






一直对树的概念比较模糊,什么红黑树啊,二叉搜索树等很多没有一个完整的知识体系结构,所以今天准备花一天的时间做一个总结,力求搞明白树的全部知识,不同树之间的体系结构,以及一些常见应用,在博客书写过程中,主要参照了以下三篇博文http://www.cnblogs.com/maybe2030/p/4732377.html和http://blog.csdn.net/hero_myself/article/details/52080969和关于二叉树详细性质介绍的博客http://blog.csdn.net/tianlihua306/article/details/44621827以及清华大学严蔚敏的《数据结构》一书,这里注明出处,整理时间是2017.8.5。
树的基本概念
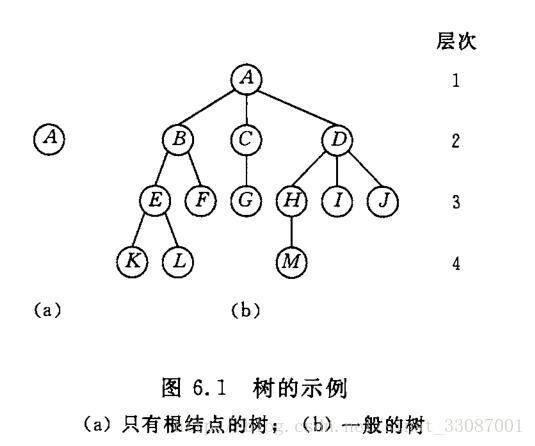
一课树的示例
树的定义
定义方式一
树(tree)是包含n(n>0)个结点的有穷集,其中:
1)每个元素称为结点(node);
2)有一个特定的结点被称为根结点或树根(root);
3)除根结点之外的其余数据元素被分为m(m≥0)个互不相交的集合T1,T2,……Tm-1,其中每一个集合Ti(1<=i<=m)本身也是一棵树,被称作原树的子树。
定义方式二
树也可以这样定义:树是由根结点和若干颗子树构成的。树是由一个集合以及在该集合上定义的一种关系构成的。集合中的元素称为树的结点,所定义的关系称为父子关系。父子关系在树的结点之间建立了一个层次结构。在这种层次结构中有一个结点具有特殊的地位,这个结点称为该树的根结点,或称为树根。
树的相关术语
节点的度:一个节点含有的子树的个数称为该节点的度,A的度为3,C的度为1;
叶节点或终端节点:度为0的节点称为叶节点,K,L,F,G,M,I,J都是叶子节点;
非终端节点或分支节点:度不为0的节点,A,B,C,D,E,H都是分支节点;
树的度:一棵树中,最大的节点的度称为树的度,树的度为3;
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
兄弟节点:具有相同父节点的节点互称为兄弟节点,例如K,L;
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次,该树为4层;
堂兄弟节点:双亲在同一层的节点互为堂兄弟,例如G与E,F,H,I,J互为堂兄弟节点;
节点的祖先:从根到该节点所经分支上的所有节点都是该节点的祖先;
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
有序树:如果将树种各节点看出从左到右是有顺序的,不能互换的,则为有序树。
无序树:如果将树种各节点看出从左到右是没有顺序的,不能互换的,则为有序树。
森林:由m(m>=0)棵互不相交的树的集合称为森林,树可以包含森林,森林里也有树,森林和树可以是相互递归的关系;
二叉树
二叉树的定义
二叉树是数据结构中一种重要的数据结构,也是树表家族最为基础的结构。
二叉树的定义:二叉树的每个结点至多只有二棵子树(不存在度大于2的结点),二叉树的子树有左右之分,次序不能颠倒。可以这么理解:二叉树是节点的度最多为2的有序树。
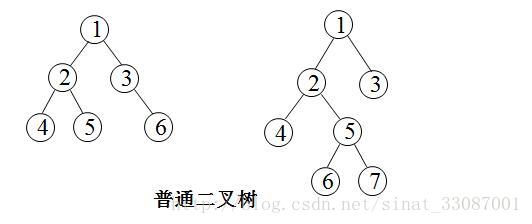
二叉树的基本形态
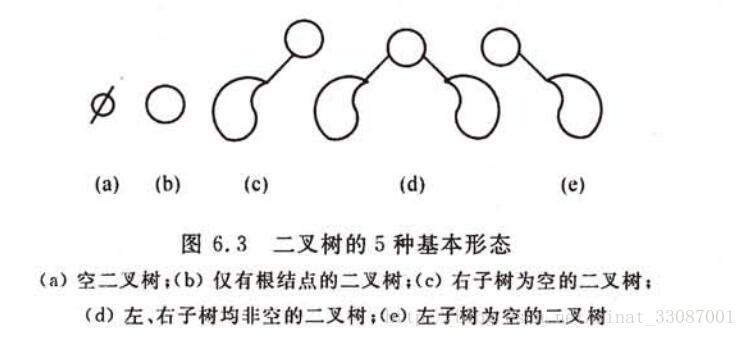
二叉树的基本性质
1,在二叉树的第i层上最多有2^ (i-1) 个节点 。(i>=1), 第二层最多2^(2-1) =2个节点。
2,二叉树中如果深度为k,那么最多有2^k-1个节点。(k>=1),如果深度为3,则该树最多拥有的节点个数为7。该性质可由性质1使用等比数列的求和公式求出:

3,n0=n2+1 n0表示度数为0的节点 n2表示度数为2的节点
推导过程 根据两个公式
1. n=n0+n1+n2 n表示二叉树中的节点总个数,n1表示度数为1的节点个数
2. n-1=2n2+n1 通过观察二叉树我们可知,除了根节点之外,其余的任何节点都有一个入口分支,其他节点都有一个入口分支,那么节点的总分支数等于节点个数减一,度数为2的节点有2个出口分支,度数为一的有1个出口分支,度数为0的节点没有出口分支 所以总的分支个数为 2n2+n1二叉树的基本操作
二叉树不同于栈和队列这种线性数据结构需要经常进出也就是增删,我们用二叉树主要是为了搜索或者查找或者遍历一个序列也就是查,所以我们通常是将一组数用二叉树的方式组织起来,构建成一颗二叉树,然后进行遍历。
二叉树的创建
按照存储结构,二叉树一般有两种构建体系:顺序存储结构构建或者是链式存储结构构建,但我们常用链式。这里也使用链式。
节点代码构建
package tree;
public class TreeNode<T> {
public T val;
public TreeNode<T> leftChild = null;
public TreeNode<T> rightChild = null;
public TreeNode(T val) {
this.val = val;
}
}
二叉树的构建,这里我尝试了两种方式,第一种是自己手动构建,第二种是把一个数组创建为一个完全二叉树。
package tree;
import java.util.LinkedList;
import java.util.List;
