






构筑强者的道德平台是一个复杂的社会工程,道德平台太低,势必挤压弱势群体的生存空间,而过高的道德平台又必然存在两个问题:首先是很少有人能攀援上去,没有可操作性;其次是过多的帮助不利于社会进步,弱势群体得到的输血越多,则自身的造血功能就越差,就越接近死亡。
道德平台理想的高度,是优胜劣汰的法则与人人平等的道德两者之间的平衡。
主流的文化,是优胜劣汰的文化,是不给落后观念生存空间的文化。然而,如果不关爱弱势,道德还有价值吗?
等级是客观存在,如果我们连等级的存在都不敢承认,社会又怎么可能去建立一种更高级的道德文化?如果没有个体的文化价值的量变,又怎么可能会产生民族的文化价值的质变?没有竞争的社会就没有活力,而竞争必然会产生贫富、等级,此乃天道,乃社会进步的必然。
计划经济的弊端在于社会为弱势文化提供了生存、繁衍的温床,解决这个问题主要依靠政治理想的教育。市场经济的弊端在于产生贫富两极分化,以及由此产生的社会矛盾,解决这个问题主要依靠社会利益调节机制。
计划经济制度,政治是人的最高价值,获取社会财富和社会地位的唯一通道是首先得到权力。市场经济制度,经济是人的最高价值,获取社会财富和社会地位的通道多种多样。
获取平等的社会值,就必须付出惰性的代价;获取活力的社会值,就必须付出等级的代价。这是由人的自然属性决定的,这就是天道,就是客观规律。而社会利益调节机制的制定,则有赖于强势群体的道德价值指标和对社会稳定的天然需要。
本文首发微信公众号:码上观世界
维表查询,有时也被称为”点查“,是根据指定的一个或多个key在数据集中检索相关的值。在有索引的存储系统中,快速查询指定的key并不是难题,但是在数据湖中,点查就是一个不得不面对的挑战。下面是一些常见的使用场景:
实时流Join,如两个流基于主键用户id关联
数据驱动的应用,如移动app根据实时用户id检索相关的购买记录
设备或用户维度的数据聚合,如创建基于用户视角,用于分析或广告营销的用户活动视图
数据湖中点查之所以是一个挑战,是因为数据湖为存储半结构化、非结构化数据而生的,为了保证高效数据写入,没办法像传统数据库那样,在数据摄入过程中创建索引,这就导致在查询时候需要遍历历史数据,效率极低。通常的做法是将维表数据存储在高性能Nosql数据库中,比如Cassandra、HBase、Redis或者关系数据库中,然后用实时数据流的每条记录去“点查”数据库,这种方案在大多数场景下都能正常工作,但是在数据湖应用场景下,该方案就显得不现实了,比如一些物联网IOT数据或者电子商务网站实时产生的点击流以高速、大规模的方式入湖,基于批处理聚合代价极大而且很容易出错。
我们以一个案例来看一般传统的做法是什么样的:假设现在有电商网站需要统计过去90天内用户的活动信息,比如登录次数、购买次数、登录时长、购买单价等用于构建用户画像,然后借此对用户进行广告营销等活动,那该如何低延时的查询给定用户的画像数据呢?
