







💫《博主介绍》:✨又是一天没白过,我是奈斯,DBA一名✨
💫《擅长领域》:✌️擅长Oracle、MySQL、SQLserver、阿里云AnalyticDB for MySQL(分布式数据仓库)、Linux,也在扩展大数据方向的知识面✌️
💖💖💖大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注💖💖💖

最近在深入学习MySQL的行格式和页的原理,太偏原理性的东西整理起来真的是脑子疼,反而写博客会觉得更轻松,那么今天继续给大家介绍Oracle的逻辑迁移工具expdp/impdp。在上篇文章中介绍了exp/imp逻辑迁移工具,其实这两个工具实现的功能都是一样的,但是在10g后更多去用expdp/impdp数据泵,那么话不多说开始今天的内容。
expdp/impdp可以以 并行导出 数据,提高导出效率,并支持对导出的数据进行 压缩 ,节省存储空间。可以通过参数设置选择性地导出指定的数据库对象、指定的数据范围,或者只导出数据库结构而不包括数据。
关于逻辑迁移工具全部的篇幅介绍,四篇的内容分别如下:
- 第一篇:一文搞清exp/imp逻辑迁移工具的用法和定时全备实例
- 第二篇:一文搞清expdp/impdp逻辑迁移工具的用法和定时全备实例(当前篇)
- 第三篇:expdp/impdp轻松完成某个生产用户从GBK到UTF8编码的迁移
- 第四篇:expdp/impdp高效完成全部生产用户的全库迁移
目录
2)集群(rac)环境的实例完全导出(参数cluster=no。不仅仅在完全导出时加上该参数,对于在rac环境下的用户、表等的导出都要加上。并且impdp导入也需要设置cluster=no)
案例2:导出时限制导出文件大小(os文件大小有限制或者导出量太大)
方式一:使用sys用户,在linux /unix上需要设置"/ as sysdba"为 \"/ as sysdba\"转译符号
方式三:通过在INCLUDE=TABLE参数中加SQL语句,实现SQL语句在expdp层面将返回查询到的多个表进行导出
案例5:导出生产用户某些表的前10行(query=" 'where rownum<10' ")
案例6:ESTIMATE_ONLY参数可估计导出作业占用的空间量(实际上并不执行导出,只测算导出的文件有多大)
2)集群(rac)环境的实例完全导入(参数cluster=no。不仅仅在完全导入时加上该参数,对于在rac环境下的用户、表等的导入都要加上)
(2)impdp时数据泵的后台进程(可以确定导入的行数,确定进度)
expdp/impdp相比于exp/imp的优势:
1、并行处理:
expdp/impdp支持并行处理,可以通过多个进程同时导入导出数据,提高数据传输效率和速度,特别适合处理大型数据库的导入导出任务。
2、增量导入:
使用expdp/impdp可以实现增量数据导入,可以选择性地只导入部分数据,而不是整个数据集。
3、更灵活的对象级别操作:expdp/impdp支持对不同级别的数据库对象进行导入导出,例如可以只导出表结构而不包括数据,或者只导出指定用户的数据等。
4、更丰富的过滤选项:expdp/impdp提供了更多的过滤选项,可以根据需要指定导入导出的条件,例如导出特定时间段的数据、特定对象类型等。
5、支持压缩:expdp/impdp支持对导出的数据进行压缩处理,减小导出文件的大小,节省存储空间。
官方文档对expdp/impdp的介绍(12c版本):

expdp/impdp兼容性:
10.1.0.x.0 VERSION=9.2 ---9i(9.2)expdp的文件支持直接impdp到10g ---------- ------------- ------------- ------------- ------------- ------------- 10.2.0.x.0 VERSION=9.2 VERSION=10.1 ---9i(9.2)、10g(10.1) expdp的文件支持直接impdp到10gR2 ---------- ------------- ------------- ------------- ------------- ------------- 11.1.0.x.0 VERSION=9.2 VERSION=10.1 VERSION=10.2 ---9i(9.2)、10g(10.1)、10gR2(10.2) expdp的文件支持直接impdp到11g ---------- ------------- ------------- ------------- ------------- ------------- 11.2.0.x.0 VERSION=9.2 VERSION=10.1 VERSION=10.2 VERSION=11.1 ---9i(9.2)、10g(10.1)、10gR2(10.2)、11g(11.1) expdp的文件支持直接impdp到11gR2注意:expdp/impdp向上兼容,不向下兼容。各个数据库版本的expdp/impdp低版本兼容高版本,高版本不一定兼容低的。官方文档对在不同数据库版本之间的导出和导入做了详细描述,参考官方文档(12c):Overview of Oracle Data Pump

使用expdp和impdp的前提条件:
使用expdp/impdp时其转储文件只能被存放在directory对象对应的OS目录中,而不能直接指定转储文件所在的OS目录。所以在使用时必须建立directory对象并赋予使用对象权限。数据库目录对象只能由SYS 用户拥有,即使是其他用户创建的,该目录对象的用户也仍然是SYS。目录名在数据库中是唯一的,因为所有目录都位于一个名称空间(即SYS)中。
创建数据泵directory并赋权的语法:
SQL> create or replace directory directory_name as '/路径'; SQL> grant all on directory directory_name to user|public; ---除了sys,其他任何用户(包括system)都需要赋权才能使用目录
创建数据泵的dmp文件存放目录:
1)创建数据泵的directory(目录对象)。linux下的目录需要有oracle:oinstall权限
[root@LF]# mkdir /liu [root@LF]# chown oracle:oinstall /liu ###文件liu(路径/liu)在/dev/sdb3下挂载,将文件的所属用户和目录改为oracle:oinstall
SYS@orcl> create directory liu as '/liu'; SYS@orcl> grant all on directory liu to system ; ###创建数据泵的转储路径(在使用expdp时,指定到liu目录时,数据文件就会生成在/liu路径下)。赋予给所有用户目录liu的所有执行权限,为了以后普通用户使用expdp时有权限将dmp数据文件导入到/liu下。


1、expdp
expdp -help选项:
| 参数选项 | 描述 |
| userid | 用于指定执行导出操作的用户名,口令,连接字符串 |
| Directory | 指定转储文件和日志文件所在的目录。目录对象是使用create directory语句建立的对象,而不是os目录(如果没有指定direcory,那么通过数据泵导出的文件存储在data_pump_dir中,是通过数据泵导出的默认路径) |
| Schemas | 用于指定执行导出操作的方案(用户) |
| PARALLEL | 指定执行导出操作的并行进程个数,默认值为1。一般是cpu的2倍,2、4、8即可。如果设置并行数为4,那么系统中将有4个进程同时进行备份,会在目录下生成4个dmp文件 |
| Tables | 用于指定执行导出操作的表 |
| query | 指定导出表的前多少行(从where子句后开始) |
| TABLESPACES | 用于指定执行导出的表空间 |
| DUMPFILE | 用于指定转储文件的名称 |
| LOGFILE | 指定导出日志文件文件的名称 |
| FILESIZE | 以字节为单位指定每个转储文件的大小。默认0,表示转储文件没有限制 |
| FULL | 指定数据库模式导出,默认为n。为y时,表示执行数据库全库导出 |
| ESTIMATE_ONLY | 指定是否只估算导出作业所占用的磁盘空间,默认值为n。设置为y时导出作用只估算对象所占用的磁盘空间,而不会执行导出作业;为n时不仅估算对象所占用的磁盘空间还会执行导出操作。比如:expdp system/system full=y estimate_only=y |
| PARFILE | 指定导出参数文件的名称,可以写入expdp的所有参数。parfile=[directory_path] file_name。表比较多的情况下建议用parfile,各个参数在parfile里写好。比如:tables=test.liu,test.liufei |
| FLASHBACK_SCN | 指定导出特定scn时刻的表数据 |
| FLASHBACK_TIME | 指定导出特定时间点的表数据 |
| CLUSTER | 默认为Y。在11G R2后EXPDP/IMDP的WORKER进程会在多个INSTANCE启动,所以DIRECTORY必须在共享磁盘上,如果没有设置共享磁盘还是指定cluster=no来防止报错。 |
| COMPRESSION | 这个压缩比例可以和操作系统“gzip -9”相媲美,某些特例下有可能比gzip还要高效:1/7。 10g是提供两种参数选项METADATA_ONLY | NONE,基本上没有提供压缩功能。11g后提供四种参数选项ALL | DATA_ONLY | METADATA_ONLY | NONE。当设置为all压缩元数据和对象数据data_only只压缩对象数据 metadata_only只压缩元数据none不压缩任何数据。 |
| CONTENT | 该选项用于指定要导出的内容,默认值为all。三种参数选项all | data_only | metadata_only,当设置content为all 时,将导出对象定义及其所有数据;为data_only 时只导出对象数据;为metadata_only时,只导出对象定义。 |
| ESTIMATE | 指定估算被导出表所占用磁盘空间分方法,默认值是blocks。两种参数选项blocks | statistics,设置为blocks时oracle 会按照目标对象所占用的数据块个数乘以数据块尺寸估算对象占用的空间;设置为statistics时根据最近统计值估算对象占用空间。 |
| EXCLUDE | 该选项用于指定执行操作时释放要排除对象类型或相关对象 |
| INCLUDE | 指定导出时要包含的对象类型及相关对象 |
| VERSION | 用于指定被导出对象的数据库版本,默认compatible。三种参数选项compatable | latest |version_string,设置为compatible 根据compatible参数生成对象latest根据数据库的实际版本version_string指定数据库版本(必须大于9.2) |
expdp导出案例:
案例1:实例完全导出or集群(rac)环境的实例完全导出
1)单机实例的完全导出
[oracle@LF]# expdp \"/ as sysdba\" directory=directory_name dumpfile=expdp_orcl_full_%U.dmp logfile=expdp_orcl_full.log full=y parallel=2 ###1、在linux /unix上需要设置"/ as sysdba"为 \"/ as sysdba\"转译符号。 ###2、设置parallel=2时会生产两个dmp。同理如果设置并行数为4,那么系统中将有4个进程同时进行备份,会在目录下生成4个dmp文件,那么需要在dumpfile参数中加上%U对文件进行升序排序。
2)集群(rac)环境的实例完全导出(参数cluster=no。不仅仅在完全导出时加上该参数,对于在rac环境下的用户、表等的导出都要加上。并且impdp导入也需要设置cluster=no)