public class MyTree {
public int[] array = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
public static List<TreeNode<Integer>> nodeList = null;
public void createBinTree() {
nodeList = new LinkedList<TreeNode<Integer>>();
// 将一个数组的值依次转换为Node节点
for (int i = 0; i < array.length; i++) {
nodeList.add(new TreeNode<Integer>(array[i]));
}
// 对前lastParentIndex-1个父节点按照父节点与孩子节点的数字关系建立二叉树
for (int i = 0; i < array.length / 2 - 1; i++) {
// 左孩子
nodeList.get(i).leftChild = nodeList.get(i * 2 + 1);
// 右孩子
nodeList.get(i).rightChild = nodeList.get(i * 2 + 2);
}
// 最后一个父节点:因为最后一个父节点可能没有右孩子,直接在上述循环里处理会导致数组越界,所以单独拿出来处理
int lastParentIndex = array.length / 2 - 1;
// 左孩子
nodeList.get(lastParentIndex).leftChild = nodeList
.get(lastParentIndex * 2 + 1);
// 右孩子,如果数组的长度为奇数才建立右孩子
if (array.length % 2 == 1) {
nodeList.get(lastParentIndex).rightChild = nodeList
.get(lastParentIndex * 2 + 2);
}
}
public void createBinTree(TreeNode<String> root) {
TreeNode<String> newNodeB = new TreeNode<String>("B");
TreeNode<String> newNodeC = new TreeNode<String>("C");
TreeNode<String> newNodeD = new TreeNode<String>("D");
TreeNode<String> newNodeE = new TreeNode<String>("E");
TreeNode<String> newNodeF = new TreeNode<String>("F");
root.leftChild = newNodeB;
root.rightChild = newNodeC;
root.leftChild.leftChild = newNodeD;
root.leftChild.rightChild = newNodeE;
root.rightChild.rightChild = newNodeF;
}
/**
* 先序遍历
*
* 这三种不同的遍历结构都是一样的,只是先后顺序不一样而已
*
* @param node
* 遍历的节点
*/
public static void preOrderTraverse(TreeNode node) {
if (node == null)
return;
System.out.print(node.val + " ");
preOrderTraverse(node.leftChild);
preOrderTraverse(node.rightChild);
}
/**
* 中序遍历
*
* 这三种不同的遍历结构都是一样的,只是先后顺序不一样而已
*
* @param node
* 遍历的节点
*/
public static void inOrderTraverse(TreeNode node) {
if (node == null)
return;
inOrderTraverse(node.leftChild);
System.out.print(node.val + " ");
inOrderTraverse(node.rightChild);
}
/**
* 后序遍历
*
* 这三种不同的遍历结构都是一样的,只是先后顺序不一样而已
*
* @param node
* 遍历的节点
*/
public static void postOrderTraverse(TreeNode node) {
if (node == null)
return;
postOrderTraverse(node.leftChild);
postOrderTraverse(node.rightChild);
System.out.print(node.val + " ");
}
/**
* 层次遍历
*
* 借助队列来实现
*
* @param node
* 遍历的节点
*/
public static void levelOrderTraverse(TreeNode node) {
if (node == null)
return;
LinkedList<TreeNode> queue = new LinkedList<TreeNode>();
