







💫《博主介绍》:✨又是一天没白过,我是奈斯,DBA一名✨
💫《擅长领域》:✌️擅长Oracle、MySQL、SQLserver、阿里云AnalyticDB for MySQL(分布式数据仓库)、Linux,也在扩展大数据方向的知识面✌️
💖💖💖大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注💖💖💖

近期身处的项目任务繁重,感觉自己每一刻都仿佛被时间追赶。为了在周一之前把这篇文章淦完,在前一天经过三个小时的奋笔疾书,终于在周一的曙光到来之前,完成了这篇博客。希望能为各位小伙伴带来一丝启发。感谢各位的支持与陪伴,让我们一起努力,共同成长!
如文章标题所介绍的,今天是学习mysqlpump相关内容。MySQL Pump是MySQL官方提供的一个用于备份和恢复MySQL数据库的工具。它于MySQL 5.7.8版本中首次引入,旨在提供一种快速、可靠且高效的备份和恢复解决方案。MySQL Pump首次支持了 并行导出、压缩导出 ,可以利用多核CPU来提高备份能力,在效率上要比mysqldump要高很多。mysqlpump同mysqldump一样哦 导出的文件以SQL语句的形式 。
mysql逻辑迁移工具的介绍和案例,我会分成四篇内容内容进行讲解,四篇的内容分别如下:
- 第一篇:一文搞清mysqldump逻辑迁移工具的用法和定时全备实例
- 第二篇:一文搞清mysqlpump逻辑迁移工具的用法和定时全备实例(当前篇)
- 第三篇:mysqlpump和mysqldump参数区别总汇
- 第四篇:使用mysqldump全量+mysqlbinlog增量完成实例的全库恢复
目录
4、linux系统上制定mysqlpump的定时全库备份和binlog日志的定时备份
mysqlpump相比于mysqldump的优势:
1. 并行处理能力:
mysqlpump支持基于表的 并行备份 ,可以显著加快备份过程。这对于大型数据库来说尤为重要,因为它能够充分利用多核处理器的性能,减少备份所需的时间。相比之下,mysqldump的备份过程通常是串行化的,不具备并行备份的能力。
2. 更细粒度的备份控制:mysqlpump提供了更精细的控制选项,允许用户更好地选择和管理要备份的数据库或数据库对象。这包括触发器、存储过程、存储函数、数据库账户等,使得备份过程更加灵活和定制化。
3. 账户备份方式:在备份用户账号时,mysqlpump将其转换为帐户管理语句(如CREATE USER、GRANT),而不是像mysqldump那样直接插入到MySQL的系统数据库中。这种方式使得备份数据更加清晰和易于管理。
4. 备份效率:在重新加载备份文件时,mysqlpump采用了一种优化策略,即先建表后插入数据最后建立索引。这种方式减少了索引维护的开销,从而加快了还原速度。相比之下,mysqldump在还原时可能需要更多的时间和资源。
5. 支持压缩备份:
mysqlpump支持对导出的数据进行压缩处理,减小导出文件的大小,节省存储空间。

官方文档对mysqlpump的介绍(8.0版本):
https://dev.mysql.com/doc/refman/8.0/en/mysqlpump.html#mysqlpump-syntax

1、mysqlpump导出语法:
mysqlpump --help选项:
| 参数选项 | 描述 |
| -u, --user=name | 用于指定执行导出操作的用户名 |
| -p, --password[=name] | 用于指定执行导出操作的用户名密码 |
| -h, --host=name | 指定连接的主机IP |
| -P, --port=# | 大写P,用于指定端口,默认3306 |
| > | 用于指定导出的文件名 |
| -A, --all-databases | 导出所有数据库。对于默认数据库只导出数据库mysql,其他三个库不导出 |
| -B, --databases | 导出指定的数据库 |
| --log-error-file=name | 输出导入时的错误日志 |
| --set-charset | 是否开启字符集,--set-charset=1|0(默认开启) |
| --default-character-set=name | 指定字符集。如:utf8、gbk、utf8mb4 |
| --routines | 导出函数、存储过程(默认导出) |
| --triggers | 导出触发器(默认导出) |
| --events | 导出调度事件(默认导出) |
