






Overpass ql教程
前言
网络迷踪(人肉图片搜索)是前几年互联网上很火的一种侦探游戏。一般由油管主、b站up或者抖音博主发起。网友在评论区留言提供谜题和赏金,博主解谜、制作视频并领取粉丝提供的赏金。
网友提供的谜题一般就是其随手拍摄或是在各种街景地图软件上面找到的地点截图,此外其亦可能会提供时间、方向等信息,从而降低题目难度,帮助解题。网络迷踪不仅是一种互联网游戏,在很多方面会有更加深层的意义。例如通过地图延时摄影推理老照片的拍摄位置,从而帮助人们缅怀过去。
解密的过程观赏性极强,解迷人会利用各类地理知识、地图学知识、植物学和气象学知识,或者各类开源情报手段拓展图片信息,最终找到图片拍摄位置的具体坐标。这个过程最令人着迷的点在于,所有知识都是可以从互联网上轻易获取的。在拥有了对话大模型之后,这些知识壁垒就更少了,任何一个普通人都可以像神探那样,通过诈骗分子随手一张照片对来他们进行定位。
前段时间我沉迷这类节目,基本上把全网能找到的视频刷了一遍。随着我的深入了解,逐渐发现那些技术最强大的博主都擅长将谷歌地球和OSM数据结合使用,从而极大地减少地图搜索的重复操作,降低解密的整体难度。为了配合OSM数据库,用于检索其信息的overpass api诞生了,并出现了一种简单易学的、基于C语法的overpass ql语言,可以轻易地让你对以B为单位的地图数据进行超快速检索,而且完全免费!
总体介绍
OpenStreetMap (OSM)
是一个免费且开放的地理数据库,已创建并由自愿贡献者的全球社区维护。不断增长的社区有超过 10M 注册成员,这些成员共同有助于创建数据库中现有的 9B 元素(OpenStreetMap Wiki,2022)。元素要么是节点、方式,要么是关系。节点用地理空间坐标进行注释。路由多个节点组成,代表道路、建筑轮廓或区域边界。关系描述了元素之间的关系,例如形成城市或主要高速公路。元素可以用分配语义含义和元信息的键值对进行标记。OSM 数据库广泛用于地理数据分析、科学研究、路线规划应用、人道主义援助项目或增强现实游戏。它还作为 Facebook、Amazon 或 Apple (OpenStreetMap Foundation, 2019) 等公司的地理空间服务数据源。
OSM中的数据分为节点、路径和关系三种;路径由多个节点组成,可以作为polygon、一块区域等;关系是一个三元组,包含一个
Overpass Query Language (OverpassQL)
是一种用 C 样式语法编写的“过程、命令式编程语言”(OpenStreetMap Wiki、2023)。它用于查询用于地理数据和特征的 OpenStreetMap 数据库。OverpassQL 允许详细的查询,这些查询能够根据特定的标准提取元素,例如定义区域内的某些类型的建筑物、街道或自然特征。用户可以指定他们感兴趣的元素类型,并通过它们相关的键值对对其进行过滤。
使用overpass turbo,可以将查询结果实时显示在屏幕右侧地图上,也可以以geojson格式导出。你可以很轻松地在本地部署overpassturbo,但若仅用于学习,也可以直接使用网络上部署好的overpassturbo(需科学上网)https://overpass-turbo.eu/index.html#
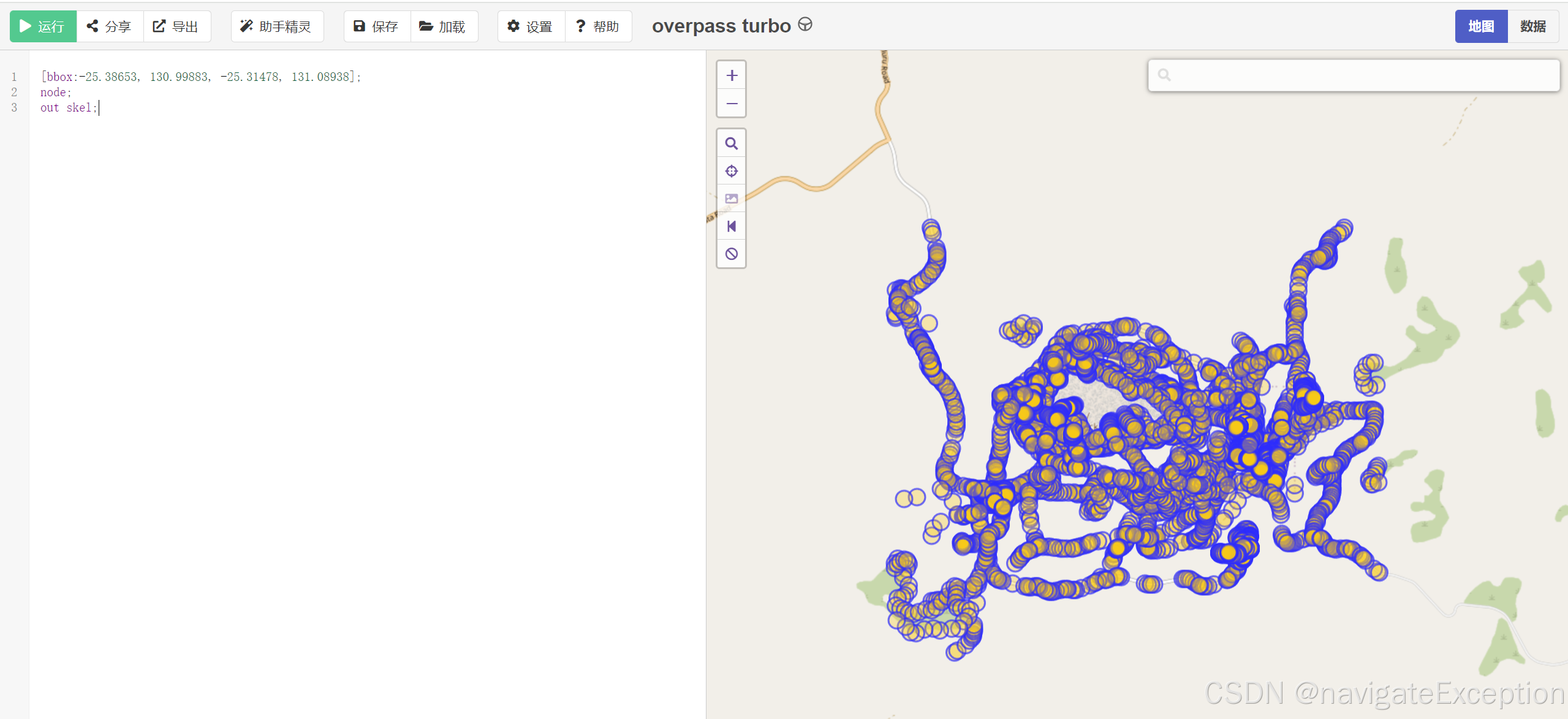
OverPassQL 语法详解
OverpassQL(以下简称为oql)分为两部分:定义查询的语句;处理结果的语句
//查询第一个节点
node(1);
//输出
out;
bbox边界框:查询范围内的节点
//定义边界框
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
node;
//or:直接将边界框作为参数
//node(-25.38653, 130.99883, -25.31478, 131.08938);
//or:将边界框变量作为参数
//node({{bbox}});
out skel;
边界框是一个矩形框,由四个值定义。前两个值定义边界框的西南角。第二对值定义边界框的东北角。在oql中定义边界框有三种方法:
- 定义一个适用于整个查询的边界框。这是使用名为“