queue.offer(node);
while (!queue.isEmpty()) {
TreeNode current = queue.poll();
System.out.print(current.val);
if (current.leftChild != null) {
queue.offer(current.leftChild);
}
if (current.rightChild != null) {
queue.offer(current.rightChild);
}
}
}
public static void main(String[] args) {
MyTree tree = new MyTree();
tree.createBinTree();
// nodeList中第0个索引处的值即为根节点
TreeNode<Integer> root = nodeList.get(0);
System.out.println("先序遍历:");
preOrderTraverse(root);
System.out.println();
System.out.println("中序遍历:");
inOrderTraverse(root);
System.out.println();
System.out.println("后序遍历:");
postOrderTraverse(root);
System.out.println();
System.out.println("层次遍历:");
levelOrderTraverse(root);
System.out.println();
System.out.println("==========================");
TreeNode<String> rootA = new TreeNode<String>("A");
tree.createBinTree(rootA);
System.out.println("先序遍历:");
preOrderTraverse(rootA);
System.out.println();
System.out.println("中序遍历:");
inOrderTraverse(rootA);
System.out.println();
System.out.println("后序遍历:");
postOrderTraverse(rootA);
System.out.println();
System.out.println("层次遍历:");
levelOrderTraverse(rootA);
System.out.println();
}
}
输出结果为:
先序遍历:
1 2 4 8 9 5 3 6 7
中序遍历:
8 4 9 2 5 1 6 3 7
后序遍历:
8 9 4 5 2 6 7 3 1
层次遍历:
123456789
==========================
先序遍历:
A B D E C F
中序遍历:
D B E A C F
后序遍历:
D E B F C A
层次遍历:
ABCDEF
二叉树的遍历
二叉树的遍历有三种:
先序遍历:遍历顺序规则为【根左右】
中序遍历:遍历顺序规则为【左根右】
后序遍历:遍历顺序规则为【左右根】
层次遍历:从上到下,从左往右遍历
遍历使用递归的方式,详细代码如上所示。
二叉树的深度
使用递归的方法计算,题目转化为求自己左右子树的深度:最后得出最深的那个加上自身就是深度。
public int findDeep(BiTree root)
{
int deep = 0;
if(root != null)
{
int lchilddeep = findDeep(root.left);
int rchilddeep = findDeep(root.right);
deep = lchilddeep > rchilddeep ? lchilddeep + 1 : rchilddeep + 1;
}
return deep;
} 二叉树的镜像
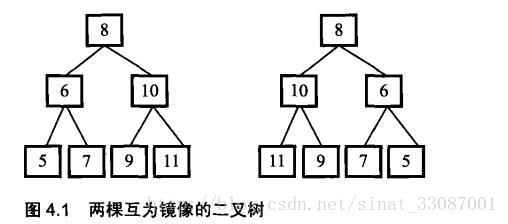
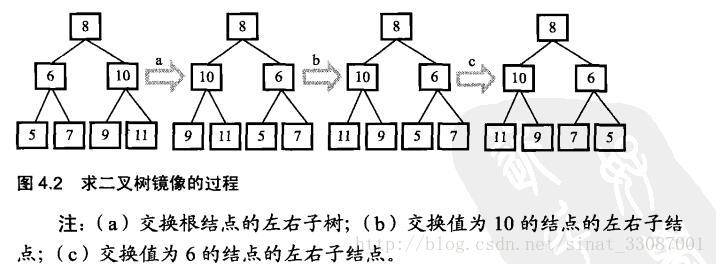
public void Mirror(TreeNode root) {
if (root == null || (root.leftChild == null && root.rightChild == null)) {
return; // 递归结束条件
}
TreeNode temp = root.leftChild;
root.leftChild = root.rightChild;
if (root.leftChild != null) {
Mirror(root.leftChild);
}
if (root.rightChild != null) {
Mirror(root.rightChild);
}
}重建二叉树
主要思路就是由前序遍历发现根节点,然后在中序中找到根节点,中序中根节点的左边是左子树,右边是右子树,然后对每一个子树递归操作即可。
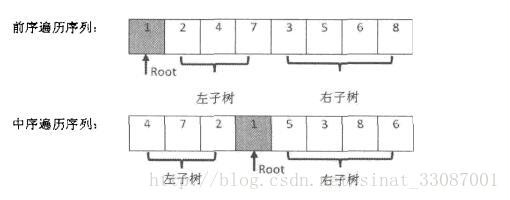
package tree;
/*
* 输入某二叉树的前序遍历和中序遍历的结果,
* 请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
