






MySQL数据库索引是数据库管理系统中用于加速检索操作的一种数据结构。在MySQL中,索引可以帮助数据库更快地找到数据,类似于书的目录可以帮助你更快找到你想要阅读的页面。以下是MySQL中几种常见的索引类型及其特点:
什么是索引:
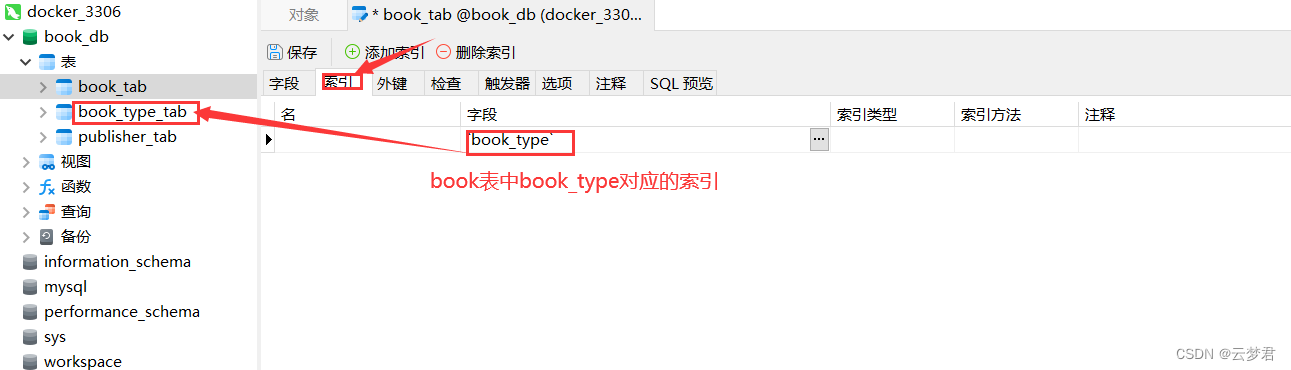
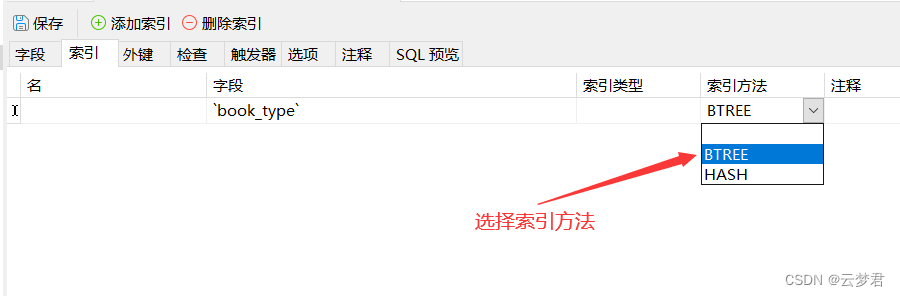
3. FULLTEXT索引
总结:
全文索引(FULLTEXT)是为了更快地进行文本搜索而设计的特殊类型索引。它们只在CHAR、VARCHAR或TEXT列上可用。全文索引适用于包含大量文本的列,并且可以在其中搜索词语。
FULLTEXT索引是MySQL数据库中用于全文搜索的一种特殊类型的索引。这种索引适用于包含大量文本的列,如文章、评论或描述性字段。FULLTEXT索引提供了一种在这些文本数据中快速搜索关键词的方式。以下是FULLTEXT索引的一些详细介绍:
支持的存储引擎
- 在MySQL中,FULLTEXT索引最初只支持MyISAM存储引擎。从MySQL 5.6版本开始,InnoDB存储引擎也开始支持FULLTEXT索引。
创建FULLTEXT索引
-
FULLTEXT索引可以在创建表时或之后通过
ALTER TABLE或CREATE INDEX语句创建。 -
创建FULLTEXT索引的基本语法如下:
CREATE TABLE example ( id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY, content TEXT, FULLTEXT (content) );或者对已存在的表添加索引:
ALTER TABLE example ADD FULLTEXT (content);
使用FULLTEXT索引
-
FULLTEXT索引通常与
MATCH() ... AGAINST()语句一起使用来进行全文搜索。 -
基本的使用语法是:
SELECT * FROM table WHERE MATCH(column) AGAINST('keyword'); -
MATCH()函数中列出了要搜索的列,AGAINST函数中指定了搜索的关键词。
特点
- 全文搜索:与传统的基于字符匹配的搜索不同,FULLTEXT索引允许进行全文搜索,这意味着它可以搜索词汇而非整个字符串的匹配。
- 自然语言搜索和布尔搜索:FULLTEXT索引支持自然语言搜索和布尔搜索。自然语言搜索是基于自然语言处理的,更符合一般查询习惯;布尔搜索则允许使用布尔逻辑(如AND、OR、NOT)来精细控制搜索。
- 分词处理:在创建FULLTEXT索引时,MySQL会对文本内容进行分词处理,以建立索引。这个过程依赖于MySQL的分词器。
性能考虑
- 对于大型文本数据集,FULLTEXT索引可以显著提高搜索效率。
- 然而,FULLTEXT索引会占用额外的磁盘空间,并可能增加数据插入时的开销。
注意事项
- FULLTEXT索引不适用于较小或非文本的数据字段。
- 搜索结果的相关性评分可以通过
MATCH() ... AGAINST()语句中的返回值获得,以帮助确定匹配项的相关程度。 - FULLTEXT索引对于非英语文本的支持可能有限,这取决于MySQL的版本和配置。
通过使用FULLTEXT索引,可以有效地对大型文本字段进行高效、灵活的搜索,这对于构建文本密集型应用程序如内容管理系统或博客非常有用。
4. R-Tree索引
总结:
R-Tree索引是一种专门为地理空间数据设计的索引,它适用于空间类型的列(例如,几何数据类型)。R-Tree索引可以有效地查询空间数据查询,例如找出哪些对象位于给定的区域内。