bbox”的查询设置实现的。查询设置出现在查询的开头,并用方括号定义:[]。 - 将边界框的坐标作为语句的参数
- 将当前边界框作为变量传入以作为语句的参数。很典型的vue语法,自然也仅适用于overpass turbo,无法通过api使用。当你需要交互式调整代码时很好用
定义输出细节
out语句后面加一些语句可以定义查询的节点的细节等级。
-
ids- 仅输出节点id -
tags- 输出tag和id -
skel- 输出地理信息和id -
body- 输出tag,id,地理信息 -
meta- 输出tag的历史记录,id,地理信息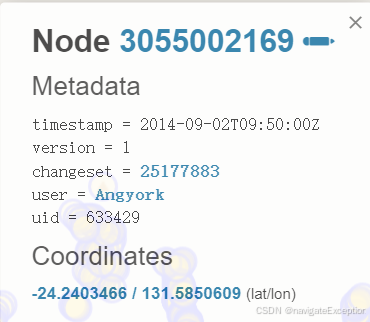
由于前两个选项不输出任何坐标,因此 IDE 只会显示一些 XML 输出。它无法根据 ID 和标签列表生成地图。
z
上图展示了某个搜索出来的meta信息。其实大部分node都不包含tag信息,因为大部分的节点都不是兴趣点,而是街道、水系等polygon的节点。
过滤拥有某标签的节点
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
node["name"];
//use this form if you need to query for features in several
//different bounding boxes
//node(-25.38653, 130.99883, -25.31478, 131.08938)["name"];
//TRYME #2 try finding just nodes that have a Pitjantjatjara name
//node["name:pjt"];
使用node[“标签名”],可以查询经纬度范围内所有拥有此标签的节点;
同时,OSM数据不允许标签拥有多个值,而是使用子标签的形式。使用node[“标签名:二级标签”],可以查询拥有对应二级标签的节点。例如,如果我们想要找到以 Pitjantjatjara(居住在乌鲁鲁周围的人们所说的方言)命名的节点,那么我们将过滤名为name:pjt的标签。
-
https://wiki.openstreetmap.org/wiki/Multilingual_names
过滤节点标签值
//限制经纬度范围
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
//EXISTENCE CHECKS
//限制包含标签name
node["name"];
//限制不包含标签name
//node[!"name"];
//BY VALUE
//使用等于号来限制标签内容
node["name:pjt"="Uluṟu"];
//REGULAR EXPRESSIONS, matching values
//限制以Viewing作为标签内容结束
node["name"~"Viewing$"];
//限制以Viewing作为标签内容开始
node["name"~"^Viewing"];
//限制标签name包含Viewing
node["name"~"Viewing"];
//忽略大小写
//node["name"~"Viewing", i];
//REGULAR EXPRESSIONS, matching tag names
//基于正则表达式的匹配
node[~"^name(:.*)?$"~"."];
out body;
应用多个过滤器对节点进行过滤
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
node["natural"="cave_entrance"]["name:pjt"~"^Kulpi"];
//含有name的tag但是不含name:pjt的tag的节点
//node["name"][!"name:pjt"];
out meta;
一次导出多个查询结果
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
(
node["tourism"];
node["natural"="cave_entrance"];
);
out meta;
- 通过建立更大的集合,我们可以进行涉及集合运算的更复杂的查询