| --extended-insert=# | 定义一个insert语句包含多少个值,默认一个insert包含250个值。如果导出的数据量较大那么导入时频繁的I/O影响导入时间,数据写到redo log file才返回commit completed成功字样,为了减少了buffer到磁盘的次数,建议在1万,5万,10万。太大的话会占用过多的buffer(mysqldump支持开启还是关闭多值insert插入,但不支持定义一个insert包含多少个值) |
| --add-drop-database | 在CREATE DATABASE前DROP DATABASE。如果mysql中有对应导入的数据库那么导入会失败,加上参数后,删除后添加(默认关闭) |
| --add-drop-table | 导出时在CREATE TABLE前DROP TABLE IF EXISTS。如果导入mysql中有对应导入的表那么导入会失败,加上参数后,删除后添加(默认关闭) |
| --skip-add-drop-table | 跳过创建之前删除存在的表,如果目标表中有这个表并且有数据,那么会先删除表,所以按照情况是否需要加上这个参数。需要注意如果加上了--skip-add-drop-table参数,在导入时使用--force只是强制继续,即使我们得到一个SQL错误。如果导入时提示表存在(ERROR 1050 (42S01) at line 24: Table 'qwe' already exists),那么就会中断导入这个进程,加上此参数的话那么就先忽略这张已经存在的表或者这些表,强制继续导入下一张表。需要注意的是并不会对已经存在的表追加数据,只是忽略而已。 |
| -d, --skip-dump-rows | 不导出表中的数据,只导出结构 |
| --no-create-db | 不导出CREATE DATABASE创建数据库结构 |
| -t, --no-create-info | 不导出CREATE TABLE创建表结构 |
| --add-locks | 用LOCK TABLES和UNLOCK TABLES语句包围每个表转储(默认关闭) |
| --single-transaction | 开启InnoDB表的一致性快照备份,可以不锁表,保证数据备份一致性的参数,只针对innodb导出过程中不允许运行表的DDL操作。因为事务持有表的metadata lock的共享锁,而DDL会申请metadata lock的互斥锁,所以会阻塞。--single-transaction关掉默认--lock-tables选项(即不加锁),因为mysqldump默认会打开一个lock-tables在导出过程中锁住所有的表。 |
| --set-gtid-purged=name | 在文件中是否添加SET @MYSQLDUMP_TEMP_LOG_BIN、SET @@SESSION.SQL_LOG_BIN、SET @@GLOBAL.GTID_PURGED |
| mysqlpump相对与mysqldump多出来的参数 | |
| --compress-output=name | 压缩输出,目前可以使用压缩的算法有lz4和zlib(默认关闭) |
| --default-parallelism=# | 指定并行线程数据,如果设置0就不并行备份,如果是单表则并行无效。每个线程在导入的时候,先写数据,最后再创二级索引(主键索引在创建表的时候建立,默认2个并行) |
| --parallel-schemas=name | 指定并行备份的库。例:--parallel-schemas=6:db1,3:db2 (6个线程备份数据库db1,3个线程备份数据库db2) |
| --defer-table-indexes | 延迟创建索引,直到所有的数据都加载完了之后再创建索引,如果关闭(--skip-defer-table-indexes)就和 mysqldump 类似了,先创建表和索引,再导数据就慢了(默认开启) |
| --watch-progress | 显示在错误输出上定期转储进程进度信息。进度信息包括已完成的表、行和收集的其他对象的总数(默认开启) |
| --users | 导出用户和权限。导出mysql库下的所有用户CREATE USER and GRANT(默认关闭) |
| --exclude-databases=name | 排除对象(pump支持,dump不支持) |
| --include-databases=name | 指定包含的对象(pump支持,dump不支持) |