R-Tree索引是一种平衡树结构,它主要用于空间数据索引,也就是索引多维数据。这种索引结构可以非常高效地查询和管理地理空间信息。R-Tree索引的典型应用场景包括地图服务、地理信息系统(GIS)、空间数据库和一些多维数据集的快速访问。
R-Tree索引的特点:
-
多维性:R-Tree索引适用于多维空间数据的索引,可以处理如二维或三维空间对象的位置和形状。
-
层次性:R-Tree是一棵树形结构,有多个层级。每个节点代表着被包围在一个由所有子节点定义的最小边界矩形(Minimum Bounding Rectangle, MBR)内的空间区域。
-
高效的范围查询:由于R-Tree索引使用MBR来定义空间对象,所以它非常适合于执行范围查询,例如查询所有在某个矩形区域内的地理位置。
-
动态:R-Tree索引可以在不断地插入和删除数据项的情况下,动态地调整自己以保持平衡状态。
-
局部性:R-Tree索引利用了空间局部性原理,相近的对象通常被组织到树的同一部分中,这样可以减少磁盘I/O操作。
R-Tree索引的结构:
R-Tree索引的基本单元是节点,节点分为两种类型:
- 叶子节点:存储指向实际空间数据对象的指针及其MBR。
- 非叶子节点:存储指向其子节点的指针以及覆盖其所有子节点的MBR。
一个节点可以包含多个条目,每个条目要么是一个指向数据的指针(在叶子节点中),要么是一个指向另一个节点的指针(在非叶子节点中)。所有叶子节点都在同一层级,也就是说,从根节点到任何叶子节点的路径长度都是相同的(这是R-Tree作为平衡树的特质之一)。
R-Tree索引的操作:
-
插入:当插入一个新的空间对象时,会为其选择一个最小的MBR来包围它,然后将其插入到对应的叶子节点中。如果插入导致节点溢出,就需要分裂节点,并可能递归地向上分裂。
-
删除:从R-Tree中删除对象时,会找到包含该对象的叶子节点,并从中移除。如果这导致节点下溢,可能需要进行节点的合并和调整。
-
搜索:搜索操作包括点查询和范围查询。算法从根节点开始,递归地遍历所有可能包含查询区间的节点,直到找到所有符合条件的叶子节点。
MySQL中的R-Tree索引:
在MySQL数据库中,R-Tree索引主要与地理空间数据类型一起使用,例如GEOMETRY、POINT、LINESTRING和POLYGON等。这些数据类型通常存储在SPATIAL索引中,而MySQL中的SPATIAL索引就是基于R-Tree的实现。
MySQL的MyISAM存储引擎支持SPATIAL索引。从MySQL 5.7开始,InnoDB存储引擎也开始支持SPATIAL索引。使用时,可以在创建表时对地理空间数据列创建SPATIAL索引,如下所示:
CREATE TABLE geom_table (
id INT AUTO_INCREMENT PRIMARY KEY,
geom GEOMETRY NOT NULL,
SPATIAL INDEX(geom)
) ENGINE=MyISAM;在执行空间数据相关的查询时,如ST_Contains或ST_Within等,SPATIAL索引可以大幅提高查询效率。
需要注意的是,R-Tree索引的效率受到数据分布的影响。如果数据过于密集或有大量重叠,索引的效率可能会降低。
5. 聚簇索引
总结:
在某些存储引擎中,如InnoDB,聚簇索引指的是表存储数据的物理顺序和索引的顺序是相同的,并且表中的每一行数据都会在聚簇索引中表示。在InnoDB中,主键自然成为聚簇索引,如果没有定义主键,则MySQL会选择一个唯一非空列作为聚簇索引。如果这样的列也不存在,MySQL会生成一个隐藏的行ID作为聚簇索引。