计算结果之间的差异
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
(
node["tourism"];
-
node["natural"="cave_entrance"];
);
out body;
计算两个查询之间的差异可以采用( statement1; - statement2; )的方式。
JSON输出
[out:json]
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
node["name"];
out body;
注意设定输出格式的语句后面没有分号。一开始的设定部分被视为同一语句。在overpass turbo中,可以从地图选项卡切换为数据选项卡。数据的默认组织形式为xml格式,可以用这种方式换成我们熟悉的json。
CSV输出
//通过标签定义csv的字段,分隔方式
[out:csv(::id, ::lat, ::lon, name; true; ",")];
//加上type
//[out:csv(::id, ::lat, ::lon, ::type, name; true; ",")];
//使用|作为分隔符
//[out:csv(::id, ::lat, ::lon, ::type, name; false; "|")];
//正常查询节点
node(-25.38653, 130.99883, -25.31478, 131.08938)["natural"="cave_entrance"];
//include tags in output, so we can have them in our CSV output
out body;
为了让 API 知道如何构建 CSV 输出,必须提供要包含哪些字段(列)的规范。这些字段可以是:
- 一个特殊的字段名称,由 API 预定义,例如
::id - 或标签名称
特殊字段名称包括:
::id- 对象的数据库 ID::type- 它的类型,例如节点、方式或关系::lat- 它的纬度::lon- 其经度
语法格式为:
[out:csv (columns; header; col-separator)]
columns是一个以逗号分隔的名称列表header要么是true,要么是falsecol-separator是以字符串形式提供的所需分隔符。
如果想在 CSV 输出中包含标签,则out查询的关键字必须生成标签。因此请使用out body或out meta。
还要注意,当您包括纬度(::lat)和经度(::lon)列时,对于节点,您将获得它们的原始坐标。但路线和关系是更复杂的空间对象。它们不是由单个点定义的。您可以使用out关键字自动为这些类型的特征生成一个代表位置(“质心”)。指定out body center即可。这将计算结果中任何方式或关系的质心。
实践中,最好先用正常输出查询出想要的结果,再定义csv格式来进行输出,否则可能会产生令人感到困惑的报错。
集合
默认集._
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
//将节点查询结果发送到默认集合
node["name"]->._;
//从默认集中再输出到界面
._ out skel;
上述实验中,进行的查询都隐式地把结果暂存到了结果集._中。
集合操作
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
//将结果存在一个暂定集合named_nodes中
node["name"]->.named_nodes;
//导出暂定集合中的数据扔到一个新的集合caves里面
node.named_nodes["natural"="cave_entrance"]->.caves;
//将caves作为输出集进行输出
.caves out body;
可以任意命名集合,提取集合数据,将任意集合数据进行导出。集合名称可以包含字母、数字和下划线字符。但名称不能以数字开头。
node.named_nodes意味着该语句将使用该集合而不是 OSM 数据库。还可以通过重复使用 out引用不同集合的关键字来输出不同集合的结果。
⭐Around:半径范围内搜索