mysqlpump导出案例:
案例1:全库导出
全库导出不压缩:
[root@mgr1 ~]# mysqlpump -uroot -p123456 --set-gtid-purged=OFF --single-transaction --users --default-parallelism=2 --all-databases --exclude-databases=mysql --log-error-file=mysqlpump_full_3306_err.log --extended-insert=10000 --socket=sock文件(多实例时需要指定。或者-hip地址 -P端口) > mysqlpump_full_3306.sql ###1、所有数据库导出只包括mysql数据库,其他三个默认数据库是不导出的,同mysqldump。 ###2、mysqlpump的--users参数可以导出mysql库下所有用户的权限,而mysqldump没有参数可以导出用户和权限,可以通过导出mysql库(权限和用户都在mysql数据库中)或者写脚本实现。 ###3、参数--exclude-databases=mysql是为了排查mysql库的导出,全备时会导出mysql数据库,那么在导入时,新实例也有mysql库,导入就会冲突,所以全库导出排除mysql库,因为加上了--users参数,所以用户权限导出不受影响。 ###4、加上--set-gtid-purged=OFF参数,不仅会去掉GTID_PURGED还会有SQL_LOG_BIN被取掉,加上--set-gtid-purged=OFF参数可以解决的问题: 1)加上--set-gtid-purged=OFF参数的话就不会因为导入目标库时,GTID_EXECUTED参数不为空而导致报错:GTID_PURGED can only be set when GTID_EXECUTED is empty了。 2)关于mysqlpump导出时会设置SQL_LOG_BIN=0,那么当前会话的操作都不记录到二进制日志中了,就会在主从复制架构模式导入数据时出现一个问题,主库同步了mysqlpump导入的数据,但是从库就没有mysqlpump的数据,官方文档表示可以通过设置--set-gtid-purged=OFF去掉参数SQL_LOG_BIN=0,但是实际并没有被去掉,所以这是一个bug(关于bug的截图可以参考mysqldump那篇文章哦),在官方没有修复这个bug之前,那么非要使用mysqlpump导入主从架构模式,就只能主库执行一遍,从库执行一遍;或者不使用mysqlpump,直接使用mysqldump就行喽,因为mysqldump没有这个bug。
全部压缩导出:
[root@mgr1 ~]# mysqlpump -uroot -p123456 --set-gtid-purged=OFF --single-transaction --users --compress-output=lz4 | zlib --default-parallelism=2 --log-error-file=mysqlpump_full_3306_err.log --all-databases --exclude-databases=mysql --extended-insert=10000 --socket=sock文件(多实例时需要指定。或者-hip地址 -P端口) > mysqlpump_full_3306.sql.lz4 | zlib ###1、所有数据库导出只包括mysql数据库,其他三个默认数据库是不导出的,同mysqldump。 ###2、mysqlpump的--users参数可以导出mysql库下所有用户的权限,而mysqldump没有参数可以导出用户和权限,可以通过导出mysql库(权限和用户都在mysql数据库中)或者写脚本实现。 ###3、参数--exclude-databases=mysql是为了排查mysql库的导出,全备时会导出mysql数据库,那么在导入时,新实例也有mysql库,导入就会冲突,所以全库导出排除mysql库,因为加上了--users参数,所以用户权限导出不受影响。 ###4、参数--compress-output为压缩导出,目前可以使用压缩的算法有lz4和zlib。 ###5、加上--set-gtid-purged=OFF参数,不仅会去掉GTID_PURGED还会有SQL_LOG_BIN被取掉,加上--set-gtid-purged=OFF参数可以解决的问题: 1)加上--set-gtid-purged=OFF参数的话就不会因为导入目标库时,GTID_EXECUTED参数不为空而导致报错:GTID_PURGED can only be set when GTID_EXECUTED is empty了。 2)关于mysqlpump导出时会设置SQL_LOG_BIN=0,那么当前会话的操作都不记录到二进制日志中了,就会在主从复制架构模式导入数据时出现一个问题,主库同步了mysqlpump导入的数据,但是从库就没有mysqlpump的数据,官方文档表示可以通过设置--set-gtid-purged=OFF去掉参数SQL_LOG_BIN=0,但是实际并没有被去掉,所以这是一个bug(关于bug的截图可以参考mysqldump那篇文章哦),在官方没有修复这个bug之前,那么非要使用mysqlpump导入主从架构模式,就只能主库执行一遍,从库执行一遍;或者不使用mysqlpump,直接使用mysqldump就行喽,因为mysqldump没有这个bug。
案例2:远端备份(异机上直接运行,备份到异机本地)
[root@mgr1 ~]# mysqlpump -uroot -p123456 --set-gtid-purged=OFF --single-transaction --users --default-parallelism=2 --all-databases --exclude-databases=mysql --log-error-file=mysqlpump_full_3306_err.log --extended-insert=10000 -hip地址 -P端口 > mysqlpump_full_3306.sql
###1、所有数据库导出只包括mysql数据库,其他三个默认数据库是不导出的,同mysqldump。
###2、mysqlpump的--users参数可以导出mysql库下所有用户的权限,而mysqldump没有参数可以导出用户和权限,可以通过导出mysql库(权限和用户都在mysql数据库中)或者写脚本实现。
###3、参数--exclude-databases=mysql是为了排查mysql库的导出,全备时会导出mysql数据库,那么在导入时,新实例也有mysql库,导入就会冲突,所以全库导出排除mysql库,因为加上了--users参数,所以用户权限导出不受影响。
###4、加上--set-gtid-purged=OFF参数,不仅会去掉GTID_PURGED还会有SQL_LOG_BIN被取掉,加上--set-gtid-purged=OFF参数可以解决的问题:
1)加上--set-gtid-purged=OFF参数的话就不会因为导入目标库时,GTID_EXECUTED参数不为空而导致报错:GTID_PURGED can only be set when GTID_EXECUTED is empty了。
2)关于mysqlpump导出时会设置SQL_LOG_BIN=0,那么当前会话的操作都不记录到二进制日志中了,就会在主从复制架构模式导入数据时出现一个问题,主库同步了mysqlpump导入的数据,但是从库就没有mysqlpump的数据,官方文档表示可以通过设置--set-gtid-purged=OFF去掉参数SQL_LOG_BIN=0,但是实际并没有被去掉,所以这是一个bug(关于bug的截图可以参考mysqldump那篇文章哦),在官方没有修复这个bug之前,那么非要使用mysqlpump导入主从架构模式,就只能主库执行一遍,从库执行一遍;或者不使用mysqlpump,直接使用mysqldump就行喽,因为mysqldump没有这个bug。
案例3:指定数据库导出
[root@mgr1 ~]# mysqlpump -uroot -p123456 --set-gtid-purged=OFF --single-transaction --users --default-parallelism=2 --databases db1 db2 --log-error-file=mysqlpump_db1_3306_err.log --extended-insert=10000 --socket=sock文件(多实例时需要指定。或者-hip地址 -P端口) > mysqlpump_db1_3306.sql
###1、导出db1、db2数据库
###2、mysqlpump的--users参数可以导出mysql库下所有用户的权限,而mysqldump没有参数可以导出用户和权限,可以通过导出mysql库(权限和用户都在mysql数据库中)或者写脚本实现。
