







全文检索用到了一种叫做反向索引的技术。
首先我们来看为什么顺序扫描的速度慢:这是由于我们想要搜索的信息和非结构化数据中所存储的信息不一致造成的。
非结构化数据中所存储的信息是每个文件包含哪些字符串,也即已知文件,欲求字符串相对容易,是从文件到字符串的映射。而我们想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,是从字符串到文件的映射。两者恰恰相反。于是如果索引总能够保存从字符串到文件的映射,则会大大提高搜索速度。
由于从字符串到文件的映射是文件到字符串映射的反向过程,所以保存这种信息的索引称为反向索引 ,全文搜索相对于顺序扫描的优势在于:一次索引,多次使用。
下面我们再来看一下创建索引的过程,用两个文件为例:
文件一:Students should be allowed to go out with their friends, but not allowed to drink beer.
文件二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
首先将原文档传给分次组件(Tokenizer),进行分词:1. 将文档分成一个一个单独的单词;2. 去除标点符号;3. 去除停词(Stop word,一些无意义的词语,如the,a等等,对于每一种语言的分词组件,都有一个停词集合) 。经过分词(Tokenizer) 后得到的结果称为词元(Token) ,在我们的例子中,便得到以下词元(Token): “Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“friend”,“Jerry”,“went”,“school","see","his","students","found","them","drunk","allowed"
然后将得到的词元(Token)传给语言处理组件(Linguistic Processor),语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些同语言相关的处理,对于英语,语言处理组件(Linguistic Processor) 一般做以下几点:1. 变为小写(Lowercase) ;2. 将单词缩减为词根形式,如“cars ”到“car ”等 ;3. 将单词转变为词根形式,如“drove ”到“drive ”等。语言处理组件(linguistic processor)的结果称为词(Term) ,在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
最后将得到的词(Term)传给索引组件(Indexer),索引 组件(Indexer)主要做以下几件事情:
1. 利用得到的词(Term)创建一个字典。

2. 对字典按字母顺序进行排序。

3. 合并相同的词(Term) 成为文档倒排(Posting List) 链表:
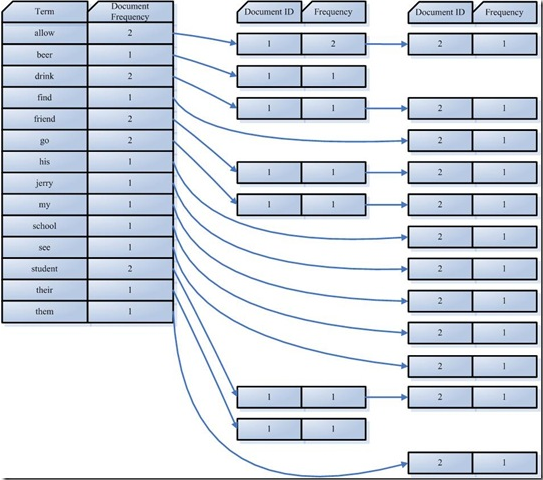
在此表中,有几个定义:
- Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)。
- Frequency 即词频率,表示此文件中包含了几个此词(Term)。
所以对词“allow”来讲,总共有两篇文档包含此词,从而词后面的文档链表总共有两项,第一项表示包含“allow”的第一篇文档,即1号文档,此文档中,“allow”出现了2次,第二项表示包含“allow”的第二个文档,是2号文档,此文中,“allow”出现了1次。
到此为止,索引已经创建好了,我们可以通过它很快的找到我们想要的文档。
我在上一篇博客中已经说过,lucene的使用过程包括两个步骤,第一步创建索引,第二步搜索索引,现在索引已经创建完毕,接下来就是要处理搜索索引的事情了。就像创建索引一般,对索引进行搜索也不是一蹴而就,它要分好几个不同的步骤进行搜索。
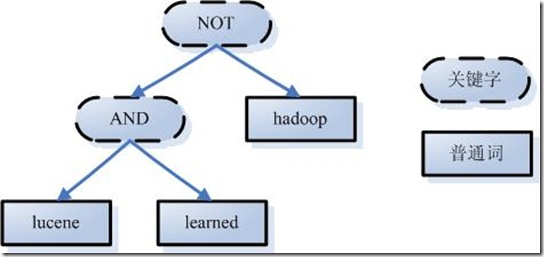
第一步:用户输入查询语句。首先必须确定,查询语句是有语法的,语法规则根据全文检索系统的不同实现而有所不同,最基本的有比如:AND, OR, NOT等。举个例子,用户输入语句:lucene AND learned NOT hadoop,说明用户想找一个包含lucene和learned然而不包括hadoop的文档。
第二步:对查询语句进行词法分析,语法分析,及语言处理:1. 词法分析主要用来识别单词和关键字。如上述例子中,经过词法分析,得到单词有lucene,learned,hadoop, 关键字有AND, NOT;2、语法分析主要是根据查询语句的语法规则来形成一棵语法树。如果发现查询语句不满足语法规则,则会报错。如lucene NOT AND learned,则会出错。如上述例子,lucene AND learned NOT hadoop形成的语法树如下:
第四步:搜索索引,得到符合语法树的文档。
1. 索引过程:1) 有一系列被索引文件;2) 被索引文件经过语法分析和语言处理形成一系列词(Term) ;3) 经过索引创建形成词典和反向索引表;4) 通过索引存储将索引写入硬盘。
2. 搜索过程:a) 用户输入查询语句;b) 对查询语句经过语法分析和语言分析得到一系列词;c) 通过语法分析得到一个查询树;d) 通过索引存储将索引读入到内存;e) 利用查询树搜索索引,从而得到每个词(Term) 的文档链表,对文档链表进行交,差,并得到结果文档;f) 将搜索到的结果文档对查询的相关性进行排序;g) 返回查询结果给用户。














 6155
6155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









