







 本文介绍了如何结合Neo4j图数据库和百度云的NLP服务,进行文本的词法分析和句法分析,创建语义丰富的知识图谱。通过将NLP分析结果保存到Neo4j,可以实现内容推理、文本分类等应用。
本文介绍了如何结合Neo4j图数据库和百度云的NLP服务,进行文本的词法分析和句法分析,创建语义丰富的知识图谱。通过将NLP分析结果保存到Neo4j,可以实现内容推理、文本分类等应用。
我们现在处于“大数据时代”,而在浩繁的“大数据”中,绝大多数是文本形式的非结构化数据。图其实可以非常灵活和有效地表示和处理文本内容中的词语、概念、依存关系,并用作知识推理、情感分析、智能问答等丰富的应用中。
本文以百度云的自然语言处理API服务为例,介绍怎样将文本分析的结果保存到Neo4j图数据库中。
1、准备
Neo4j图数据库3.5.*。
APOC扩展包。关于如何安装APOC,请参见这里。我们要用到APOC中访问RESTful API的过程。关于APOC的介绍,请参见这篇文章。
一个百度云账号,并可以访问百度智能云。
2、创建百度云NLP应用
在百度云控制台中选择并创建一个“自然语言应用”:
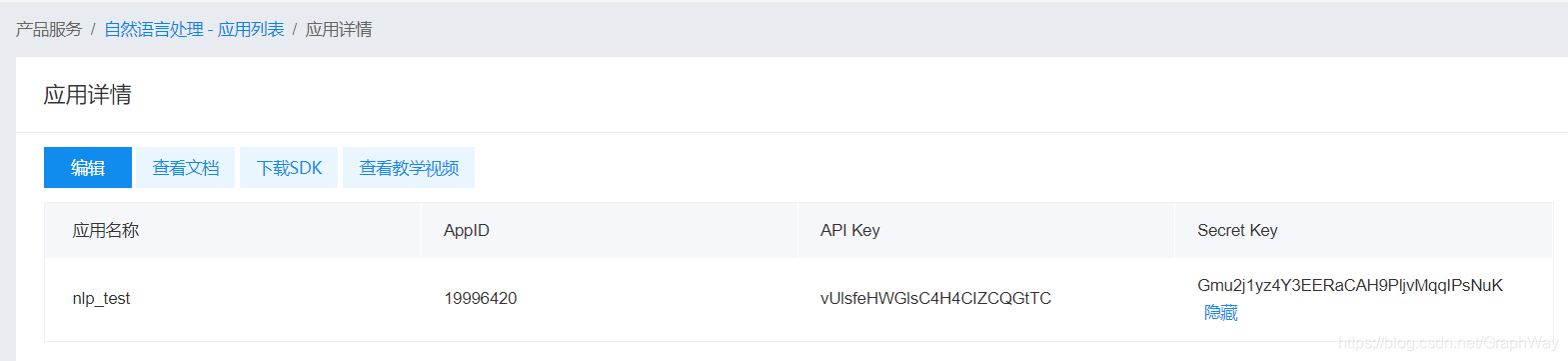
对于有限的NLP API调用是免费的。把上面页面中的AppID和 API Key的内容保存下来,我们后面要用到。
3、从Neo4j中访问百度NLP API
3.1 概述
Neo4j的APOC扩展包提供丰富的过程和函数。要调用任何API,可以使用下面的过程:
- apoc.load.json:最简单的URL访问,请求不带参数。URL可以是远程的,也可以是文件。
- apoc.load.jsonParams:带参数/payload的API调用过程,还可以指定JSON Path对结果进行过滤。这是我们下面要用的过程。
- apoc.load.jsonArray:与apoc.load.json类似,内容中可以包含JSON Array。
- apoc.import.json:导入由apoc.export.json导出的JSON数据文件。
关于相关过程的详细文档,请参见Neo4j文档。
3.2 获取Access Token
首先需要向授权服务地址https://aip.baidubce.com/oauth/2.0/token发送请求(推荐使用POST),并在URL中带上以下参数:
- grant_type: 必须参数,固定为
client_credentials
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









