







 本文深入解析了集群技术的定义、分类及其核心特性,包括可扩展性、高可用性、负载均衡和服务节点错误恢复机制。详细介绍了HA、LB和HPC集群的区别与应用场景,以及集群中的关键概念如浮动IP、失效域和仲裁机制。
本文深入解析了集群技术的定义、分类及其核心特性,包括可扩展性、高可用性、负载均衡和服务节点错误恢复机制。详细介绍了HA、LB和HPC集群的区别与应用场景,以及集群中的关键概念如浮动IP、失效域和仲裁机制。
集群的定义:
1、 集群是一组协同工作的服务实体
2、 集群实体的可扩展性
3、 集群实体的高可用性
4、 集群实体地址
5、 客户请求的负载均衡
6、 服务节点的错误恢复
集群是一组协同工作的服务实体,用以提供比单一服务实体更具扩展性和可用性的服务
平台。
从客户端看来,一个集群就是一个完整不可细分的实体,但事实上一个集群实体是由完成不同任务的服务节点个体所组成的。
集群实体的可扩展性是指,在集群运行的中新的服务节点可以动态的加入集群实体从而提升集群实体的综合性能。
集群实体的高可用性是指,集群实体通过其内部的服务节点的冗余使客户端免予OUT OF SERVICE 错误。简单的说,在集群中同一服务可以由多个服务节点提供,当部分服务节点失效后,其它服务节点可以接管服务。
集群实体地址是指客户端访问集群实体获取服务资源的唯一入口地址。
负载均衡是指集群中的分发设备(服务)将用户的请求任务比较均衡(不是平均)分布到集群实体中的服务节点计算、存储和网络资源中。一般我们将提供负载均衡分发的设备叫做负载均衡器。负载均衡器一般具备如下三个功能:
1、 维护集群地址
2、 负责管理各个服务节点的加入和退出
3、 集群地址向内部服务节点地址的转换
错误恢复是指集群中某个或某些服务节点(设备)不能正常工作(或提供服务),其它类似服务节点(设备)可以资源透明和持续的完成原有任务。具备错误恢复能力是集群实体
高可用性的必要条件。
负责均衡和错误恢复都需要集群实体中各个服务节点中有执行同一任务的资源存在,而且对于同一任务的各个资源来说,执行任务所需的信息视图必须一致。
集群的分类:
1、 HA (High Availability)
2、 LB (Load Balancing)
3、 HPC (High performance Computing)
DC (Distributed Computing)
PC (Parallel Computing)
高性能计算集群(High Performance Compute clustering )(如 Beowulf)使用多个机器来为需要大量计算能力的任务提供更强大的计算能力。RHEL 没有内嵌这类集群的解决方案。
高可用性集群( High-availability clustering )使用多个机器来为某个服务或某组服务提供额外的可靠性。
负载均衡集群( Load-balance clustering )使用特殊的路由技术来给一组服务器分配任务。
HA 集 群 的概念
1、 通过特殊软件把独立的系统(node)连接起来,组成一个能够提供故障切换
(Faileover)功能的集群
2、 Ha集群可以保证在多种故障中,关键服务的可用性、可靠性及数据完整性
3、 Ha集群主要用于文件服务,WEB 服务,数据库服务等关键应用中
分类:
- 主从方式(非对称)
从服务器不对外提供服务,监控主服务器,如果主服务器出现故障,不能对外提供服务,那么从服务器会使用故障迁移,将资源从主服务器拿过来,由“自己”对外提供服务。
从服务器使用心跳检测链路监控主服务器。
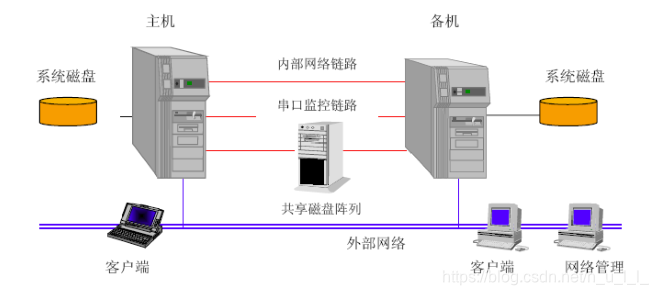
- 对称方式(互备互援)
2个节点都对外提供服务,互相监视。
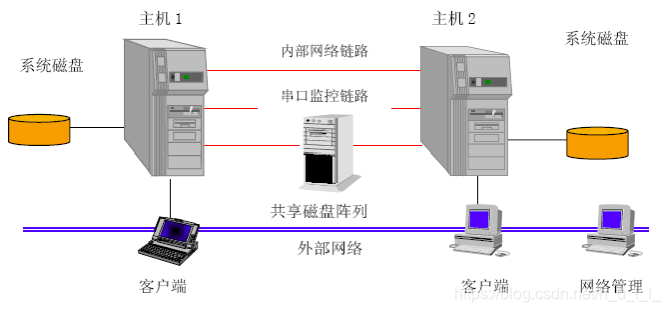
- 多机方式(多机互备)
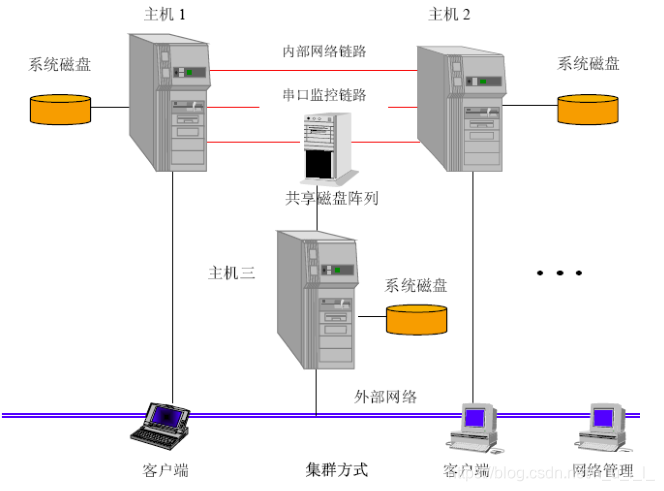
3个节点都对外提供服务,互相监视。
可用性通常指系统的 uptime ,在 7x24 的工作环境中, 99% 的可用性指在一年中可以有 87 小时 36 分钟的 DOWN 机时间,通常在关键服务中这种一天多的故障时间是无法接受的,所以提出了前面提到的错误恢复概念,以满足 99.999% 的可用性需求。
概念:
服务:是HA 集群中提供的特定资源,其中括客户端访问的IP地址(Float IP),共享的存储设备等。集群系统会对服务进行监控,一旦发现错误,服务会迁移至其它服务器继续运行。
