







分治:
分解成子问题,分别解决子问题,合并子问题的解。
且子问题是相互独立的。可以用递归或非递归实现。
- 减治(子问题个数为一) :n地阶乘
- 分支(子问题个数大于一):Fibonacci数列地求解
关键:
1.找到递归式。F(n)= do(F(n-1));
2.找到递归边界:if(n==1) return 1.
全排列,n皇后
贪心
关键:似乎可行的策略。
简单贪心:(获得最大收益,肯定从单价最高的先卖。)
区间贪心:先选择左端点大的,左端点一样大选择右端点小的。
求最优解: 动态规划、贪心算法。
看每次的选择:
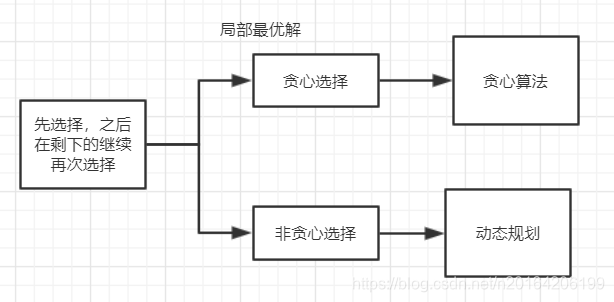
整体最优解可以拆成局部最优解(贪心)。
单源最短路径(Dijkstra、Floyd)、最小生成树(Prim、Kruskal)、哈夫曼编码(哈夫曼树,找两个最小的结点变成新结点)
背包问题:拆成每次最优解解决:动态规划
如果考虑特例,举出反例:用贪心算法得出的解不是最优解那就用动态规划。
二分
基于有序序列的查找算法
1.严格递增序列
int BinarySearch(int a[], int low, int high, int x)
{
int mid;
while (low <= high)//要有等于号,可能恰好就在中间,不等于的话就搜不到了。
{
mid = (low + high) / 2;
if (**x == a[mid]**) return mid;
if (x < a[mid]) {
high = mid - 1;
}else {
low = mid + 1;
}
}
return -1;
}
x == a[mid]: 条件是等于x的元素位置
2.非严格递增
返回第一个大于等于x的位置(可能有重复x) || 返回第一个大于x的位置
int BinarySoloSearch(int a[], int low, int high, int x)
{
//返回第一个大于等于x的地方(可能有重复x)
//寻找第一个满足某条件的元素位置
//因为mid 就是我要寻找的位置
int mid;
while (low < high) { //退出条件 low == high 唯一位置
mid = (low + high) / 2;
if ( **a[mid] >=x** ) { //寻找第一个>=x 的数 :现在中间的数比x要大
high = mid; // 我要去左区间找
}
else {
low = mid + 1;
}
}
return low;
}
a[mid] >=x的不同:满足某一条件的元素位置:往哪个区间找。
3.二分法拓展:精度问题
#include<iostream>
#include<cmath>
using namespace std;
const double esp = 1e-5; //(10^5)
double eal() {
double left = 1, right = 2, mid;
while (right - left > esp) {//退出条件:精度小于10^-5
mid = (left + right) / 2;
if (pow(mid, 2) > 2) {//平方比二大 比 判断 该数比根号2大精确
right = mid;
}
else {
left = mid;
}
}
return mid;
}
int main()
{
cout << eal();
}
1.41421
可以转换为求方程的解
木棒切割: 有两端,切割的长度越长,木棒椴数越少。
木棒切割
切割成K段:求长度相等的木棒 : 最长能有多长
int cut(int a[], int size, int length)
{
int sum = 0;
for (int i = 0; i <size; i++)
{
sum += a[i] / length;
}
return sum;
}
int main()
{
int sticks[100],n,K;
cin >> n>>K;
for (int i = 0; i < n; i++)
{
cin >> sticks[i];
}
sort(sticks, sticks + n);
int k,low = 0, high = sticks[n-1],mid;
// 最大取最大的那根木棒
while (low <= high) { // 当low>high的时候跳出
mid = (high+low)/2;
k = cut(sticks, n,mid);
if (k < K && cut(sticks, n, mid - 1) == K) break;//找到第一个切出来的数目比需要切出来的数目小的(找长度最大的)跳出
if (k < K && cut(sticks, n, mid - 1) != K) high = mid;
else low=mid+1;
}
if (low > high)cout << mid;
else cout << mid-1; //长度变小一点就满足”最长“
}
c++中使用scanf
添加
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
memset: 对数组中每一个元素赋相同的值(0/-1)
int a[5] = { 2,3,5,4,6 };
memset(a, -1, sizeof(a));
指针
指针是个unsigned类型的整数
指针变量 数据类型* p 用于存放指针(即地址),而&为取地址符。所以都是 int* p = &a
int* p = &a;
等价
int* p;
p=&a;
数组与指针
数组名称也作为数组的首地址使用。a==&a[0],a+i==&a[i]
结构体初始化
typedef struct Stu{
int x;
int y;
int sum;
Stu() {}
Stu(int _x, int _y, int _sum):x(_x), y(_y), sum(_sum) {}
}Stu;
浮点数比较(精确)
const double eps = 1e-8;
const double Pi = acos(-1.0);
#define Equ(a,b) ((fabs((a)-(b)))<(eps))
#define More(a,b) ((a)-(b)<(eps))
#define Less(a,b) ((a)-(b)<(-eps))
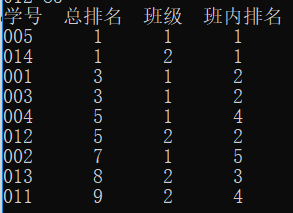
学生名次排序
相同的成绩同一名次,但是排序不叠加。
分批排序:一批中有K个人。总人数为 t。
sort(先排好序)
stu[t - K].local_rank = 1;
for (int j = t-K+1; j < t; j++)
{
if (stu[j].score == stu[j - 1].score) stu[j].local_rank = stu[j - 1].local_rank;
else {//从第二名来
stu[j].local_rank = j-(t - K) + 1;
}
}
排总名次
sort(先排好序)
stu[0].rank = 1;
for (int i = 1; i < t; i++)
{
if(stu[i].score==stu[i-1].score)stu[i].rank = stu[i-1].rank;
else {
stu[i].rank = i + 1;
}
}
哈希散列
将元素通过一个函数转换为整数,并且该整数可以尽量唯一地代表这个元素。
H(key)=key%mod
处理冲突地办法初试已经学过。
字符串hash:用ASCII码解决,将字符串转换为整数。
#include<iostream>
using namespace std;
// 最大整数:26*26*26-1 只看前三个字母
int hashTable[26 * 26 * 26 + 10] = { 0 };
int hashFunc(char S[], int len) {
int id = 0;
for (int i = 0; i < len; i++)
{
id = id * 26 + (S[i] - 'A');
}
return id;
}
int main()
{
int n, m;
cin >> n >> m;
//可以存100个存在查询地字符串
char S[100][5],temp[5];
for (int i = 0; i < n; i++)//n个字符串
{
cin >> S[i];
int id = hashFunc(S[i], 3);
hashTable[id]++;
}
for (int i = 0; i < m; i++)//m个查询字符串
{
cin >> temp;
int id = hashFunc(temp, 3);
cout << hashTable[id];
//输出有多少个temp
}
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