###3、加上--set-gtid-purged=OFF参数,不仅会去掉GTID_PURGED还会有SQL_LOG_BIN被取掉,加上--set-gtid-purged=OFF参数可以解决的问题:
1)加上--set-gtid-purged=OFF参数的话就不会因为导入目标库时,GTID_EXECUTED参数不为空而导致报错:GTID_PURGED can only be set when GTID_EXECUTED is empty了。
2)关于mysqlpump导出时会设置SQL_LOG_BIN=0,那么当前会话的操作都不记录到二进制日志中了,就会在主从复制架构模式导入数据时出现一个问题,主库同步了mysqlpump导入的数据,但是从库就没有mysqlpump的数据,官方文档表示可以通过设置--set-gtid-purged=OFF去掉参数SQL_LOG_BIN=0,但是实际并没有被去掉,所以这是一个bug(关于bug的截图可以参考mysqldump那篇文章哦),在官方没有修复这个bug之前,那么非要使用mysqlpump导入主从架构模式,就只能主库执行一遍,从库执行一遍;或者不使用mysqlpump,直接使用mysqldump就行喽,因为mysqldump没有这个bug。
案例4:导出指定表
[root@mgr1 ~]# mysqlpump -uroot -p123456 --set-gtid-purged=OFF --single-transaction --default-parallelism=2 --log-error-file=mysqlpump_tb1_3306_err.log --include-databases test --include-tables tb1,tb2 --extended-insert=10000 --socket=sock文件(多实例时需要指定。或者-hip地址 -P端口) > mysqlpump_tb1_3306.sql
###1、导出test库tb1和tb2
###2、需要注意mysqlpump导出表需要同时使用--include-tables和--include-databases参数,只使用--include-tables是不行的,因为假设如果只指定--include-tables=bm那么就会导出所有库中bm表,表名之间逗号隔开。
###3、加上--set-gtid-purged=OFF参数,不仅会去掉GTID_PURGED还会有SQL_LOG_BIN被取掉,加上--set-gtid-purged=OFF参数可以解决的问题:
1)加上--set-gtid-purged=OFF参数的话就不会因为导入目标库时,GTID_EXECUTED参数不为空而导致报错:GTID_PURGED can only be set when GTID_EXECUTED is empty了。
2)关于mysqlpump导出时会设置SQL_LOG_BIN=0,那么当前会话的操作都不记录到二进制日志中了,就会在主从复制架构模式导入数据时出现一个问题,主库同步了mysqlpump导入的数据,但是从库就没有mysqlpump的数据,官方文档表示可以通过设置--set-gtid-purged=OFF去掉参数SQL_LOG_BIN=0,但是实际并没有被去掉,所以这是一个bug(关于bug的截图可以参考mysqldump那篇文章哦),在官方没有修复这个bug之前,那么非要使用mysqlpump导入主从架构模式,就只能主库执行一遍,从库执行一遍;或者不使用mysqlpump,直接使用mysqldump就行喽,因为mysqldump没有这个bug。
2、mysqlpump导入语法:
小提示:
mysqlpump的导入过程确实让人有些无奈。尽管它在导出数据时提供了 并行导出和压缩导出 的高效功能,但到了导入环节,却 与mysqldump无异 ,仍然依赖于传统的mysql命令来执行。这意味着,我们不得不面对一个相对漫长且看似“默默”进行的后台导入过程。在这个过程中,除了等待和祈祷导入顺利完成,我们能做的也只是 时不时查看后台进程是否还在运行 。不得不说,与导出时的便捷和高效相比,mysqlpump的导入环节确实显得有些单调和乏善可陈。希望未来能有更多的改进和优化,让mysqlpump的导入也能变得同样高效和便捷。
mysql --help选项:
| 参数选项 | 描述 |
| < | 用于指定导入的文件名 |
| -u, --user=name | 用于指定执行导入操作的用户名 |