* 例如输入前序遍历序列{1,2,4,7,3,5,6,8}和
* 中序遍历序列{4,7,2,1,5,3,8,6},
* 则重建二叉树并返回。
*
*/
public class ReConstructBinaryTree {
public TreeNode reConstructBinaryTree(int[] pre, int[] in) {
TreeNode root = reConstructBinaryTree(pre, 0, pre.length - 1, in, 0, in.length - 1);
return root;
}
public TreeNode reConstructBinaryTree(int[] pre, int startPre, int endPre, int[] in, int startIn, int endIn) {
if (startPre > endPre || startIn > endIn) {
return null;
}
TreeNode root = new TreeNode(pre[startPre]);
for (int i = startIn; i <= endIn; i++) {
if (pre[startPre] == in[i]) {
root.leftChild = reConstructBinaryTree(pre, startPre + 1,
startPre + i - startIn, in, startIn, i - 1);
root.rightChild = reConstructBinaryTree(pre, startPre + i
- startIn + 1, endPre, in, i + 1, endIn);
}
}
return root;
}
}
二叉树的子结构
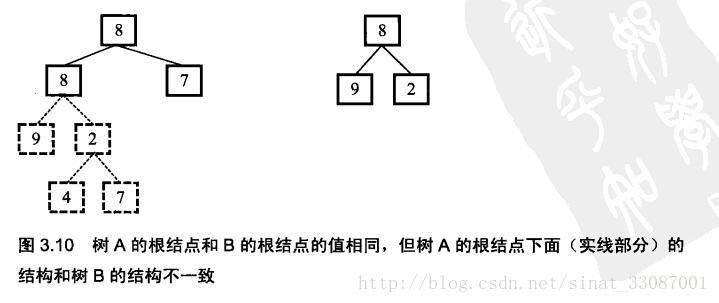
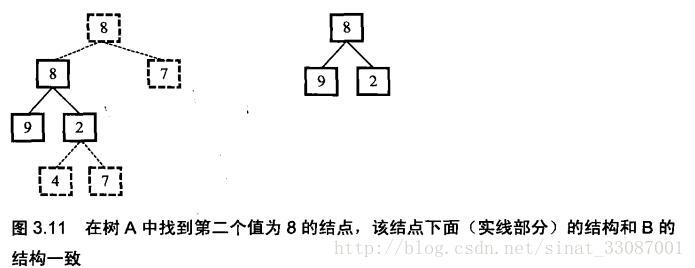
/**
* 二叉树子结构
*
* 双层递归,第一个用来寻找相同的根节点,第二个用于遍历根节点的子节点
*
*
* /*思路:参考剑指offer 1、首先设置标志位result = false,因为一旦匹配成功result就设为true,
* 剩下的代码不会执行,如果匹配不成功,默认返回false 2、递归思想,如果根节点相同则递归调用DoesTree1HaveTree2(),
* 如果根节点不相同,则判断tree1的左子树和tree2是否相同, 再判断右子树和tree2是否相同
* 3、注意null的条件,HasSubTree中,如果两棵树都不为空才进行判断,
* DoesTree1HasTree2中,如果Tree2为空,则说明第二棵树遍历完了,即匹配成功,
* tree1为空有两种情况(1)如果tree1为空&&tree2不为空说明不匹配, (2)如果tree1为空,tree2为空,说明匹配。
*/
public boolean HasSubtree(TreeNode root1, TreeNode root2) {
boolean result = false;
if (root1 != null && root2 != null) {
if (root1.val == root2.val) {
result = DoseTree1havaTree2(root1, root2);
}
if (!result) {
result = HasSubtree(root1.leftChild, root2);
}
if (!result) {
result = HasSubtree(root1.rightChild, root2);
}
}
return result;
}
public boolean DoseTree1havaTree2(TreeNode root1, TreeNode root2) {
if (root2 == null) {
return true;
}
if (root1 == null) {
return false;
}
if (root1.val != root2.val) {
return false;
}
return DoseTree1havaTree2(root1.leftChild, root2.leftChild)
&& DoseTree1havaTree2(root1.rightChild, root2.rightChild);
}对称二叉树
主要思路就是先构造一颗自己的镜像树,然后进行逐节点比较。
public static boolean isSymmetrical(TreeNode pRoot) {
System.out.println("=========================");
levelOrderTraverse(pRoot);
System.out.println("=========================");
levelOrderTraverse(isMirror(pRoot));
return TreeEqual(isMirror(pRoot), pRoot);
}
public static boolean TreeEqual(TreeNode root1, TreeNode root2) {