[oracle@LF]# expdp \"/ as sysdba\" directory=directory_name dumpfile=expdp_orcl_user_%U.dmp logfile=expdp_orcl_user.log full=y parallel=2 cluster=n ###1、设置parallel=2时会生产两个dmp。同理如果设置并行数为4,那么系统中将有4个进程同时进行备份,会在目录下生成4个dmp文件,那么需要在dumpfile参数中加上%U对文件进行升序排序。 ###2、如果是集群环境添加CLUSTER=n(默认为Y,集群环境必须为n):在11GR2后EXPDP/IMDP的WORKER进程会在多个INSTANCE启动,所以DIRECTORY必须在共享磁盘上,如果没有设置共享磁盘还是指定cluster=no来防止报错。 如果在rac环境不添加cluster=no参数,会报以下错误: EXP-00019: failed to process parameters, type 'EXP HELP=Y' for help EXP-00000: Export terminated unsuccessfully ORA-31693: Table data object "JATS001"."T_BA_BANKDAYBOOKS" failed to load/unload and is being skipped due to error: ORA-29913: error in executing ODCIEXTTABLEPOPULATE callout ORA-31617: unable to open dump file "/backup/expdp_jats001_02.dmp" for write ORA-19505: failed to identify file "/backup/expdp_jats001_02.dmp" ORA-27037: unable to obtain file status Linux-x86_64 Error: 2: No such file or directory 对于RAC环境而言,Oracle会尝试将并行导出放到两个节点上,而由于DIRECTORY是本地磁盘,且在另外一个节点上没有建立同样的目录,因此打开文件报错的信息。 那么如果想要使用RAC上的并行导出;确保相同的目录在两个节点上同时存在,可以开并行,不用设置cluster;如果只想在一个节点上执行数据泵的导出,必须将设置cluster=no参数,然后开并行
案例2:导出时限制导出文件大小(os文件大小有限制或者导出量太大)
[oracle@LF]# expdp \"/ as sysdba\" directory=directory_name dumpfile=expdp_orcl_full_%U.dmp logfile=expdp_orcl_full.log full=y parallel=2 filesize=200g
###expdp导出之前先预估数据量,expdp不会像exp那样达到了限制的导出文件大小而报错,因为expdp有%U参数,第一个01达到了限制的大小那么会继续02、03文件。
案例3:用户模式(用户的所有对象被输出到文件中)
方式一:通过生产用户直接导出,但是只能导出这一个用户的数据
[oracle@LF]# expdp user1/password directory=directory_name dumpfile=expdp_orcl_user_%U.dmp logfile=expdp_orcl_user.log parallel=2 ###设置parallel=2时会生产两个dmp。同理如果设置并行数为4,那么系统中将有4个进程同时进行备份,会在目录下生成4个dmp文件,那么需要在dumpfile参数中加上%U对文件进行升序排序。
方式二:使用sys用户,在linux /unix上需要设置"/ as sysdba"为 \"/ as sysdba\"转译符号。这种方式可以导出多个生产用户
[oracle@LF]# expdp \"/ as sysdba\" directory=directory_name dumpfile=expdp_orcl_user_%U.dmp logfile=expdp_orcl_user.log schemas=user1,user2 parallel=2 ###设置parallel=2时会生产两个dmp。同理如果设置并行数为4,那么系统中将有4个进程同时进行备份,会在目录下生成4个dmp文件,那么需要在dumpfile参数中加上%U对文件进行升序排序。
案例4:表模式:(用户的表被输出到文件中)
方式一:使用sys用户,在linux /unix上需要设置"/ as sysdba"为 \"/ as sysdba\"转译符号
[oracle@LF]# expdp \"/ as sysdba\" directory=directory_name dumpfile=expdp_orcl_table_%U.dmp logfile=expdp_orcl_table.log tables=user1.table1,user1.table2 parallel=2 ###设置parallel=2时会生产两个dmp。同理如果设置并行数为4,那么系统中将有4个进程同时进行备份,会在目录下生成4个dmp文件,那么需要在dumpfile参数中加上%U对文件进行升序排序。
方式二:通过生产用户直接导出
[oracle@LF]# expdp user1/password directory=directory_name dumpfile=expdp_orcl_table_%U.dmp logfile=expdp_orcl_table.log tables=table_name1,table_nam2 parallel=2 ###设置parallel=2时会生产两个dmp。同理如果设置并行数为4,那么系统中将有4个进程同时进行备份,会在目录下生成4个dmp文件,那么需要在dumpfile参数中加上%U对文件进行升序排序。
