






一.介绍:
The Jaccard Similarity algorithm,杰卡德相似性算法,主要用来计算样本集合之间的相似度。
给定两个集合A,B,jaccard 系数定义为A与B交集的大小与并集大小的比值。
公式描述为:
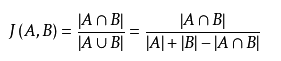
杰卡德值越大,说明集合之间相似度越大。
二.neo4j算法:
CALL algo.similarity.jaccard.stream(userData:List<Map>)
注意在求相似度时,两个样本应放在集合内。
三.实例:
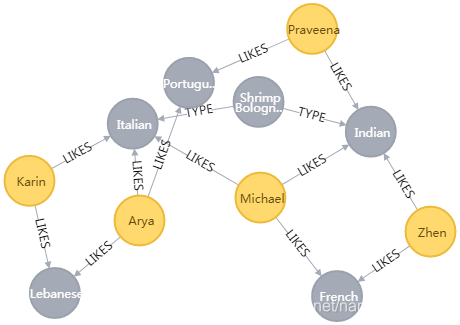
MERGE (french:Cuisine {name:'French'})
MERGE (italian:Cuisine {name:'Italian'})
MERGE (indian:Cuisine {name:'Indian'})
MERGE (lebanese:Cuisine {name:'Lebanese'})
MERGE (portuguese:Cuisine {name:'Portuguese'})
MERGE (zhen:Person {name: "Zhen"})
MERGE (praveena:Person {name: "Praveena"})
MERGE (michael:Person {name: "Michael"})
MERGE (arya:Person {name: "Arya"})
MERGE (karin:Person {name: "Karin"})
MERGE (shrimp:Recipe {title: "Shrimp Bolognese"})
MERGE (saltimbocca:Recipe {title: "Saltimbocca alla roman"})
MERGE (periperi:Recipe {title: "Peri Peri Naan"})
MERGE (praveena)-[:LIKES]->(indian)
MERGE (praveena)-[:LIKES]->(portuguese)
MERGE (zhen)-[:LIKES]->(french)
MERGE (zhen)-[:LIKES]->(indian)
MERGE (michael)-[:LIKES]->(french)
MERGE (michael)-[:LIKES]->(italian)
MERGE (michael)-[:LIKES]->(indian)
MERGE (arya)-[:LIKES]->(lebanese)
MERGE (arya)-[:LIKES]->(italian)
MERGE (arya)-[:LIKES]->(portuguese)
MERGE (karin)-[:LIKES]->(lebanese)
MERGE (karin)-[:LIKES]->(italian)
MERGE (shrimp)-[:TYPE]->(italian)
MERGE (shrimp)-[:TYPE]->(indian)
MERGE (saltimbocca)-[:TYPE]->(italian)
MERGE (saltimbocca)-[:TYPE]->(french)
MERGE (periperi)-[:TYPE]->(portuguese)
MERGE (periperi)-[:TYPE]->(indian)
求单个节点之间的相似度:
MATCH (p1:Person {name: 'Karin'})-[:LIKES]->(cuisine1)
WITH p1, collect(id(cuisine1)) AS p1Cuisine
MATCH (p2:Person {name: "Arya"})-[:LIKES]->(cuisine2)
WITH p1, p1Cuisine, p2, collect(id(cuisine2)) AS p2Cuisine
RETURN p1.name AS from,
p2.name AS to,
algo.similarity.jaccard(p1Cuisine, p2Cuisine) AS similarity

求所有节点之间的相似度:
MATCH (p:Person)-[:LIKES]->(cuisine)
WITH {item:id(p), categories: collect(id(cuisine))} as userData
WITH collect(userData) as data
CALL algo.similarity.jaccard.stream(data)
YIELD item1, item2, count1, count2, intersection, similarity
RETURN algo.getNodeById(item1).name AS from, algo.getNodeById(item2).name AS to, intersection,
similarity
ORDER BY similarity DESC
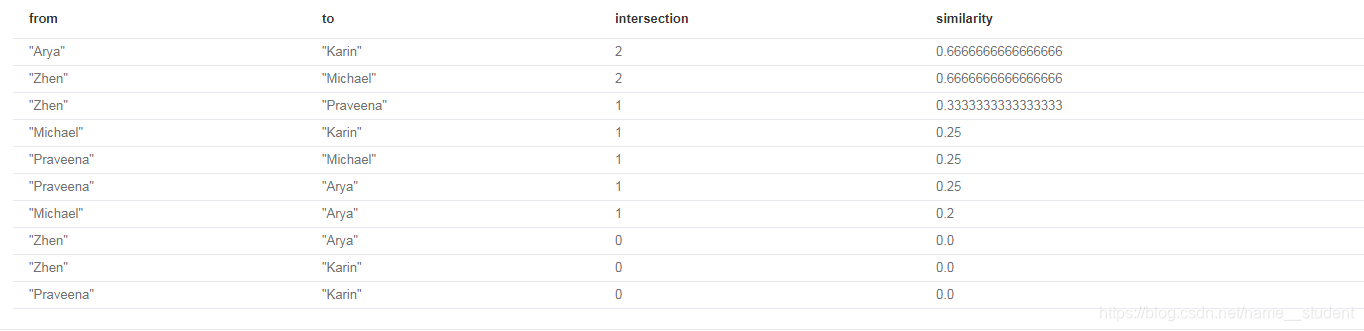
其中intersection为两个集合之间节点重叠个数。














 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