if (root1 == null && root2 == null) {
return true;
}else if (root1 == null || root2 == null) {
return false;
}
if(root1.val != root2.val){
return false;
}
return TreeEqual(root1.left, root2.left)
&& TreeEqual(root1.right, root2.right);
}
public static TreeNode isMirror(TreeNode root) {
if (root == null ) {
return null; // 递归结束条件
}
TreeNode MirrorTree = new TreeNode(root.val);
MirrorTree.left = isMirror(root.right);
MirrorTree.right = isMirror(root.left );
return MirrorTree;
}归纳:先中后的依据是根,左总在右的前边。
输入整数打印二叉树的路径集合
输入一颗二叉树和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。
// 存放所有路径
ArrayList<ArrayList<Integer>> lists = new ArrayList<ArrayList<Integer>>();
// 用于遍历
ArrayList<Integer> list = new ArrayList<Integer>();
int num = 0;
public ArrayList<ArrayList<Integer>> FindPath(TreeNode root,
int target) {
if (root == null) {
return lists;
}
num += root.val;// num为到该节点为止,各个节点之和为多少
list.add(root.val);// 表示将该节点添加到这条路径中来
// 如果此时路径长度值刚好等于目标值,并且此时所在结点为叶子结点(路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径),路径存入lists
if (num == target && root.left == null && root.right == null) {
ArrayList<Integer> path = new ArrayList<Integer>();
for (int i = 0; i < list.size(); i++) {
path.add(list.get(i));
}
lists.add(path);
}
if (num < target && root.left != null) {
FindPath(root.left, target);
}
if (num < target && root.right != null) {
FindPath(root.right, target);
}
num -= root.val;
list.remove(list.size() - 1);
return lists;
}测试代码
MyTree m =new MyTree();
ArrayList<ArrayList<Integer>> lists = m.FindPath(rootA, 21);
System.out.println(lists.size());
System.out.println("路径:");
for (int i = 0; i < lists.size(); i++) {
for (int j = 0; j< lists.get(i).size(); j++) {
System.out.print(lists.get(i).get(j)+" ");
}
System.out.println();
}测试结果
路径:
8 6 7
8 9 4
完全二叉树与满二叉树
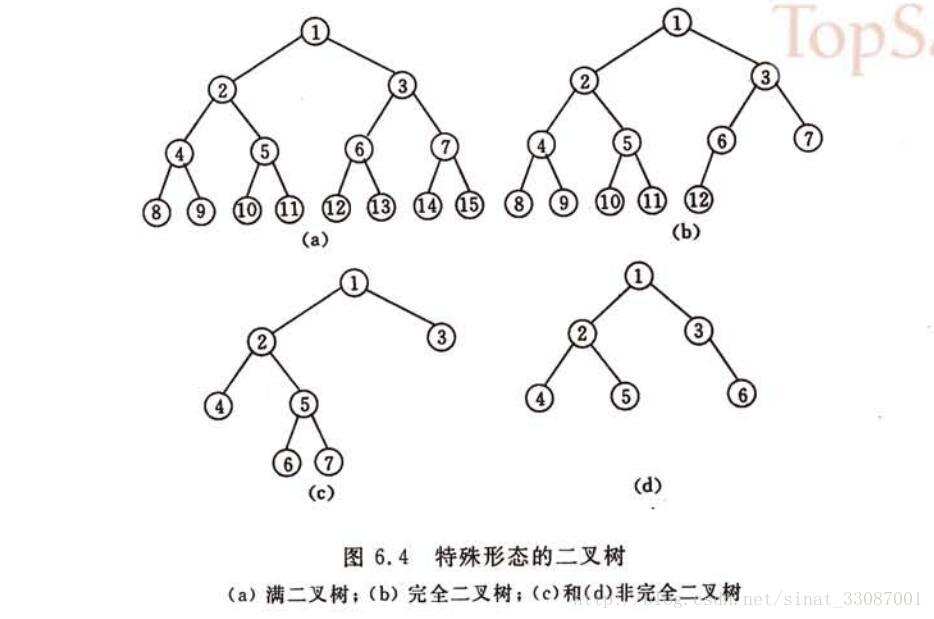
完全二叉树的定义
完全二叉树的定义:深度为k的,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应时,称之为完全二叉树。
完全二叉树的性质
基本性质
1,在完全二叉树的第i层上最多有2^ (i-1) 个节点 。(i>=1), 第二层最多2^(2-1) =2个节点。
2,完全二叉树中如果深度为k,那么最多有2^k-1个节点。(k>=1)
3,n0=n2+1 n0表示度数为0的节点 n2表示度数为2的节点。
附加性质
1,具有n个结点的完全二叉树的深度为|log2(n)|+1,其中|log2(n)|为向下取整,例如具有9个节点,|log2(n)|+1 = 3+1 =4;
证明:由性质2和完全二叉树的定义,最后一层一定不满,总节点数小于等于满二叉树,但总是比上一层满二叉树多。
所以节点总数n为2^ (k-1)-1<n<= 2^ (k)-1
也就是2^ (k-1)<=n< 2^ (k)
于是k-1<=log2(n)<k
所以log2(n)<k<=log2(n)+1
因为k是整数