方式三:通过在INCLUDE=TABLE参数中加SQL语句,实现SQL语句在expdp层面将返回查询到的多个表进行导出
[oracle@LF]# expdp user1/password directory=directory_name dumpfile=expdp_orcl_table_%U.dmp logfile=expdp_orcl_table.log INCLUDE=TABLE:\"IN \( SQL语句 \)\" parallel=2 ###在expdp语句中需要将涉及到的双引号",括号(),单引号'等,都需要通过转译符号\进行转译。 eg案例: 原始SQL: SQL> SELECT table_name FROM user_tables WHERE table_name LIKE 'TABLE%' OR table_name LIKE 'D_' OR table_name='BM'; TABLE_NAME ------------------------------ TABLE_M1 TABLE_M10 TABLE_YG BM DD DQ 6 rows selected. 在INCLUDE=TABLE参数中加SQL语句: [oracle@11g full]$ expdp user/123456 directory=EXPDP_FULL dumpfile=expdp_orcl_table_%U.dmp logfile=expdp_orcl_table.log INCLUDE=TABLE:\"IN \(SELECT table_name FROM user_tables WHERE table_name LIKE \'TABLE%\' OR table_name LIKE \'D_\' OR table_name=\'BM\'\)\" parallel=2 ###在expdp语句中需要将涉及到的双引号",括号(),单引号'等,都需要通过转译符号\进行转译。 ###如下输出,SQL中查询出来的6张表都通过expdp导出了 Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production With the Partitioning, OLAP, Data Mining and Real Application Testing options FLASHBACK automatically enabled to preserve database integrity. Starting "USER"."SYS_EXPORT_SCHEMA_02": USER/******** directory=EXPDP_FULL dumpfile=expdp_orcl_table_%U.dmp logfile=expdp_table.log INCLUDE=TABLE:"IN (SELECT table_name FROM user_tables WHERE table_name LIKE 'TABLE%' OR table_name LIKE 'D_' OR table_name='BM')" parallel=2 Estimate in progress using BLOCKS method... Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA Total estimation using BLOCKS method: 30.12 MB . . exported "USER"."TABLE_M10" 18.77 MB 100000 rows . . exported "USER"."TABLE_YG" 2.426 MB 8000 rows . . exported "USER"."TABLE_M1" 1.885 MB 10000 rows . . exported "USER"."DQ" 5.476 KB 4 rows . . exported "USER"."BM" 0 KB 0 rows . . exported "USER"."DD" 0 KB 0 rows Processing object type SCHEMA_EXPORT/TABLE/TABLE Processing object type SCHEMA_EXPORT/TABLE/COMMENT Processing object type SCHEMA_EXPORT/TABLE/INDEX/INDEX Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINT Processing object type SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/REF_CONSTRAINT Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS Master table "USER"."SYS_EXPORT_SCHEMA_02" successfully loaded/unloaded ****************************************************************************** Dump file set for USER.SYS_EXPORT_SCHEMA_02 is: /backup/full/expdp_orcl_table_01.dmp /backup/full/expdp_orcl_table_02.dmp Job "USER"."SYS_EXPORT_SCHEMA_02" successfully completed at Sun Jan 21 16:46:11 2024 elapsed 0 00:00:45
案例5:导出生产用户某些表的前10行(query=" 'where rownum<10' ")