一种常见的方案是基于下面的pipeline:原始流式数据写入Kafka,通过两个并列的任务消费Kafka:一个任务读取Kafka中的数据,不做处理,直接写入数据湖,后续分析再使用离线批处理;另一个任务将Kafka的原始数据通过ETL聚合后持久化到缓存系统,比如Cassandra,后续实时消费直接读取Cassandra,架构图如下所示:
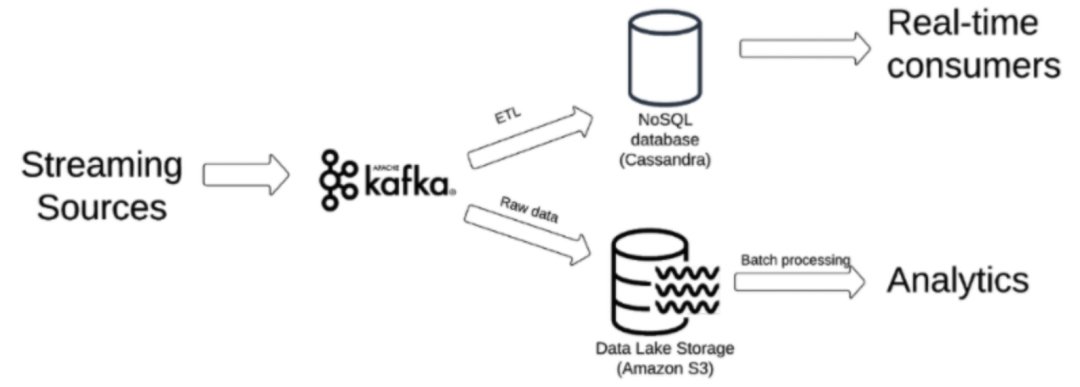
我们来看看这种方案的优点和缺点。
优势:
1 读性能快:NOSQL数据库天然具备优秀的读性能,很适合“点查”场景
2 高可用并容错:Cassandra支持分布式部署,各节点地位相同,数据可分布于每个节点,不存在单点问题
缺点:
1 Cassandra不支持历史数据查询,只保留当前数据。所以上述方案就得持续周期性地通过ETL聚合最新结果数据,这个过程很容易出错,且不能保证数据及时性。
2 运维成本高,首先运维人员需要部署一套分布式的Cassandra集群环境,然后持续监控集群的健康状态、数据的最终一致性、资源利用率以及数据备份等。
有没有办法不引入Cassandra等额外系统就能解决数据湖点查问题呢?其实是有的,还以上面案例来说,多批“过去90天内用户的活动信息”数据构成了随时间连续滚动的不可更新的数据,可以将其视为时序数据,时序数据的特点是随着时间流逝,数据量越来越大,但是基于对象存储可以很适合存储这种数据,因为对使用方来说,对象存储系统具有可靠性高、免运维、存储成本低且支持自动扩展等多重优势。
同原有方案类似,我们用Iceberg数据湖方案来优化聚合任务,如下图所示:
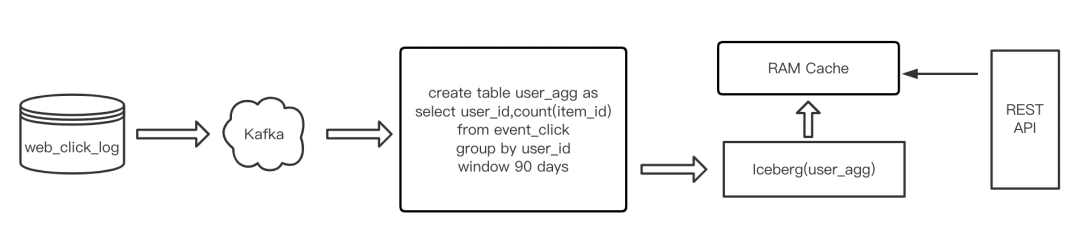
新的聚合任务通过流式Flink Sql作业聚合Kafka数据,利用Flink窗口机制将聚合结果数据输出到数据湖。然后通过后台服务将数据湖数据加载到内存供外部请求读取。
该方案实际上将数据聚合统计和数据查询服务解耦,功能实现有两个要点:
1 Flink 聚合 sql 操作 通过流式作业持续不断地输出结果数据,并物化到对象存储。sql作业必须通过group by key实现,输出带有key的结果记录。存储结果可按照时间分区。
2 数据查询服务加载相关的聚合结果数据到内存,在对象存储之上提供缓存以提供低延时访问,基于底层聚合数据支持进一步上卷操作。
同前面的方案相比,带来的优势是:
1 实时聚合通过flink sql作业,而不是ETL任务,开发门槛更低;
2 聚合作业基于flink时间窗口,比ETL任务更可靠、更及时;
3 窗口聚合结果都被持久化到数据湖,支持历史查询;
4 支持存算分离,聚合结果存储到了数据湖,在此基础上,支持任意再计算;
5. sql作业支持更多的聚合类型,如count distinct、时序聚合等
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