所以k=|log2(n)|+1 , 其中|log2(n)|为向下取整2,若对含 n 个结点的完全二叉树(深度为|log2(n)|+1)从上到下且从左至右进行 1 至 n 的编号,则对完全二叉树中任意一个编号为 i (1<=i<=n)的结点:
(1) 若 i=1,则该结点是二叉树的根,无双亲, 否则,编号为 [i/2] 的结点为其双亲结点;
(2) 若 2i>n,则该结点无左孩子, 否则,编号为 2i 的结点为其左孩子结点;
(3) 若 2i+1>n,则该结点无右孩子结点, 否则,编号为2i+1 的结点为其右孩子结点。
满二叉树的定义
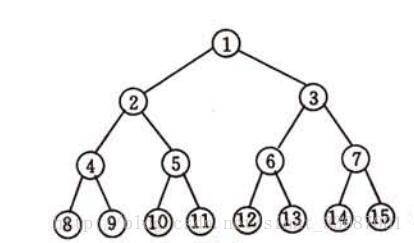
满二叉树:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点。也可以这样理解,除叶子结点外的所有结点均有两个子结点。节点数达到最大值,所有叶子结点必须在同一层上。
满二叉树的性质
基本性质
1,在满二叉树的第i层上一定有2^ (i-1) 个节点 。(i>=1), 第二层最多2^(2-1) =2个节点。
2,满二叉树中如果深度为k,那么一定有2^k-1个节点。(k>=1),总节点数一定是奇数。
3,n0=n2+1 n0表示度数为0的节点 n2表示度数为2的节点
附加性质
1,具有n个结点的满二叉树的深度为log2(n+1),例如有15个节点的二叉树为log2(15+1) = 4层。
证明:由性质2和满二叉树的定义,每一层都满
所以节点总数n为n= 2^ (k)-1
满二叉树的深度为k=log2(n+1)2,若对含 n 个结点的满二叉树(深度为log2(n+1))从上到下且从左至右进行 1 至 n 的编号,则对满二叉树中任意一个编号为 i (1<=i<=n)的结点:
(1) 若 i=1,则该结点是二叉树的根,无双亲, 否则,编号为 [i/2] 的结点为其双亲结点;
(2) 若 2i>n,则该结点无左孩子, 否则,编号为 2i 的结点为其左孩子结点;
(3) 若 2i+1>n,则该结点无右孩子结点, 否则,编号为2i+1 的结点为其右孩子结点。
满二叉树和完全二叉树的关系
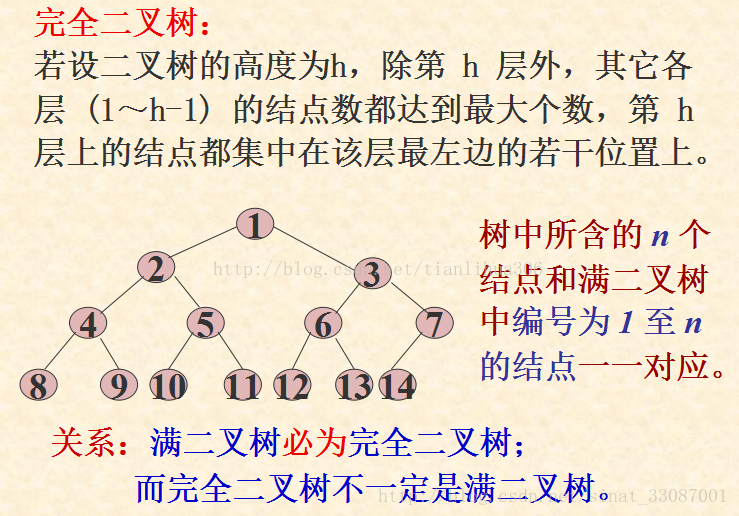
满二叉树是特殊的完全二叉树,是完全二叉树的一种,完全二叉树的性质满二叉树都具备,甚至更加细化
二叉查找树
又称为是二叉排序树(Binary Sort Tree)或二叉搜索树。
二叉查找树的定义
二叉排序树或者是一棵空树,或者是具有下列性质的二叉树:
1) 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2) 若它的右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值;
3) 它的左、右子树也分别为二叉排序树。
4) 没有键值相等的节点。
节点的后继节点:二叉搜索树是按照关键升序排列,对每一个节点来说,比它节点值高的节点是它的中序后继
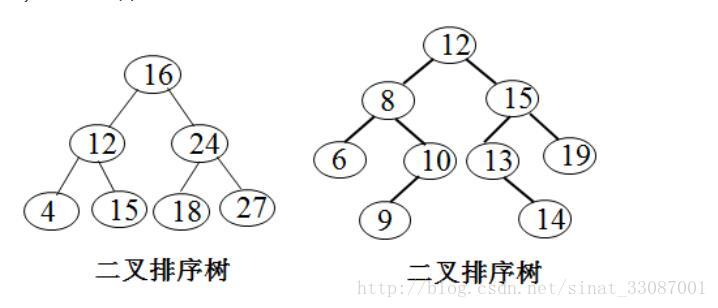
二叉查找树的性质
基本性质就是二叉树那三条,特殊性质如下:
二叉查找树的性质:对二叉查找树进行中序遍历(左根右),即可得到有序的数列。
二叉查找树的时间复杂度
它和二分查找一样,插入和查找的时间复杂度均为O(logn),但是在最坏的情况下仍然会有O(n)的时间复杂度。原因在于插入和删除元素的时候,树没有保持平衡(比如,我们查找上图(b)中的“93”,我们需要进行n次查找操作)。我们追求的是在最坏的情况下仍然有较好的时间复杂度,这就是平衡查找树设计的初衷。
二叉查找树的高度决定了二叉查找树的查找效率。
二叉查找树的插入过程如下:
1) 若当前的二叉查找树为空,则插入的元素为根节点;
2) 若插入的元素值小于根节点值,则将元素插入到左子树中;
3) 若插入的元素值不小于根节点值,则将元素插入到右子树中。
TreeNode代码
package tree;
public class TreeNode {
public int val;
public TreeNode left= null;
public TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
二叉查找树的插入和查找代码
package tree;
public class SearchTree {
public TreeNode insert(TreeNode root, int x) { // 插入操作
TreeNode newNode = new TreeNode(x);
if (root == null) {
root = newNode;
} else if (x < root.val) {
root.left = insert(root.left, x);
} else {
root.right = insert(root.right, x);
}
return root;
}
public TreeNode search(TreeNode root, int x) { // 查找操作
if (root==null)
System.out.println("没有发现");
if (x == root.val) {
System.out.println("发现目标:" + root.val);
return root;
} else if (x < root.val ) {