[oracle@LF]# expdp user1/password directory=directory_name dumpfile=expdp_orcl_table_%U.dmp logfile=expdp_orcl_table.log tables=table1 query=" 'where rownum<10' " parallel=2
###设置parallel=2时会生产两个dmp。同理如果设置并行数为4,那么系统中将有4个进程同时进行备份,会在目录下生成4个dmp文件,那么需要在dumpfile参数中加上%U对文件进行升序排序。
案例6:ESTIMATE_ONLY参数可估计导出作业占用的空间量(实际上并不执行导出,只测算导出的文件有多大)
[oracle@LF]# expdp \"/ as sysdba\" full=y estimate_only=y
### 使用estimate_only时,不需要指定directory和dumpfile,这个参数只能预估下dmp数据文件大小,做个预估
2、impdp
impdp -help选项:
| 参数选项 | 描述 |
| Userid | 用于指定执行导入操作的用户名,口令,连接字符串 |
| full | 用于指定执行导入整个文件,值为n|y |
| Directory | 指定目录对象名称,目录对象指定好了存储路径(如果没有指定direcory,那么通过数据泵导出的文件存储在data_pump_dir中,是通过数据泵导出的默认路径) |
| REMAP_DATAFILE | 将导出的数据文件指定导入到目标数据文件 |
| REMAP_TABLESPACE | 将导出的表空间指定导入到目标表空间。官方写法:REMAP_TABLESPACE=source_tablespace:target_tablespace |
| REMAP_TABLE | 将导出的表指定导入到目标表。官方写法:REMAP_TABLE=[schema.]old_tablename[.partition]:new_tablename |
| REMAP_SCHEMA | 将导出的用户指定导入到目标用户。官方写法:REMAP_SCHEMA=source_schema:target_schema |
| Schemas | 用于指定执行导出操作的方案(用户) |
| TABLESPACES | 指定导入的表空间列表 |
| TABLES | 指定导入的表 |
| REUSE_DATAFILES | 导入时是否覆盖已经存在的数据文件,默认为n |
| Sqlfile | 指定sqlfile参数可以显示执行的DDL语句。加上这个参数后就不会进行数据导入了,只会根据导入的dmp文件,将dmp文件涉及到的DDL语句输出到sqlfile指定的文件中。 |
| TRANSPORT_DATAFILES | 可传输模式导入的数据文件列表 |
| TABLE_EXISTS_ACTION | 如果导入的对象已经存在,要采取的操作。有效的关键字有:append(不删表,追加数据,没违反约束的值会全部插入。最推荐的方式,同imp的ignore=y。参考imp的ignore参数即可)、replace(删表后替换,替换成和导出的表一样的表结构包括导出表的分区结构,然后导入数据)、skip(默认值,有表时中断导入,不冲突的数据也不导入)和truncate(清空数据后导入数据) |
| CLUSTER | 默认为Y,建议为n。在11GR2后EXPDP/IMDP的WORKER进程会在多个INSTANCE启动,所以DIRECTORY必须在共享磁盘上,如果没有设置共享磁盘还是指定cluster=no来防止报错。 |
| CONTENT | 该选项用于指定要导入的内容,默认值为all。三种参数选项all | data_only | metadata_only,当设置content为all 时,将导入对象定义及其所有数据;为data_only 时只导入对象数据;为metadata_only时,只导出对象定义。 |
| VERSION | 用于指定被导出对象的数据库版本,默认compatible。三种参数选项compatable | latest |version_string,设置为compatible 根据compatible参数生成对象latest根据数据库的实际版本version_string指定数据库版本(必须大于9.2) |
| PARFILE | 指定导入参数文件的名称,可以写入impdp的所有参数。parfile=[directory_path] file_name。表比较多的情况下建议用parfile,各个参数在parfile里写好。比如:remap_table=test.liu:his_liu,test.liufei:his_liufei |
impdp导出案例:
对于impdp而言:可以没有full=y、schemas、tables
案例1:完全导入or集群(rac)环境的实例完全导入
1)单机实例的完全导入
[oracle@LF]# impdp \"/ as sysdba\" directory=directory_name dumpfile=expdp_orcl_full_%U.dmp logfile=impdp_orcl_full.log full=y parallel=2 table_exists_action=append(荐)|replace|skip|truncate ###在linux /unix上需要设置"/ as sysdba"为 \"/ as sysdba\"转译符号。
2)集群(rac)环境的实例完全导入(参数cluster=no。不仅仅在完全导入时加上该参数,对于在rac环境下的用户、表等的导入都要加上)
[oracle@LF]# impdp \"/ as sysdba\" directory=directory_name dumpfile=expdp_orcl_full_%U.dmp logfile=impdp_orcl_full.log full=y parallel=2 table_exists_action=append(荐)|replace|skip|truncate cluster=n ###如果是集群环境添加CLUSTER=n(默认为Y,集群环境必须为n):在11GR2后EXPDP/IMDP的WORKER进程会在多个INSTANCE启动,所以DIRECTORY必须在共享磁盘上,如果没有设置共享磁盘还是指定cluster=no来防止报错。