| -p, --password[=name] | 用于指定执行导出操作的用户名密码 |
| -h, --host=name | 指定连接的主机IP |
| -P, --port=# | 大写P,用于指定端口,默认3306 |
| -o, --one-database | 指定连接的数据库(直接就连接进去了) |
| -f, --force | 强制继续,即使我们得到一个SQL错误。如果导入时提示表存在(ERROR 1050 (42S01) at line 24: Table 'qwe' already exists),那么就会中断导入这个进程,加上此参数的话那么就先忽略这张已经存在的表或者这些表,强制继续导入下一张表。需要注意的是并不会对已经存在的表追加数据,只是忽略而已。 |
| --default-character-set=name | 指定导入数据时的默认字符集编码(utf8、utf8mb4)。出现导入数据时的默认编码(utf8mb4)与导出文件的默认编码(utf8)不一致,就会报错ERROR at line 1474: Unknown command '\Z'.ERROR at line 1474: Unknown command '\?,那么就需要指定导入数据时的默认字符集编码,通过show variables like '%character_set%'; 确定 |
mysql导入案例:
案例1:全备数据库导入
小提示:
前提是进行了mysqlpump全备
[root@mysql ~]# mysql -uroot -p123456 --force < mysqlpump_full_3306.sql
###mysqlpump下的--users参数可以导出mysql库下所有用户的权限,但是使用--users导出了所有的用户和权限那么在导入时,就会导致创建'root'@'localhost'、'mysql.sys'@'localhost'、'mysql.session'@'localhost'这三个用户冲突,所以使用--force:强制继续。
案例2:指定数据库导入
小提示:
前提是进行了某个数据库的mysqldump备份。如果是全备,那么就是全库导入了,而不是指定数据库导入,因为导入时不能指定数据库导入
[root@mysql ~]# mysql -uroot -p123456 --force < mysqlpump_db1_3306.sql
###mysqlpump下的--users参数可以导出mysql库下所有用户的权限,但是使用--users导出了所有的用户和权限那么在导入时,就会导致创建'root'@'localhost'、'mysql.sys'@'localhost'、'mysql.session'@'localhost'这三个用户冲突,所以使用--force:强制继续。
案例3:导入指定表
小提示:
前提是进行了某个表的mysqldump备份,如果是全备,那么就是全库导入了,而不是指定表的导入,因为导入时不能指定表导入
[root@mgr1 ~]# mysql -uroot -p123456 -o database_name < mysqlpump_tb1_3306.sql
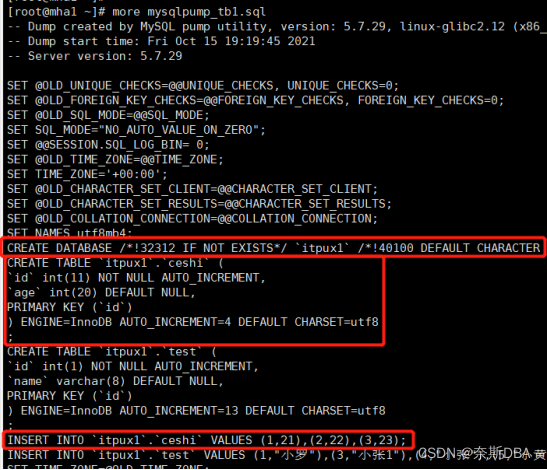
注意:mysqlpump导出某张表时,不会有use database,但会有create database,在创建表时会写成schema.table_name;insert会写成schema.table_name。
如果导入同实例不同的库就不能写成mysql那样去导入,不需要create database新的库名,需要将所有旧的schema(库名)替换掉,将文件中的test库替换为test_new库(g:替换文件中所有的关键字):%s/test/test_new/g。然后mysql -uroot -p123456 < mysqlpump_tb1_3306.sql(不用写-o参数,因为目前没有这个库,写上报Unknown database 'itpux1_new',sql文件中有会创建的)
3、mysqlpump导出和导入常见问题
mysqlpump的导出导入问题?嘿嘿,别着急,那些坑坑洼洼我都已经帮你在mysqldump的博客里填平啦!想探险的小伙伴,快去看看那篇博客吧(直通车👉【MySQL篇】一文搞清mysqldump逻辑迁移工具的用法和定时全备实例(第一篇,总共四篇)-CSDN博客👈),我这里就不给你“画蛇添足”啦!记得,学习路上,偶尔也可以搭个“顺风车”哦!