root = search(root.left, x);
} else {
root = search(root.right, x);
}
return root;
}
public static void main(String[] args) {
SearchTree st = new SearchTree();
TreeNode root = new TreeNode(15);
st.insert(root, 5);
st.insert(root, 3);
st.insert(root, 12);
st.insert(root, 16);
st.insert(root, 20);
MyTree.inOrderTraverse(root);
System.out.println();
System.out.println(st.search(root, 16).val);
}
}
二叉查找树的删除:
分三种情况进行处理
1,p为叶子节点,直接删除该节点,再修改其父节点的指针(注意分是根节点和不是根节点)让其指向null,如图a;
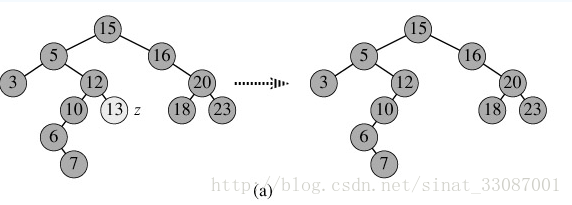
2) p为单支节点(即只有左子树或右子树)。让p的子树与p的父亲节点相连,删除p即可(注意分是根节点和不是根节点),也就是p父节点的引用指向自己的子节点如图b;
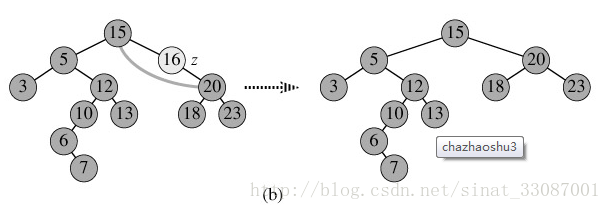
3) p的左子树和右子树均不空。找到p的后继y,因为y一定没有左子树,所以可以删除y,并让y的父亲节点成为y的右子树的父亲节点,并用y的值代替p的值;或者方法二是找到p的前驱x,x一定没有右子树,所以可以删除x,并让x的父亲节点成为y的左子树的父亲节点。如图c。

判断一个数组是不是二叉查找树的后序遍历
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则输出Yes,否则输出No。假设输入的数组的任意两个数字都互不相同。
思路:


package tree;
public class VerifySquenceOfBST {
public boolean IntVerifySquenceOfBST(int[] sequence) {
if (sequence == null || sequence.length <= 0) {
return false;
}
return IntVerifySquenceOfBST(sequence, 0, sequence.length - 1);
}
public boolean IntVerifySquenceOfBST(int[] sequence, int start, int end) {
if (start >= end) { //递归结束条件,只要一直判断下来没有返回false则为true
return true;
}
int root = sequence[end];
int i = start;
for (; i < end; i++) { //找到左子树
if (sequence[i] > root)
break;
}
int j = i; //找到右子树,如果右子树含有大于根的说明不满足二叉查找树的定义,所以返回false
for (; j < end; j++) {
if (sequence[j] < root)
return false;
}
return IntVerifySquenceOfBST(sequence, start, i - 1)
&& IntVerifySquenceOfBST(sequence, i, end - 1);
//递归调用左子树和右子树,各自都有了新的长度
}
public static void main(String[] args) {
VerifySquenceOfBST v = new VerifySquenceOfBST();
int[] array = { 5, 7, 6, 9, 11, 18 };
System.out.println(v.IntVerifySquenceOfBST(array));
int[] array1 = { 7, 4, 6, 5 };
System.out.println(v.IntVerifySquenceOfBST(array1));
}
}
测试结果
true
false平衡二叉树
定义
平衡二叉树(Self-balancing binary search tree)又被称为AVL树(有别于AVL算法),且具有以下性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
最小二叉平衡树的节点的公式如下 F(n)=F(n-1)+F(n-2)+1 这个类似于一个递归的数列,可以参考Fibonacci(斐波那契)数列,1是根节点,F(n-1)是左子树的节点数量,F(n-2)是右子树的节点数量。
判断二叉树是否平衡
深度重复计算的方式
/**
* 平衡二叉树
*
* 判断某一二叉树是否平衡
*
*
*
*/
public static boolean IsBalanced_Solution(TreeNode root) {
if (root == null)
return true; //递归结束条件,如果每个节点的左右节点都满足,则为真
int leftdeep = depth(root.left);