案例2:用户模式导入
[oracle@LF]# impdp \"/ as sysdba\" directory=directory_name dumpfile=expdp_orcl_user_%U.dmp logfile=impdp_orcl_user.log schemas=user1,user2 remap_schema=user1:user_new,user2:user_new parallel=2 table_exists_action=append(推荐)|replace|skip|truncate
###impdp和imp向不同用户导入时,imp用的为formuser和touser参数,impdp用的为remap_schema= user:user
案例3:表模式导入
注意:表模式导入时不管有没有remap_table,都需要加上tables。因为如果是全备的数据,只指定了remap_table那么其他不重命名的表也会导入,所以要加上tables限制导入那些表
[oracle@LF]# impdp \"/ as sysdba\" directory=directory_name dumpfile=expdp_orcl_table_%U.dmp logfile=impdp_orcl_table.log tables=user1.table1,user1.table2 parallel=2 table_exists_action=append(推荐)|replace|skip|truncate
错误案例:如果将导出表导入同用户下的其他表,则不能使用tables,需要替换为REMAP_TABLE=test.liufei:liufei_ls。需要注意的是不能写成 用户.表:用户:表 需要写为 用户.表:表 不然导入就会有歧义
[oracle@LF]# impdp \"/ as sysdba\" directory=expdp dumpfile=expdp_orcl_table_01.dmp logfile=impdp_orcl_table.log tables=test.liufei REMAP_TABLE=test.liufei:test.liufei_ls parallel=2 table_exists_action=append
Processing obiect tvpe TABLE EXPORT/TABLE/TABLE DATA
..imported "TEST" "TEST.LIUFEI LS" 5.468 KB 2 rows
Job "SYS"."SYS IMPORT FULL 01" successfully completed at Wed 0ct 21 14:28:18 2020 elapsed 0 00:00:02
正确案例:
[oracle@LF]# impdp \"/ as sysdba\" directory=expdp dumpfile=expdp_orcl_table_01.dmp logfile=impdp_orcl_table.log tables=test.liufei REMAP_TABLE=test.liufei:liufei_ls parallel=2 table_exists_action=append
案例4:导入某表的前10行
[oracle@LF]# impdp user1/password directory=directory_name dumpfile=expdp_orcl_table_%U.dmp logfile=impdp_orcl_table.log tables=table1 query=" 'where rownum<10' " parallel=2 table_exists_action=append(推荐)|replace|skip|truncate
3、expdp/impdp大表导入导出优化
expdp导出优化:
(1) 导出用到大型池(large pool),将sga调高提速
(2)开启并行PARALLEL,整数倍
(3)大表导出考虑排除统计信息的导出,exclude=statistics,后续导入后oracle会自动收集统计信息(以全库导出为例,导出的日志就会缺少INDEX_STATISTICS、TABLE_STATISTICS、MARKER)
(4)不建议在导出时排除索引的导出,exclude=index,因为后期还要手动创建(以全库导出为例,导出的日志就会缺少INDEX_STATISTICS、INDEX)
(5)expdp不会产生redo日志
impdp导入优化:
(1)导入用到大型池(large pool),将sga调高提速
(2)开启并行PARALLEL,整数倍
(3)大表导入可以考虑排除统计信息的导入,exclude=statistics,后续oracle会自动收集统计信息(以用户导入为例,导入的日志就会缺少INDEX_STATISTICS、TABLE_STATISTICS、MARKER)
(4)不建议在导入时排除索引的导入,exclude=index,因为后期还要手动创建(以用户导入为例,导入的日志就会缺少INDEX_STATISTICS、INDEX)
(5)impdp产生大量redo日志,通过TRANSFORM=DISABLE_ARCHIVE_LOGGING:Y 参数可以实现在导入的时候使用nologging处理从而减少日志量也增加速度,但是数据库在force logging情况下该参数无效,因为force logging一般有dg库开启,保证数据全部通过归档应用到dg库,即使append+nologging也是要写数据的
(6)导入过程中undo和temp占用很多,适当扩容
