








目录
介绍
在本文中,我们将介绍TensorFlow的基础知识,然后转到高级主题。我们的重点是我们可以用TensorFlow做些什么。
背景
我们不会定义Tensorflow究竟是什么,因为已经有很多内容,但我们会努力直接使用它。
让我们开始吧。
我们正在使用Anaconda for Python进行分发,然后使用它安装TensorFlow。我们正在使用GPU版本。
我们激活了anaconda环境。

我们使用英特尔优化的python编写代码。
让我们检查一下如何看到Tensorflow的版本。

要先检查版本,我们导入了tensorflow。
>>> import tensorflow as tf
>>> print(tf.__version__)
1.1.0
//让我们打破单词张量,它意味着n维数组。
我们将在tensorflow中创建最基本的东西,这是恒定的。我们将创建一个名为“ hello Intel” 的变量。
>>> import tensorflow as tf
>>> hello = tf.constant("Hello ")
>>> Intel = tf.constant("Intel ")
>>> type(Intel)
<class>
>>> print(Intel)
Tensor("Const_1:0", shape=(), dtype=string)
>>> with tf.Session() as sess:
... result=sess.run(hello+Intel)
Now we print the result.
>>> print(result)
b'Hello Intel '
>>>
</class>Anaconda提示窗口中的输出如下所示:

现在让我们在TensorFlow中添加两个数字。
我们声明了两个变量:
>>> a =tf.constant(50)
>>> b =tf.constant(70)我们再次检查其中一个变量的类型:
>>> type(a)
<class>
</class>我们看到对象是tensor类型的。要添加两个变量,我们必须创建一个session。
>>> with tf.Session() as sess:
... result = sess.run(a+b)如果我们现在想看到结果:
>>> result
120使用TensorFlow从头开始的神经网络
在下一节中,我们将在TensorFlow中从头开始创建神经网络。
在本节中,我们将创建一个神经网络,对某些2D数据执行简单的线性拟合。
我们将要执行的步骤如下图所示。
我们将要构建的神经网络图的结构如下所示。