4、linux系统上制定mysqlpump的定时全库备份和binlog日志的定时备份
通过crontab制定备份策略,实现对mysqlpump的定时全库备份以及binlog日志的定时备份。binlog日志作为MySQL数据库的重要组成部分,记录了数据库的所有变更操作,对于数据恢复和故障排查具有重要意义。通过定时备份binlog日志,我们可以为数据库的恢复操作提供更为丰富的数据支持。
(1)数据备份的路径规划:
[root@mysql1 ~]# mkdir -p /mysql/backup/full
[root@mysql1 ~]# mkdir -p /mysql/backup/logs
[root@mysql1 ~]# mkdir -p /mysql/backup/binlog
[root@mysql1 ~]# mkdir -p /mysql/backup/script
###full(mysqldump全备的数据)、script(备份脚本)、binlog(需要打开binlog日志功能)、logs(备份日志)
[root@mysql1 ~]# chown -R mysql:mysql /mysql/backup/ (2)mysqlpump全备脚本
[root@mysql1 ~]# cd script/
[root@mysql1 ~]# vi mysqlpump_full_3306.sh
Date=`date +%Y%m%d`
Begin=`date +"%Y-%m-%d"`
Port=3306
/mysql/app/mysql/bin/mysqlpump -uroot -p123456 --set-gtid-purged=OFF --single-transaction --users --default-parallelism=2 --all-databases --exclude-databases=mysql --log-error-file=/mysql/backup/logs/mysqlpump_full_${Port}_${Date}_err.log --extended-insert=10000 --socket=sock文件(多实例时需要指定。或者-hip地址 -P端口) > /mysql/backup/full/mysqlpump_full_${Port}_${Date}.sql ###所有数据库导出只包括mysql数据库,其他三个默认数据库是不导出的,同mysqldump
/mysql/app/mysql/bin/mysqlpump -uroot -p123456 --set-gtid-purged=OFF --single-transaction --default-parallelism=2 --databases sys performance_schema information_schema --log-error-file=/mysql/backup/logs/mysqlpump_sys_${Port}_${Date}_err.log --extended-insert=10000 --socket=sock文件(多实例时需要指定。或者-hip地址 -P端口) > /mysql/backup/full/mysqlpump_sys_${Port}_${Date}.sql ###在全备时不会对默认数据库 performance_schema、information_schema、sys这些只保存性能的数据库进行备份。如果需要单独备份
#Function export user privileges ---不需要导出权限脚本
###mysqlpump下的--users参数可以导出mysql库下所有用户的权限,但是使用--users导出了所有的用户和权限那么在导入时,就会导致创建'root'@'localhost'、'mysql.sys'@'localhost'、'mysql.session'@'localhost'这三个用户冲突,所以使用--force:强制继续。
find /mysql/backup/logs/ -name "mysqlpump_*_${Port}_*_err.log" -mtime +2 -exec rm -rf {} \;
find /mysql/backup/full/ -name "mysqlpump_*_${Port}_*.sql" -mtime +2 -exec rm -rf {} \; ###mtime +2 -exec rm -rf {} \; 表示删除目录下2天之前被修改过的文件。写为mtine是因为默认输入ls -l(ll)命令输出的内容中就是最后修改时间 (mtime)。rman 进行crosscheck就会把所有的备份片访问一遍,那么如果写-atime(被访问过的文件)就不是实际之前的文件了,从而导致删除失效。因为计划任务是每天执行,所以find查出2天之前的进行rm删除,也就是保留2天的2份。(详情参考“基础命令(网络命令在其他文档中)”文档的find命令)
find /mysql/backup/full/ -name "mysql_exp_grants_${Port}_*.sql" -mtime +2 -exec rm -rf {} \; ###保留2份权限脚本。(3)binlog日志增量脚本(增量:只copy上次备份时没有的二进制日志)
[root@mysql1 ~]# cd script/
[root@mysql1 ~]# vi backup_mysql_binlog_3306.sh