浮动IP:成员服务器或节点 : 也叫做节点(Node),是HA 集群中实际运行服务务提供特定资源的服务器。
失效域:是HA集群中提供特定资源的成员服务器(Member Server)的集合,当失效域(Failover Domain)中某些特定资源的成员服务器(Member Server)出现故障时,可以将服务(service)转移至失效域(Failover Domain)其它成员服务器(Member Server)上。一个失效域(Failover Domain)通常会包括至少两台成员服务器(Member Server)。
心跳:是 HA 集群监视服务器状态的方法,一般情况下心跳是通过网络数据包来判断服务器是否正常运行。
共享存储:为保证HA 集群中服务进行切换时,服务所需的数据资源能够保持一致,HA集群会采用共享存储(Share Storage)的方式来储存服务所需的数据,共享存储可以是磁盘柜FC or SCSI SAN)或特定网络服务(iSCSI or NFS NAS)。
单一故障点:是HA集群中最被关注的问题之
一,HA 集群可以包含双控制器的 RAID 阵列、多个网络频道、以及冗余的不间断电源(UPS)系统来确保不会出现导致程序停运或数据丢失的单一失效情况。另外你还可以设置低费用的 HA 集群来提供比“无单一失效点”集群稍低的可用性。
仲裁:是HA 集群中为了保证能够判断服务器及其运行的服务(Service)是否正常,采用了在共享磁盘中保存成员服务器(Member Server)信息的方法,如果 HA集群的其它成员访问到的仲裁信息表明某些成员服务器(Member Server)或其运行的服务状态不正常则会将该成员服务器(Member Server)从 HA集群中暂时删除并将其运行的服务(Service)切换至失效域(Failover Domain)中其它成员服务器(Member Server)上运行。
失效迁移:是当 HA 集群中硬件或成员服务器(Member Server)上的软件失效时,HA 集群采取恰当的保持服务(Service)的保持可用性且数据保持完整性的过程。
监视器:用于确定成员服务器(Member Server)或其上运行服务(Service)的某种硬件或软件。监视器(Watchdog)通过定时向该硬件或软件发送信息来确定成员服务器(Member Server)状态,如果信息出错误或未接收到信息,则监视器(Watchdog)会完成响应的预定操作(例如重启服务或服务器)。
脑裂(裂脑)
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果——或者共享资源被瓜分、2边“服务”都起不来了;或者2边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)。
产生脑裂的原因:
【1】心跳线故障
【2】网卡或驱动故障
【3】心跳连接的设备故障
【4】ip地址冲突,基本不会发生
【5】防火墙拦截了心跳数据包的传输
连接心跳的方式:
【1】串口线直连,有距离限制
【2】网线直连
直连的方式只适用于双节点
【3】使用交换机,通过网线连接
使用最多
要保证链路的纯净!!!
解决脑裂:
【1】心跳线冗余
【2】做好监控
一旦出现故障切换,报警要触发动作。
【3】仲裁
让节点完成ping 网关或存储 的动作,
能完成,证明节点是好的
不能完成,节点故障,自动放弃争抢
3、 多机
3个节点都对外提供服务,互相监视。
HA集群的存活条件是节点的票数要过半数!!!
默认一个节点的票数是1票。
在双节点模式的集群,这个功能需要关掉。
三节点节点,在down掉2个节点的时候,集群就宣布死亡。
为了保证在这种情况下,集群还是存活的,仲裁磁盘带有票数。
仲裁磁盘有2票就可以了。
LB 集 群 的概念
1、 在 LB服务器上使用专门的路由算法,将数据包分散到多个真实服务器中进行处理,从而达到网络服务均衡负载的作用
2、 Lb 服务器可以充分利用现有资源,提高高负载服务的性能,降低高负载服务的成本
3、 Lb 集群主要用于公共 WEB服务、FTP服务、数据库服务等高负载服务中

















 4321
4321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