首先,我们将导入numpy和tensorflow。
(C:\Program Files\Anaconda3) C:\Users\abhis>activate tensorflow-gpu
(tensorflow-gpu) C:\Users\abhis>python
Python 3.5.2 |Intel Corporation| (default, Feb 5 2017, 02:57:01) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
Intel(R) Distribution for Python is brought to you by Intel Corporation.
Please check out: https://software.intel.com/en-us/python-distribution
>>> import numpy as np
>>> import tensorflow as tf
>>>我们需要为我们的过程设置一些随机种子值。
>>> np.random.seed(101)
>>> tf.set_random_seed(101)现在,我们将添加一些随机数据。使用时rand_a =np.random.uniform(0,100(5,5)),我们添加从0到100的随机数据点,然后将其设置为(5,5)的形状。我们也这样处理b。
>>> rand_a =np.random.uniform(0,100,(5,5))
>>> rand_a
array([[ 51.63986277, 57.06675869, 2.84742265, 17.15216562,
68.52769817],
[ 83.38968626, 30.69662197, 89.36130797, 72.15438618,
18.99389542],
[ 55.42275911, 35.2131954 , 18.18924027, 78.56017619,
96.54832224],
[ 23.23536618, 8.35614337, 60.35484223, 72.89927573,
27.62388285],
[ 68.53063288, 51.78674742, 4.84845374, 13.78692376,
18.69674261]])
>>> rand_b
array([[ 99.43179012],
[ 52.06653967],
[ 57.87895355],
[ 73.48190583],
[ 54.19617722]])现在我们需要为这些统一对象创建占位符。
>>> a = tf.placeholder(tf.float32)
>>> b = tf.placeholder(tf.float32)Tensorflow了解正常的python操作。我们会用它。
>>> add_op = a + b
>>> mul_op = a * b现在我们将创建一些使用图形来提供字典以获得结果的会话。首先,我们声明会话,然后我们想获得add操作的结果。我们需要传入操作和提供字典。对于占位符对象,我们需要提供数据。我们将通过提供字典来做到这一点。首先,我们有钥匙,他们是a和b,然后我们传输数据给它。add_result = sess.run(add_op,feed_dict={a:10,b:20})
>>> with tf.Session() as sess:
... add_result = sess.run(add_op,feed_dict={a:10,b:20})
... print(add_result)由于我们已经创建了随机数,我们将它传递给feed字典。
>>> with tf.Session() as sess:
... add_result = sess.run(add_op,feed_dict={a:rand_a,b:rand_b})现在我们打印的值是add_result:
>>> print(add_result)
[[ 151.07165527 156.49855042 102.27921295 116.58396149 167.95948792]
[ 135.45622253 82.76316071 141.42784119 124.22093201 71.06043243]
[ 113.30171204 93.09214783 76.06819153 136.43911743 154.42727661]
[ 96.7172699 81.83804321 133.83674622 146.38117981 101.10578918]
[ 122.72680664 105.98292542 59.04463196 67.98310089 72.89292145]]我们在这里添加了一个矩阵。
我们也对乘法做同样的事情。
>>> with tf.Session() as sess:
... mul_result = sess.run(mul_op,feed_dict={a:10,b:20})
print(mul_result)
200使用随机值:
>>> with tf.Session() as sess:
... mul_result = sess.run(mul_op,feed_dict={a:rand_a,b:rand_b})
>>> print(mul_result)
[[ 5134.64404297 5674.25 283.12432861 1705.47070312
6813.83154297]
[ 4341.8125 1598.26696777 4652.73388672 3756.8293457 988.9463501 ]
[ 3207.8112793 2038.10290527 1052.77416992 4546.98046875
5588.11572266]
[ 1707.37902832 614.02526855 4434.98876953 5356.77734375
2029.85546875]
[ 3714.09838867 2806.64379883 262.76763916 747.19854736
1013.29199219]]现在让我们创建一个神经网络。
让我们为数据添加一些功能。
>>> n_features =10现在我们只是声明有多少层神经元。在下面的例子中,我们有3。
>>> n_dense_neurons = 3让我们创建一个占位符x,然后我们添加数据类型float。然后我们必须首先找到shape(),我们将其视为None,因为它取决于我们向神经网络提供的数据批量。列将是功能的数量。所以占位符看起来像这样:
>>> x = tf.placeholder(tf.float32,(None,n_features))现在我们将有其他变量。W是权重变量,我们用某种随机性初始化它,然后我们将它的形状设置为具有层中神经元数量的特征数。
>>> W = tf.Variable(tf.random_normal([n_features,n_dense_neurons]))现在我们将宣布偏见。我们声明变量,我们可以将它作为1或0。我们正在使用tensorflow中的函数。我们必须牢记W将乘以x,所以对于矩阵乘法,我们需要保持列的维数和行的维数。
>>> b = tf.Variable(tf.ones([n_dense_neurons])
...
...
...
... )
>>>现在我们需要有一些操作和激活功能。
>>> xW = tf.matmul(x,W)现在输出z:
>>> z = tf.add(xW,b)现在激活功能。
>>> a = tf.sigmoid(z)为了完成图表或流程,我们需要在一个非常简单的会话中运行它。
>>> init = tf.global_variables_initializer()最后,当我们创建一个时session,我们传入一个feed字典。
>>> with tf.Session() as sess:
... sess.run(init)
... layer_out = sess.run(a,feed_dict={x:np.random.random([1,n_features])})
>>> print(layer_out)
[[ 0.19592889 0.84230143 0.36188066]]激活功能
我们现在开始使用激活功能并在TensorFlow中实现。
现在在本节中,我们将实现一个函数并查看我们想要的任何层。
我们通过Anaconda提示进入英特尔优化的python模式。
>>> import TensorFlow as tf现在我们将实现图层(layer)功能。对于我们应该有输入的图层,这是从最后一层处理的信息。使用in_size确定输入的大小,这也描述了最后一层隐藏的神经元数量。使用out_layer显示该层有多少神经元。然后,我们声明激活函数是None,即我们正在使用线性激活函数。我们必须根据输入和输出大小定义权重。我们将使用随机法向生成权重。我们必须传递输入和输出大小。最初,我们使用随机值,因为它可以更好地改善神经网络。我们宣布一维偏见。我们将它初始化为零并将所有变量初始化为0.1。它的维度是1行和out_size没有列。由于我们想要将权重添加到偏差中,所以形状应该是相同的,所以我们使用out_size。对于操作或计算过程,即矩阵乘法。
def add_layer(inputs, in_size, out_size, activation_function=None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
print(outputs)
return outputsTensorboard
我们来谈谈Tensorboard。Tensorboard是一种与Tensorflow一起打包的数据可视化。当我们处理TensorFlow中的网络创建时,由操作和张量组成。当我们将数据馈送到神经网络时,数据以张量的形式流动,执行操作并最终获得输出。
创建Tensorboard是为了了解模型中张量的流动。它有助于调试和优化。
现在我们将研究如何创建图表,然后将其显示在Tensorboard中。
我们将要做的基本操作是:
- 加成
- 乘法
我们现在开始基本的加法操作。在下一节中,我们将讨论如何使用基本的加法运算,然后在Tensorboard中查看它。下图向我们展示了整个流程,然后我们将详细讨论它。

