







文章目录
1.什么是索引?
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。通俗的理解,他就是书的目录,通过这个目录可以快速的找到内容(通过索引可以快速的找到数据),对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
本文所讲的索引/事务都是基于MySQL5.5之后的默认的数据库引擎InnoDB。
MySQL的数据库引擎:
MySQL5.5之后的默认的数据库引擎InnoDB、之前的默认引擎MyISAM。
区别:
稳定性:InnoDB引擎支持事务(保证数据稳定),稳定性比MyISAM好,MyISAM不支持事务。
性能:MyISAM性能比较高,而InnoDB性能不如MyISAM
使用以下命令查询当前数据库引擎:
show variables like 'default_storage_engine';
2.为什么要使用索引?
存储数据模块:
1.磁盘:容量大、价格低廉、操作速度慢、可以持久化[重启之后数据还是存在的]
2.内存:容量小、价格比较贵、操作速度快、不可以被持久化
3.CPU缓存(L1/L2/L3):容量小、操作速度极快、不可以被持久化
索引就是为了避免顺序查询,提供查询速度的。
查询数据存储的目录:
show variables like '%dir%';
一句话概括:索引可以提高查询效率,所以每个表中都会有索引。
a)使用索引可以避免顺序查询,可以直接将查询的访问定位出来,这样的话查询效率大大提升。
b)使用索引可以将数据库中的关键信息存储到内存中,而内存的操作速度远比磁盘块。
c)
索引的作用
数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
索引所起的作用类似书籍目录,可用于快速定位、检索数据。
索引对于提高数据库的性能有很大的帮助。
索引VS书的目录
从宏观角度来看,索引就是书的目录
从微观来说,索引并不等于书的目录。因为一本书的目录只有一个,而一张表可以有多个索引,而每个索引都相当于一个索引(目录)。在数据库中一张表可以有多个索引,一张表可以有多个“书籍目录”。
索引有缺点和使用场景
优点:
提高数据库查询效率
缺点:
1.索引增加了维护成本,因为索引使用的是B+树,在数据添加和删除数据时需要整理树结构,这样的话就带来了新的开销。
2.使用索引会增加存储成本(磁盘空间成本的提升、内存空间成本的提升)
3.如果索引过多就会对MySQL的优化器造成一定的负担
创建索引要考虑的因素:
1。数据量是否足够大,查询速度是否比较慢
2.创建索引的列是否经常使用查询条件
不适合创建索引的场景:
1.都比较低频,而添加和删除比较高频的业务表,不适合使用索引,比如日志表(一年半载查询不了一次,但是添加非常高频,而每次添加都需要重新整理索引)
2.MySQL服务器本身安装的电脑磁盘或内存空间不足的情况下,就不要创建
注意事项
1.如果对已经存在的很多数据的表新增索引的时候,不要再生产环境上运行(找一个没有用户使用的时间段进行索引创建,因为索引创建会锁表,其他的业务场景就只能排队等待了)。
索引使用
A.索引分类:
按照是非为主键:
1.主键索引(聚簇索引/聚集索引):一种特殊的唯一索引,不允许有空值,一般是在建表的时候同时创建主键索引
2.非主键索引(非聚簇索引/非聚集索引/二级索引)
特征:
普通索引
唯一索引(创建索引的这个字段,能保证唯一性)
联合索引(由一个表中多个字段组成的索引)
B.索引的创建
主键索引、唯一索引它是在创建表的时候,如果设置了主键约束或者是唯一约束的时候就会自动创建见主键索引和唯一索引。
如果一个表在创建的时候设置了primary key(设置了主键约束),那么此列会自动添加一个主键索引。
如果在创建一张表的时候设置unique(唯一约束),那么此列会自动创建一个唯一索引。
PS:如果创建外键约束那么也会产生索引。
C.手动创建普通索引:
索引命名规则:idx_字段名
cerete index 索引名 on 表名(字段名[,字段名2]);

查看:

D.手动创建唯一索引
语法:
cerete unique index 索引名 on 表名(字段名[,字段名2]);
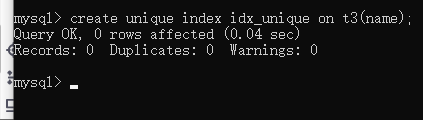
查看:

E.创建主键索引:
语法:
alter table 表名 add primary key (列名);
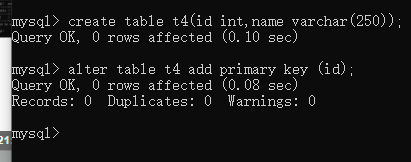
查看:

F.索引VS约束
1.创建索引的时候会自动创建约束,并且在创建约束的时候也会自动创建索引。
2.索引和约束是不同的业务定义,约束是用来规范数据的正确性的,而索引是用来提升数据库的程序性能的。
G.删除索引
语法:
drop index 索引名 on 表名;
每个索引名在一张表中都是随机的,不能重复
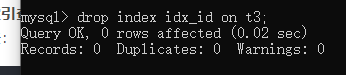
查看:

注意事项:
1.在创建索引的时候会创建对应的约束,而删除索引的时候也会删除对应的约束
2.唯一索引创建时要确保原先的数据要符合唯一约束,才能成功的创建唯一约束,否则会创建失败。
H.索引查看:
语法:
show index from 表名;
I.索引实现原理
索引的实现经历了3个阶段:
1.二叉树
缺陷:层级比较高,查询和维护不方便
2.B-树
缺陷:将所有的数据都存储在叶子节点和非叶子节点,当数据量特别大时,刚把索引加载起来就需要很长很长的时间
3.B+树
优化:1.非叶子节点不再存储表数据:
2.叶子节点存储的并不是数据本身,而是数据的地址
J.必问的面试问题:聚簇索引和非聚簇索引(二级索引)/聚集索引和非聚集索引的区别:
聚簇索引是只要查询到相应的id就能得到id对应的这一行的数据。
**二级索引:**非叶子节点存储的是二级索引的值,叶子节点存储的时主键ID
聚簇索引对比的是主键,如果逐渐能够对应上,那么就能直接查询到主键对应的行数据。
但是二级索引的叶子节点存储的是主键,因此当二级索引能够匹配上之后,只能拿到主键的信息,
然后根据主键的信息,去聚簇索引里去找到叶子节点所对应的行数据,这样才能完成二级索引的数据查询。
我们把二级索引进行查询数据的这个过程叫做回表查询。---->二级索引—>ID—>又去查询聚簇索引,找到相应的数
答:执行效率:聚簇索引的查询效率更快,而二级索引需要进行“回表查询”,因此它的效率更低。
数量:聚簇索引一个表只有一个,而非聚簇索引可以有多个
聚簇索引生成规则
1.正常情况下,所有的表中都会有一个主键索引。大部分的时候聚簇索引就是主键,默认的情况下就是主键索引。
2.没有主键索引的情况下,InnoDB会使用一个唯一且非空的索引作为聚簇索引。
3.如果没有主键索引且没有(唯一且非空的索引),InnoDB会自动生成一个隐蔽的聚簇索引。
K.索引失效的场景
索引校验
判断MySQL是否生效:
explain 关键字:
explain select * from 表名 where 条件;

创建一个数据库:
-- 创建表
drop table if exists student_index;
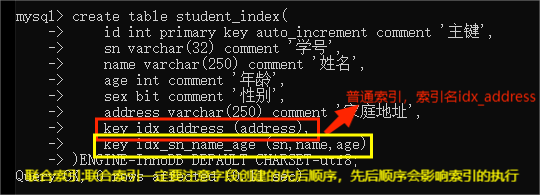
create table student_index(
id int primary key auto_increment comment '主键',
sn varchar(32) comment '学号',
name varchar(250) comment '姓名',
age int comment '年龄',
sex bit comment '性别',
address varchar(250) comment '家庭地址',
key idx_address (address),
key idx_sn_name_age (sn,name,age)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 添加测试数据
insert into student_index(id,sn,name,age,sex,address)
values(1,'cn001','张三',18,1,'高老庄'),
(2,'cn002','李四',20,0,'花果山'),
(3,'cn003','王五',50,1,'水帘洞');
建表的时候创建索引:
索引失效场景1:联合索引不满足最左匹配原则(前缀匹配)
最左匹配原则指的是,以最左边的为起点字段查询可以使用联合索引,否则将不能使用联合索引。
联合索引的顺序:sn+name+age
sn为最左边的字段。
设A(sn) B(name) C(age)
1.联合查询顺序:A+B+C—>满足最左匹配原则,可以使用联合索引

2.A+B—>满足最左匹配原则,可以使用联合索引
 3.A+C–>满足最左匹配原则,可以使用联合索引
3.A+C–>满足最左匹配原则,可以使用联合索引

4.A–>满足最左匹配原则,可以使用联合索引

5.B+C–>不满足最左匹配原则,不可以使用联合索引

6.B–>不满足最左匹配原则,不可以使用联合索引
7.C–>不满足最左匹配原则,不可以使用联合索引
满足最左匹配原则:
1.A+B+C
2.A+B
3.A+C
4.A
5.B+A
6.C+A
7.A+C+B
不满足最左匹配原则:
1.B+C
2.B
3.C
4.C+B
索引失效场景2:使用错误的模糊查询
like模糊查询的常用方式:
1.前面确定 字段名 like’张%’
2.后面确定 字段名 like’%张’
3.中间确定 字段名 like’%张%’
只有1触发索引

如果为2,3(不能触发索引):


索引失效场景3:索引查询的列使用了运算操作(+/-/*//)

索引失效场景4:查询的列使用了函数

索引失效场景5:查询的列使用了隐式的类型转换

索引失效场景6:使用if not null

L.联合索引有什么问题
联合索引想要触发索引一定要遵循最左匹配原则
M.索引的实现原理
详情见I.索引实现原理















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









