayDataSize = 800
...
});接下来,使用以下Series类扩展方法将数据点添加到序列中。
series.AddXYBuffered( xvalue, yvalue);使用缓冲模式时,要在图表上显示的最大数据点在DisplayDataSize属性中定义。当用户放大图表时,将重新评估比例视图上的可见数据数量。当可见数据数量超过定义显示数据大小的两倍时,缩减采样算法将生效。否则,将绘制所有可见数据。这样,放大时将向用户提供数据的详细信息。始终绘制序列的第一点和最后一点,以确保PAN函数正常工作。
未来更新
将来的更新和更改将在GitHub——MSChartExtension项目中向公众提供。
https://www.codeproject.com/Articles/5370403/Implementation-Downsampling-Algorithm-in-MSChart-E















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}