首先,我们需要导入Tensorflow。
导入张量流为tf。
在那之后,我们必须声明placeholder变量。
X = tf.placeholder(tf.float32, name="X")
Y = tf.placeholder(tf.float32, name="Y")接下来,我们需要声明我们需要执行哪些操作。
addition = tf.add(X, Y, name="addition")在下一步中,我们必须声明session作为我们想要执行操作,因此我们需要在一个session内部执行操作。我们将不得不使用init初始化变量。然后我们必须在init内部运行sess。
sess = tf.Session()
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)当我们使用feed字典运行会话时,我们初始化变量的值:
result = sess.run(addition, feed_dict ={X: [5,2,1], Y: [10,6,1]})最后,使用Summary writer,我们得到图的调试日志。
if int((tf.__version__).split('.')[1]) < 12 and
int((tf.__version__).split('.')[0]) < 1: # tensorflow version < 0.12
writer = tf.train.SummaryWriter('logs/nono', sess.graph)
else: # tensorflow version >= 0.12
writer = tf.summary.FileWriter("logs/nono", sess.graph)python中的整个代码库在单向流中看起来像这样。
import tensorflow as tf
X = tf.placeholder(tf.float32, name="X")
Y = tf.placeholder(tf.float32, name="Y")
addition = tf.add(X, Y, name="addition")
sess = tf.Session()
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
if int((tf.__version__).split('.')[1]) < 12 and
int((tf.__version__).split('.')[0]) < 1: # tensorflow version < 0.12
writer = tf.train.SummaryWriter('logs/nono', sess.graph)
else: # tensorflow version >= 0.12
writer = tf.summary.FileWriter("logs/nono", sess.graph)现在让我们想象一下。我们将进行Anaconda提示。激活环境并转到文件夹以运行python文件。

现在我们需要运行python文件。
运行以下命令后:
(tensorflow-gpu) C:\Users\abhis\Desktop>python abb2.py获得以下输出:
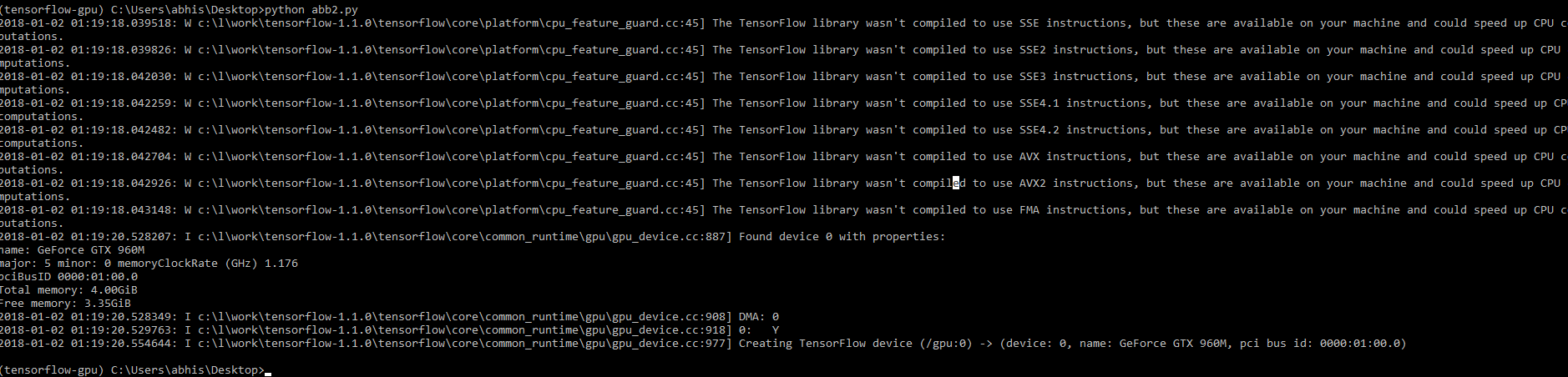
现在打开Tensorboard:
(tensorflow-gpu) C:\Users\abhis\Desktop>tensorboard --logdir=logs/nono
(tensorflow-gpu) C:\Users\abhis\Desktop>tensorboard --logdir=logs/nono
WARNING:tensorflow:Found more than one graph event per run,
or there was a metagraph containing a graph_def, as well as one or more graph events.
Overwriting the graph with the newest event.在http://0.0.0.0:6006中开始TensorBoard b'47'
(按CTRL + C退出)
现在让我们打开Tensorboard访问的浏览器。
需要打开以下链接。
该图如下所示:

对于乘法,也遵循相同的过程,并在下面共享代码库:
import tensorflow as tf
X = tf.placeholder(tf.float32, name="X")
Y = tf.placeholder(tf.float32, name="Y")
multiplication = tf.multiply(X, Y, name="multiplication")
sess = tf.Session()
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
result = sess.run(multiplication, feed_dict ={X: [5,2,1], Y: [10,6,1]})
if int((tf.__version__).split('.')[1]) < 12 and
int((tf.__version__).split('.')[0]) < 1: # tensorflow version < 0.12
writer = tf.train.SummaryWriter('logs/no1', sess.graph)
else: # tensorflow version >= 0.12
writer = tf.summary.FileWriter("logs/no1", sess.graph)我们运行python文件并使用Tensorboard运行它...图形如下所示:

让我们使用更复杂的教程来了解Tensorboard可视化如何为它工作。我们将使用如上所示的激活函数定义。
现在我们将声明placeholder:
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')我们将添加一个隐藏层,其中包含激活功能relu。
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)我们将添加输出层:
prediction = add_layer(l1, 10, 1, activation_function=None)接下来我们将计算错误:
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))接下来,我们需要训练网络。我们将使用梯度下降优化器:
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)TensorFlow图中的范围。当我们处理由图维护的层次结构类型时,可能会有很多复杂情况。为了使它更有序,我们使用“范围”。如果要单独可视化和调试,范围可帮助我们轻松区分特定节点或任何功能的工作。要声明范围,将应用以下过程。
with tf.name_scope(‘<name>’):
</name><name>应该用您提供的范围名称替换。应用范围后的整个代码如下所示:
from __future__ import print_function
import tensorflow as tf
def add_layer(inputs, in_size, out_size, activation_function=None):
# add one more layer and return the output of this layer
with tf.name_scope('layer'):
with tf.name_scope('weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W')
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
return outputs
# define placeholder for inputs to network
with tf.name_scope('inputs'):
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
# add hidden layer
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# add output layer
prediction = add_layer(l1, 10, 1, activation_function=None)
# the error between prediction and real data
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
sess = tf.Session()
# tf.train.SummaryWriter soon be deprecated, use following
if int((tf.__version__).split('.')[1]) < 12 and
int((tf.__version__).split('.')[0]) < 1: # tensorflow version < 0.12
writer = tf.train.SummaryWriter('logs/eg', sess.graph)
else: # tensorflow version >= 0.12
writer = tf.summary.FileWriter("logs/eg", sess.graph)
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)现在让我们运行python文件,然后启动Tensorboard。
(tensorflow-gpu) C:\Users\abhis\Desktop>python ab5.py要运行Tensorboard:
(tensorflow-gpu) C:\Users\abhis\Desktop>tensorboard --logdir=logs/eg主要在运行Tensorboard后,图形如下所示。请关注声明的范围。

让我们先扩展一层,因为里面定义了很多范围。

红色刻度线是“ layer”范围内的范围。
现在让我们扩大weights范围。
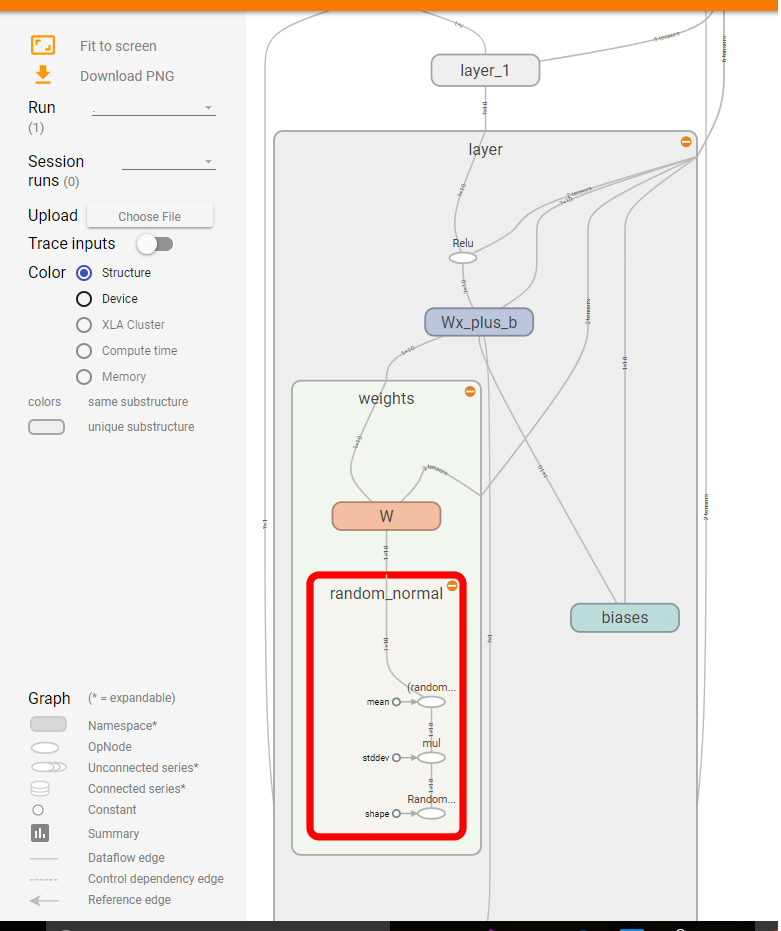
现在关注偏见范围。