BinLogDir=/mysql/log/3306/binlog ###二进制目录日志(实际路径,定义在my.cnf文件中)
BinIndexFile=/mysql/log/3306/binlog/itpuxdb-binlog.index ###二进制索引输出路径(实际文件,定义在my.cnf文件中)
Date=`date +%Y%m%d`
Port=3306
BinLogBakDir=/mysql/backup/binlog ###备份二进制日志的路径
LogOutFile=/mysql/backup/logs/backup_mysql_binlog_${Port}_${Date}.log ###日志信息
NextLogFile=`tail -n 1 $BinIndexFile`
LogCounter=`wc -l $BinIndexFile |awk '{print $1}'` ###统计索引二进制文件数量
NextNum=0
#这个for循环用于比对$Counter,$NextNum这两个值来确定文件是不是存在或最新的
echo "--------------------------------------------------------------------" >> $LogOutFile
echo binlog-backup---`date +"%Y-%m-%d %H:%M:%S"` Bakup Start... >> $LogOutFile
for binfile in `cat $BinIndexFile`
do
base=`basename $binfile`
#basename用于截取mysql-bin.00000*文件名,去掉./mysql-bin.000005前面的./
NextNum=`expr $NextNum + 1`
if [ $NextNum -eq $LogCounter ]
then
echo $base skip! >> $LogOutFile
else
dest=$BinLogBakDir/$base
if(test -e $dest)
#test -e用于检测目标文件是否存在,存在就写exist!到$LogFile去
then
echo $base exist! >> $LogOutFile
else
cp $BinLogDir/$base $BinLogBakDir
echo $base copying >> $LogOutFile
fi
fi
done
echo binlog-backup---`date +"%Y-%m-%d %H:%M:%S"` Bakup Complete! Next LogFile is: $NextLogFile >> $LogOutFile
find /mysql/backup/logs -name "backup_mysql_binlog_${Port}_*.log" -mtime +30 -exec rm -rf {} \;
find $BinLogBakDir -name "*binlog.**" -mtime +30 -exec rm -rf {} \; ###清理30天前的备份的binlog日志(4)在root下添加全备脚本和binlog增量脚本的自动计划任务
[root@lf script]# chmod 775 /mysql/backup/script/*.sh --确保root用户有执行权限
[root@lf script]# crontab -e
00 02 * * * /mysql/backup/script/mysqlpump_full_3306.sh ###全备:每天晚上2点执行全备脚本。
00 01 * * * /mysql/backup/script/backup_mysql_binlog_3306.sh ###增量:每天晚上1点备份 binlog 日志。(5)Root下测试脚本可用性,并查看日志
全备:
[root@lf script]# /mysql/backup/script/mysqlpump_full_3306.sh [root@lf logs]$ tail -2000f /mysql/backup/logs/mysqlpump_full_3306_20240614_err.log [root@lf logs]$ tail -2000f /mysql/backup/logs/mysqlpump_sys_3306_20240614_err.log
增量:
[root@mysql1 script]# /mysql/backup/script/backup_mysql_binlog_3306.sh [root@mysql1 binlog]# tail -200f /mysql/backup/logs/backup_mysql_binlog_3306_20240614.log

兄弟们,历经3小时的辛勤耕耘,终于完成了这篇文章的撰写。这3小时,换算成分钟是180分钟,再换算成秒则是10800秒,甚至细化到毫秒,便是那沉甸甸的10800000毫秒。每一秒都凝聚着我的心血与汗水,希望大家能够喜欢并给予 点赞、关注和收藏 。
关于mysqldump和mysqlpump这两个数据库备份工具,虽然它们的核心功能相似,但在参数细节上却有着天壤之别。为了探讨和比较这两个工具的异同,我将在下篇文章中专门开辟篇幅,详细解析它们的参数区别,所以我们下篇文章见!!!

















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