(7)对于上TB数据量在导入时,建议先导入对象定义CONTENT=metadata_only,然后再导入对象数据CONTENT=data_only。因为impdp先导入表数据(TABLE、TABLE_DATA),然后在导入索引(INDEX、INDEX_STATISTICS),这样会在全表数据上创建索引,延迟了导入时间;先导入对象定义CONTENT=metadata_only(TABLE、TABLE_DATA、INDEX、INDEX_STATISTICS)这样会在空表上创建索引,速度会变快,最后导入对象数据CONTENT=data_only,参考“expdp迁移字符集”文档,也是先导对象定义,然后导对象数据
4、expdp/impdp后台进程的管理
在 进行expdp(数据泵导出工具)和 impdp(数据泵导入工具)中Oracle提供了后台管理,便于观察在导入和导出的情况和进度。
相关视图:
SQL> select * from dba_datapump_jobs; ---查询datapump jobs(只是针对数据泵的jobs视图)
JOB_NAME:执行数据泵导出的job名
OPERATION:job的类型,分为EXPORT(导出)、IMPORT(导入)
STATE:job当前的状态,EXECUTING(正在导出)、NOT RUNNING(没有运行的job,可以清理或者START_JOB)
(1)expdp时数据泵的后台进程
[oracle@lf ~]$ expdp -help
| 参数选项 | 描述 |
| ATTACH | 该选项用于在客户会话与已存在导出作用之间建立关联。用于指定方案名job_name用于指定导出作业名。如果使用attach选项,在命令行除了连接字符串和attach 选项外,不能指定任何其他选项。例:expdp scott/tiger attach=scott.export_job |
| JOB_NAME | 指定数据泵导出时的job名,默认为sys_xxx |
| STOP_JOB | 停止job不删除(通过dba_datapump_jobs视图发现job还是存在的,进入到当前job通过START_JOB可以再次启动job) |
| KILL_JOB | 停止job任务并删除(job在dba_datapump_jobs视图中删除) |
expdp全库导出:
[oracle@lf ~]# expdp \"/ as sysdba\" directory=BACKUP20200328 dumpfile=expdp_orcl_full_%U.dmp logfile=expdp_orcl_full.log full=y parallel=2
查看数据泵相关jobs任务:
SQL> select * from dba_datapump_jobs; ---查询datapump jobs(只是针对数据泵的jobs视图)
管理EXPORT导出的job(有时将expdp kill掉导出的文件还是一直增加,就需要进入数据库查看数据泵的job):
[oracle@lf ~]$ expdp system/123456@orcl_pdb1 attach=SYS_EXPORT_FULL_01 export> status
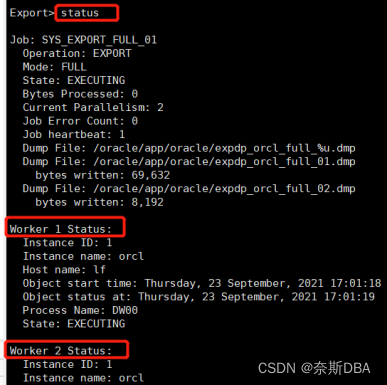
注:异常或者停止(NOT RUNNING)的job,如果不启用,清除的话需要登录到OWNER_NAME下,进行drop table JOB_NAME才能清除,不然是没有其他办法在dba_datapump_jobs视图中清除的
[oracle@lf ~]$ sqlplus system/123456@orcl_pdb1 ###登录到数据泵执行job的用户下才能清除,或者加上OWNER_NAME SQL> drop table SYS_EXPORT_FULL_01;
(2)impdp时数据泵的后台进程(可以确定导入的行数,确定进度)
[oracle@lf ~]$ impdp -help
| 参数选项 | 描述 |
| ATTACH | 该选项用于在客户会话与已存在导出作用之间建立关联。用于指定方案名job_name用于指定导出作业名。如果使用attach选项,在命令行除了连接字符串和attach 选项外,不能指定任何其他选项。例:expdp scott/tiger attach=scott.export_job |
| JOB_NAME | 指定数据泵导出时的job名,默认为sys_xxx |
| STOP_JOB | 停止job不删除(通过dba_datapump_jobs视图发现job还是存在的,进入到当前job通过START_JOB可以再次启动job) |
| KILL_JOB | 停止job任务并删除(job在dba_datapump_jobs视图中删除) |
impdp全库导入:
[oracle@lf ~]$ impdp \"/ as sysdba\" directory=baj_dir dumpfile=expdp_orcl_full_01.dmp,expdp_orcl_full_02.dmp logfile=impdp_orcl_full.log full=y parallel=4 table_exists_action=append PARFILE=exclude.par
查看数据泵相关jobs任务:
SQL> select * from dba_datapump_jobs; ---查询datapump jobs(只是针对数据泵的jobs视图)

管理IMPORT导入的job(有时将impdp kill并不会杀掉job,就需要进入数据库查看数据泵的job):
[oracle@lf ~]$ impdp system/123456@orcl_pdb1 attach=SYS_IMPORT_TABLE_01 Import> status Worker 1 Status: Instance ID: 1 Instance name: orcl Host name: lf Object start time: Thursday, 23 September, 2021 18:07:37 Object status at: Thursday, 23 September, 2021 18:07:37 Process Name: DW00 State: EXECUTING Object Schema: TEST Object Name: LF_MEMBER Object Type: DATABASE_EXPORT/SCHEMA/TABLE/TABLE_DATA ---执行数据导入 Completed Objects: 1 Completed Rows: 9,174,240 ---导入的行数(LF_MEMBER有一千万行) Completed Bytes: 1,886,137,912 ---导入数据的bytes大小 Percent Done: 91 ---进行到的百分比,可以确定进度 Worker Parallelism: 1