现在我们将重点关注wx_plus_b 范围:

我们从关注范围看到,在标记它们之后,很容易看到图形的显著可视化,并且当它变得复杂时它极大地帮助了我们。
使用Tensorboard嵌入可视化
当我们应该在机器学习和深度学习问题中应用算法时,如果我们能够正确地可视化算法的工作和流程,它总是能帮助我们的。
嵌入可视化本质上是Tensorboard中神经网络的一个重要特征。
当我们想要分享关于图像的大量信息时,我们将不得不收集有关它的信息。这样,如果我们分析图像,我们收集信息并将其投影到高维向量中。
事实上,这些映射称为投影。Tensorboard中有两种类型的投影,如下图所示:

- PCA(主成分分析)
- PCA通常用于找出数据的最佳或前10个主要组成部分
- t-SNE(T分布式随机邻域嵌入)
应用的过程尝试维护数据集的本地结构,但会扭曲全局结构。
首先,我们必须从以下链接获取可以从Kaggle网站下载的数据集(如果您没有Kaggle帐户,则无法下载,请创建它)。
该网站托管的文件如下图所示:
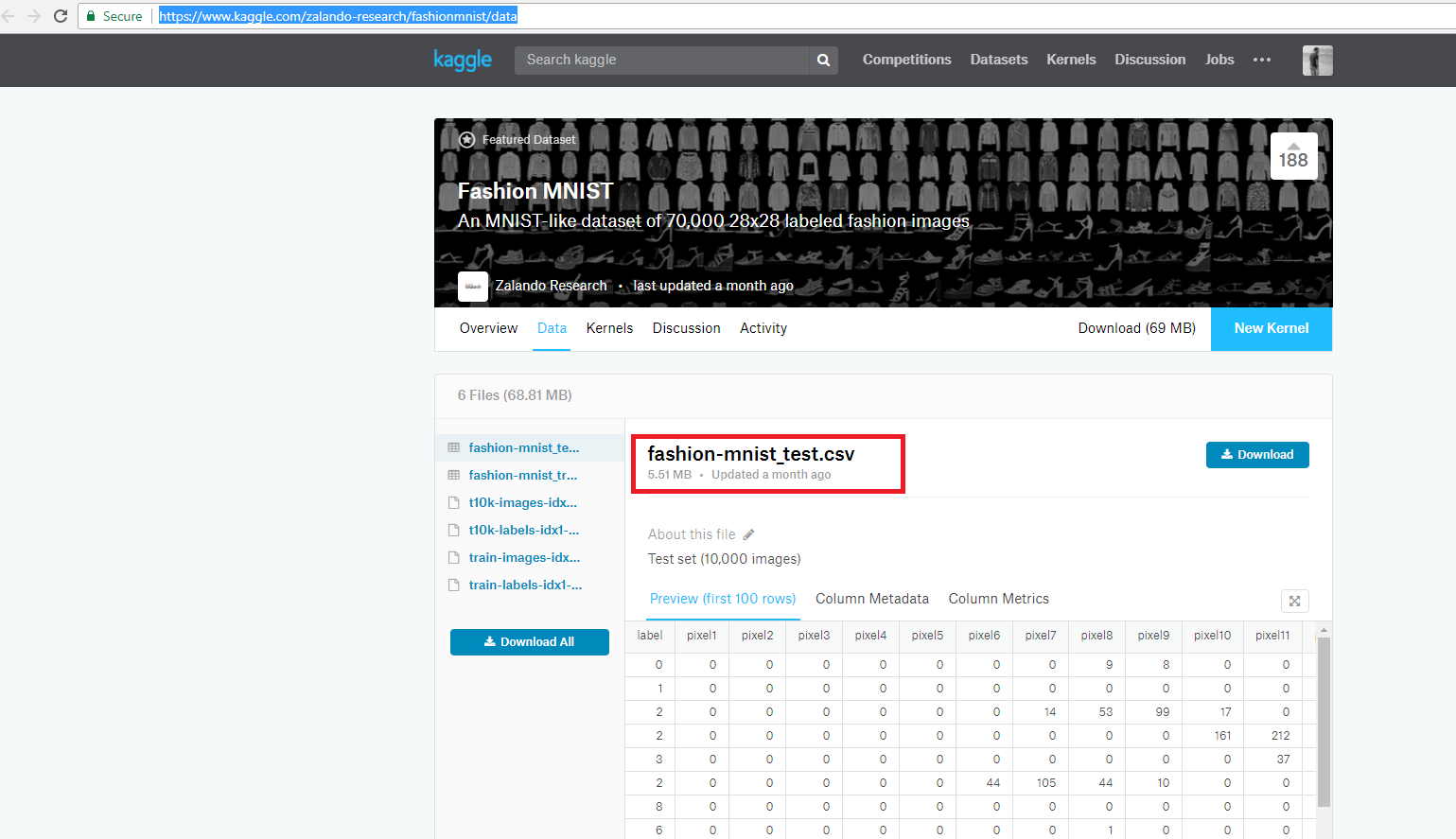
我们下载文件并将其保存在文件夹中。我们将它保存在桌面上。我们必须记住位置,因为我们必须提供python文件的完整本地链接。
首先,我们将导入您要分析的网络的重要依赖项。在我们的例子中,我们错过了我们不得不从anaconda云下载它的pandas。
要为pandas安装Anaconda软件包,必须在Anaconda提示符中输入以下命令。
conda install -c anaconda pandas然后,我们根据需要导入依赖项。
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
from tensorflow.examples.tutorials.mnist import input_data下一步是读取我们保存在数据文件夹中的fashion数据集文件。
test_data = np.array(pd.read_csv(r'data\fashion-mnist_test.csv'), dtype='float32')我们已经进行了嵌入计数是1600,您可以更改并检查。
embed_count = 1600正如我们现在导入的数据,我们必须把它分配到x与y,如下图所示:
x_test = test_data[:embed_count, 1:] / 255
y_test = test_data[:embed_count, 0]现在我们需要给出保存日志的目录:
logdir = r'C:\Users\abhis\Desktop\logs\eg4'下一步是设置Tensorboard所需的摘要编写器并创建嵌入传感器,如下所示:
summary_writer = tf.summary.FileWriter(logdir)
embedding_var = tf.Variable(x_test, name='fmnist_embedding')
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
embedding.tensor_name = embedding_var.name
embedding.metadata_path = os.path.join(logdir, 'metadata.tsv')
embedding.sprite.image_path = os.path.join(logdir, 'sprite.png')
embedding.sprite.single_image_dim.extend([28, 28])
projector.visualize_embeddings(summary_writer, config)接下来,我们将运行session以获取可视化所需的检查点。
with tf.Session() as sesh:
sesh.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.save(sesh, os.path.join(logdir, 'model.ckpt'))我们将创建sprite和元数据文件以及fashion数据集的标签。
rows = 28
cols = 28
label = ['t_shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle_boot']
sprite_dim = int(np.sqrt(x_test.shape[0]))
sprite_image = np.ones((cols * sprite_dim, rows * sprite_dim))
index = 0
labels = []
for i in range(sprite_dim):
for j in range(sprite_dim):
labels.append(label[int(y_test[index])])
sprite_image[
i * cols: (i + 1) * cols,
j * rows: (j + 1) * rows
] = x_test[index].reshape(28, 28) * -1 + 1
index += 1
with open(embedding.metadata_path, 'w') as meta:
meta.write('Index\tLabel\n')
for index, label in enumerate(labels):
meta.write('{}\t{}\n'.format(index, label))
plt.imsave(embedding.sprite.image_path, sprite_image, cmap='gray')
plt.imshow(sprite_image, cmap='gray')现在让我们运行python文件。
(C:\Users\abhis\Anaconda3) C:\Users\abhis>activate tensorflow-gpu
(tensorflow-gpu) C:\Users\abhis>cd desktop
(tensorflow-gpu) C:\Users\abhis\Desktop>python abhi7.py接下来,我们需要使用日志文件的完整路径启动Tensorboard。
(tensorflow-gpu) C:\Users\abhis\Desktop>tensorboard --logdir=logs/eg4
Starting TensorBoard b'47' at http://0.0.0.0:6006
(Press CTRL+C to quit)我们打开Tensorboard的本地链接。现在,我们需要前往embeddings选项卡。它将如下所示:
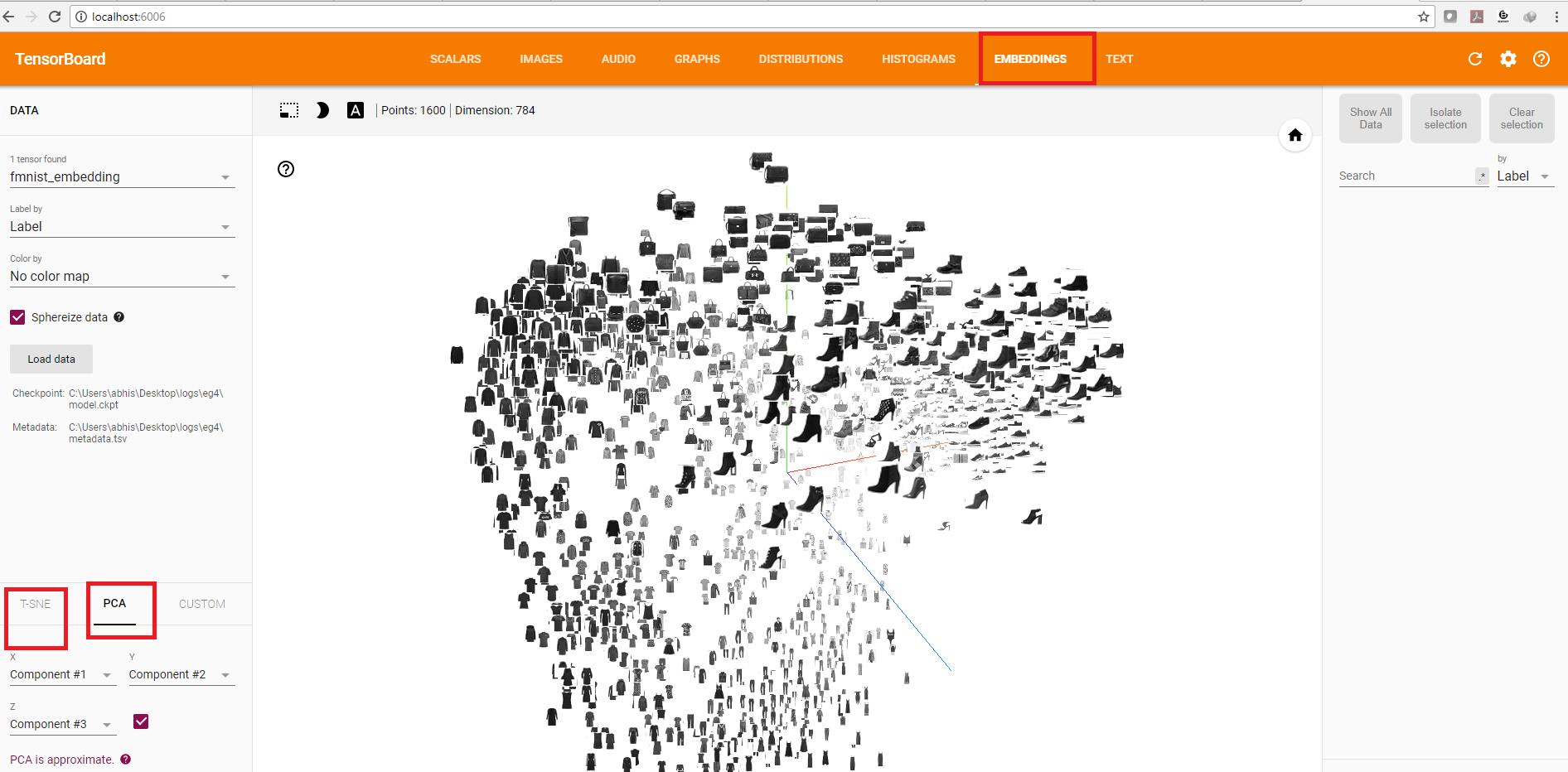
我们目前正在使用PCA方法进行可视化,我们也可以转向t-SNE。
如果我们想要在彩色索引文件中看到对象,则需要应用以下方法。