在MySQL数据库中,聚簇索引(Clustered Index)是一种特殊类型的索引,它直接决定了表中数据的物理存储顺序。聚簇索引并不是单独存储的结构,而是数据表的行记录在磁盘上的存放形式,因此一个表只能有一个聚簇索引。如果一个表定义了PRIMARY KEY,则该主键自动成为聚簇索引。如果没有定义PRIMARY KEY,MySQL会选择第一个唯一索引(UNIQUE INDEX)作为聚簇索引。如果表没有任何主键或唯一索引,则MySQL会自动生成一个隐藏的ROWID作为聚簇索引。
聚簇索引的特点
-
有序存储:聚簇索引的键值的逻辑顺序和物理顺序是一致的,也就是说,使用聚簇索引键值检索数据时,可以快速定位到数据的物理位置。
-
数据存放:在聚簇索引中,表中的行记录和索引是存放在一起的,即索引结构的叶子节点就包含了对应的表行数据。
-
一个表只有一个:由于聚簇索引决定了数据的物理存储顺序,因此一个表只能拥有一个聚簇索引。
-
主键查询效率高:由于主键通常作为聚簇索引,通过主键查询数据非常快。
-
范围查询的效率:对于范围查询,聚簇索引也非常有效,因为相关数据在磁盘上是相邻存储的。
聚簇索引的优点
-
数据访问速度快:由于数据行和索引是一起存储的,所以聚簇索引可以快速直接地访问数据。
-
空间效率:不需要额外的指针来定位数据行,因为索引结构的叶子节点中已经包含了完整的数据行。
-
范围查询优势:进行范围查询时,由于数据行在物理上是连续的,所以IO操作更加高效。
聚簇索引的缺点
-
插入速度:如果插入数据的顺序和聚簇索引的顺序不一致,可能会导致页面分裂,增加磁盘I/O,降低插入性能。
-
更新开销:如果聚簇索引的键值被更新,可能导致数据行需要在物理存储上移动,这会产生较大的开销。
-
二级索引(非聚簇索引)的大小和性能:在InnoDB中,二级索引会保存聚簇索引的键值作为指针。如果聚簇索引的键很大,二级索引也会相应变大,占用更多空间,并且可能影响查询性能。
聚簇索引与非聚簇索引的比较
非聚簇索引(Secondary Index或Non-clustered Index)在MySQL的InnoDB存储引擎中是另一种索引类型,它的索引结构和数据行是分开存储的。非聚簇索引的叶子节点包含了对应聚簇索引键的值,而不是数据行本身。这意味着在通过非聚簇索引查询数据时,通常需要两次查找:一次在非聚簇索引上找到聚簇索引的键,然后再在聚簇索引上定位到实际的数据行。
总的来说,聚簇索引是MySQL中数据存储和检索的一个重要概念,其设计优势在于提高了数据检索的效率,但也带来了一些插入和更新操作的性能上的考虑。在设计数据库表和选择索引策略时,了解聚簇索引的机制对于优化性能是非常重要的。
索引的使用原则与考虑因素:
- 高选择性:索引应该具有高选择性,即索引列的每个值都应该是唯一的或几乎唯一的。
- 索引列的操作:应该对那些经常出现在查询条件(WHERE)、排序条件(ORDER BY)及分组条件(GROUP BY)中的列创建索引。
- 索引维护:索引虽然能够提高查询性能,但同时也会降低插入、删除和更新表中数据的速度,因为在进行这些操作时,索引也需要被更新。
- 索引覆盖:如果一个索引包含了查询中需要的全部数据,则称为“覆盖索引”,这样的查询可以直接通过索引来获取数据,不需要访问表中的行,查询性能非常好。
索引的限制:
- 不是所有的操作都能使用索引,例如,如果列使用了NOT NULL、OR,对列进行函数操作等情况可能无法使用索引。
- 使用LIKE '%value%'这样的前缀通配符搜索时,B-Tree索引无法被使用,因为它无法利用索引中的顺序。
创建索引时应该仔细考虑以上因素,因为不合理的索引会降低数据库性能。

















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