注:异常或者停止(NOT RUNNING)的job,如果不启用,清除的话需要登录到OWNER_NAME下,进行drop table JOB_NAME才能清除,不然是没有其他办法在dba_datapump_jobs视图中清除的
[oracle@lf ~]$ sqlplus system/123456@orcl_pdb1 ###登录到数据泵执行job的用户下才能清除,或者加上OWNER_NAME SQL> drop table SYS_IMPORT_TABLE_01;
5、linux系统上制定expdp的定时全库备份
通过crontab制定备份策略,并结合expdp工具的使用,我们可以有效地保障数据库数据的完整性和可恢复性。
(1)数据备份的路径规划:
在root用户下进行路径规划:
[root@lf ~]$ mkdir /backup
###通过存储挂到/backup目录下,权限oracle用户
[root@lf ~]$ cd /backup
[root@lf backup]$ mkdir full
[root@lf backup]$ mkdir script
[root@lf backup]# mkdir logs
### full(expdp全备的数据)、script(备份脚本)、logs(备份日志)
[root@lf /]# chown -R oracle:oinstall /backup/(2)创建数据泵directory并赋权
SYS@orcl> create directory expdp_full as '/backup/full';
SYS@orcl> grant all on directory expdp_full to system ;
###创建数据泵的转储路径(在使用expdp时,指定到/backup/full目录时,数据文件就会生成在/backup/full路径下)。赋予给所有用户目录/backup/full的所有执行权限,为了以后普通用户使用expdp时有权限将dmp数据文件导入到/backup/full下。(3)expdp全备脚本
[root@lf ~]$ su - oracle
[oracle@lf backup]$ cd script/
[oracle@lf script]$ vi expdp_orcl_full.sh
export BAKDATE=`date +%Y%m%d`
export ORACLE_SID=orcl
export ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1
nohup $ORACLE_HOME/bin/expdp \"/ as sysdba\" directory=expdp_full dumpfile=expdp_${ORACLE_SID}_full_%U_${BAKDATE}.dmp logfile=expdp_${ORACLE_SID}_full_${BAKDATE}.log full=y parallel=4 &
###如果是集群环境添加CLUSTER=n(默认为Y,建议为n):在11GR2后EXPDP/IMDP的WORKER进程会在多个INSTANCE启动,所以DIRECTORY必须在共享磁盘上,如果没有设置共享磁盘还是指定cluster=no来防止报错。
find /backup/full -name "expdp_${ORACLE_SID}_full_*.log" -mtime +2 -exec rm -rf {} \;
find /backup/full -name "expdp_${ORACLE_SID}_full_*.dmp" -mtime +2 -exec rm -rf {} \; ###mtime +2 -exec rm -rf {} \; 表示删除目录下2天之前被修改过的文件。写为mtine是因为默认输入ls -l(ll)命令输出的内容中就是最后修改时间 (mtime)。rman 进行crosscheck就会把所有的备份片访问一遍,那么如果写-atime(被访问过的文件)就不是实际之前的文件了,从而导致删除失效。因为计划任务是每天执行,所以find查出2天之前的进行rm删除,也就是保留2天的2份。(4)在oracle用户下定义exp全备和清理备份的计划任务
[root@lf ~]$ su - oracle
[oracle@lf script]# chmod 775 /backup/script/*.sh ###确保root用户有执行权限
[oracle@lf script]# crontab -e
00 05 * * * sh /backup/script/expdp_orcl_full.sh ###每日凌晨5进行一次expdp全备(5)oracle用户下测试脚本可用性,通过dba_directories视图查看到目录的位置
[oracle@lf script]# sh /backup/script/expdp_orcl_full.sh
[oracle@lf01 full]$ tail -2000f /backup/full/expdp_orcl_full*.log
我敲真累啊,终于写完了,但看到这些整理好的信息,觉得一切都值得了。感谢各位小伙伴的陪伴与支持,觉得今天的分享有所帮助,不妨点个赞加个关注,给予我一些鼓励吧!那么下一篇介绍真实的案例从GBK到UTF8编码的迁移,那么我们下篇见!

















 1504
1504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