现在看起来像这样:
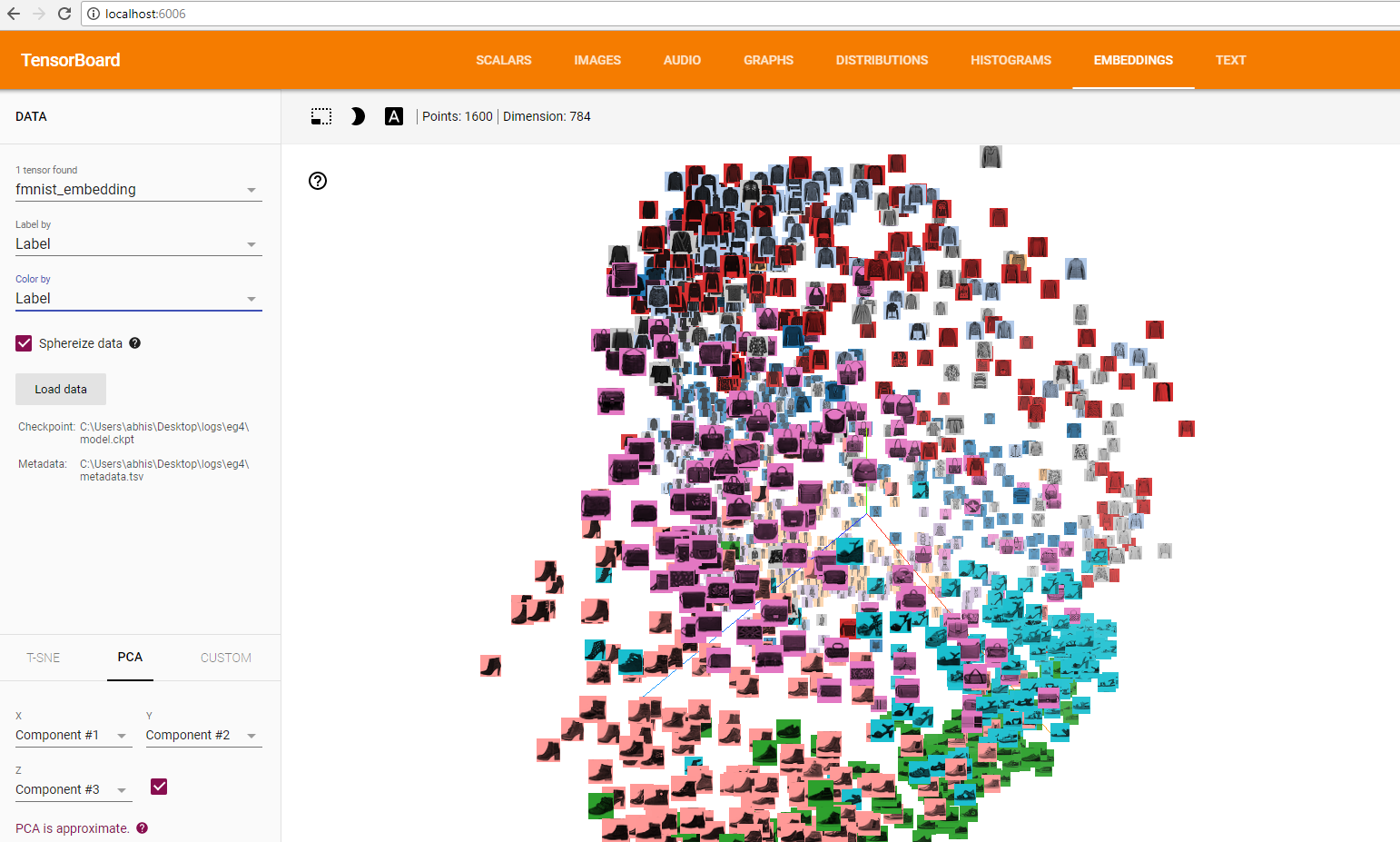
当我们将其转移到t-SNE时,方法会发生变化。

结论
在本文中,我们介绍了一些使用英特尔优化python的tensorflow基础知识以及它的一些重要功能。完成后,我想你可以跟随并实践上面讨论的所有事情。
原文地址:https://www.codeproject.com/Articles/1272499/Discovering-Tensorflow

















 3789
3789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