int rightdeep = depth(root.right);
int diff = leftdeep - rightdeep;
if (diff > 1 || diff < -1) {
return false;
}
return IsBalanced_Solution(root.left)
&& IsBalanced_Solution(root.right);
}
public static int depth(TreeNode root) { //某一节点的深度
int deep = 0;
if (root != null) {
int leftdeep = depth(root.left);
int rightdeep = depth(root.right);
deep = leftdeep > rightdeep ? leftdeep + 1 : rightdeep + 1;
}
return deep;
}
改进算法,每判断一个节点计算一次深度
/**
* 平衡二叉树
*
* 判断某一二叉树是否平衡的改进算法
*
*
*
*/
public boolean IsBalanced_Solution2(TreeNode root) {
int[] depth = new int[1];
return isBalance(root, depth);
}
public boolean isBalance(TreeNode root, int[] depth) {
if (root == null) {
depth[0] = 0;
return true;
}
boolean left = isBalance(root.left, depth); // 左子树是否平衡
int leftdepth = depth[0]; // 这里为什么是数组,因为要想改变depth的值,必须是引用传递才可以
boolean right = isBalance(root.right, depth);
int rightdepth = depth[0];
depth[0] = Math.max(leftdepth + 1, rightdepth + 1); // 取二者最大为深度
return left && right && Math.abs(leftdepth - rightdepth) <= 1; // Math.abs(x)返回x的绝对值
}平衡二叉查找树
定义
作用
AVL算法实现
红黑树实现
多叉树
B树
B树也是一种用于查找的平衡树,但是它不是二叉树。
定义
B树(B-tree)是一种树状数据结构,能够用来存储排序后的数据。这种数据结构能够让查找数据、循序存取、插入数据及删除的动作,都在对数时间内完成。B树,概括来说是一个一般化的二叉查找树,可以拥有多于2个子节点。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。这种数据结构常被应用在数据库和文件系统的实作上。
性质
B树作为一种多路搜索树(并不是二叉的):
1) 定义任意非叶子结点最多只有M个儿子;且M>2; (确定子节点最多的个数)
2) 根结点的儿子数为[2, M];
3) 除根结点以外的非叶子结点的儿子数为[M/2, M];
4) 每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5) 非叶子结点的关键字个数=指向儿子的指针个数-1;
6) 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7) 非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8) 所有叶子结点位于同一层;
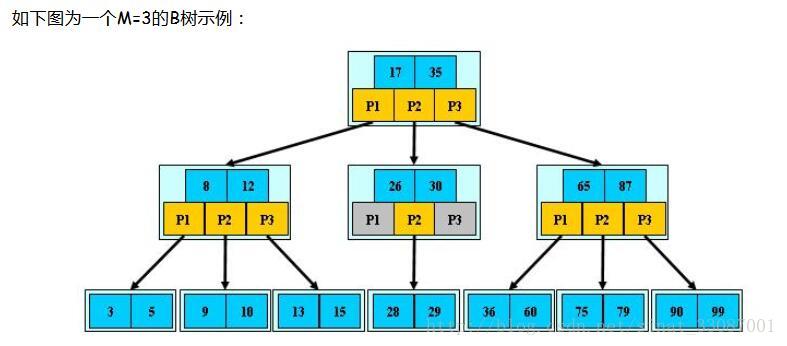
B+树
定义
B+树是B树的变体,也是一种多路搜索树:
其定义基本与B-树相同,除了:
- 非叶子结点的子树指针与关键字个数相同;
- 非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
- 为所有叶子结点增加一个链指针;
- 所有关键字都在叶子结点出现;
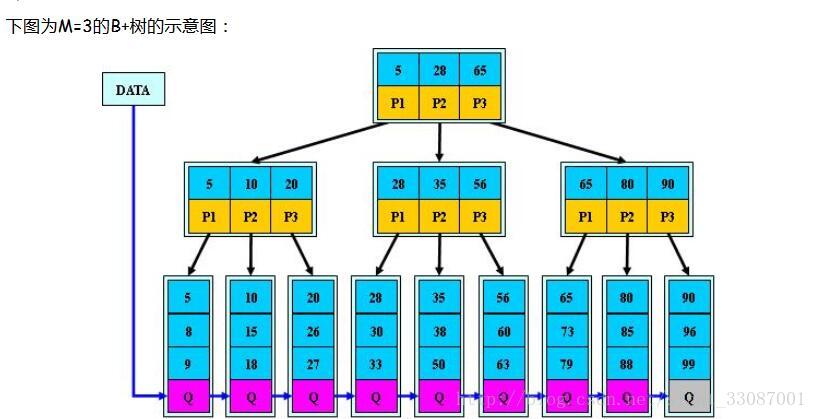
性质
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
- 更适合文件索引系统。
通常在B+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。
对B+树可以进行两种查找运算:
1.从最小关键字起顺序查找;
2.从根结点开始,进行随机查找
B+和B和B-对比
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于
走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键
字范围的子结点; 所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率
从1/2提高到2/3;














 4233
4233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