node(around:800.00,-25.344857,131.0325171)["natural"="cave_entrance"];
node(around:100.00,-25.340861, 131.0252552,-25.3400707, 131.0275297)["natural"="cave_entrance"];
out body;
使用around来过滤圆形区域内的节点,通常情况下只有标签过滤器会使用方括号。
两种使用方法:
-
简单的点附近的搜索:参数为半径,纬度,经度
-
查询线附近的点:指定多个纬度和经度来定义我们感兴趣的线
⭐Around:结果中进行进一步筛选
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
node["natural"="peak"];
node(around:850.00)["natural"="cave_entrance"];
//⭐使用如下代码是使用结果集以外的内容
//node["natural"="peak"]->.peaks;
//node(around.peaks:850.00)["natural"="cave_entrance"];
out body;
//生成计数
//out count;
上述代码在边界框内搜索所有标记为peak的节点。这些节点将自动存储在默认集合(“ _”)中。然后,查询的第二部分会过滤掉那些被标记为洞穴并且距离先前找到的结果之一 850 米以内的节点。在这种情况下,我们的边界框内只有一座山峰(乌鲁鲁山顶峰),因此查询只返回 850 米范围内的洞穴。
如果around过滤器没有提供坐标或坐标集,那么它会使用默认集(“ _”)作为搜索的基础。但建议始终使用命名集来使您的查询更具可读性。这种使用方式around比指定固定半径或线要强大得多。我们可以进行更复杂的查询,例如查找靠近公交车站或道路的便利设施。
out count输出:计算节点数量,而不是它们的坐标和标签。如果您只想进行一些快速分析或收集一些数据,这将很有用。
提示:如果您尝试out count,Overpass Turbo 可能会警告您地图上没有可以显示的结果。只需查看数据选项卡即可。
多边形搜索
node(poly:"-25.336204100149033 131.0238147136019 -25.341828144950995 131.02072480881674 -25.341944501738343 131.02754834855062");
out body;
poly接受一个字符串参数,参数必须是包含偶数个纬度和经度对的字符串值。这些坐标应共同定义地图上的封闭形状。
poly与around的区别如下:
- 该参数必须以带引号的字符串形式提供。
- 坐标值必须用空格分隔,而不是逗号。
poly过滤器不支持基于先前提取的一组节点找到的多边形进行查询。因此,我们无法提取存储在 OpenStreetMap 中的描述封闭道路的多边形,然后在其中进行搜索。但是其它方法可以完成这个任务
多边形越复杂,搜索速度越慢。简化边界可提高性能。
查找路径
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
way;
out body;
使用way关键字即可。在上述查询中, IDE 无法为生成地图。这是因为路径没有自己的几何形状,而是与标出道路形状的一组节点相关联。在数据选项卡中,搜索way后可以发现查到的结果都是一个个node id。

因此要是想要在地图中显示路径,还需要同时输出道路关联的节点信息。
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
//创建一个包含道路和其节点的集合。
(
way;
//找到组成这些way的node信息
>;
);
//output the collection of nodes and ways
out body;
导出道路关联的节点,使用递归运算符">"。这个符号输入任意node,way,relation,并输出其所有成员。对于路径来说,way的成员是组成它的所有点。
递归运算符隐式使用默认集 ( _) 作为其输入,所以上面的代码中,way;在osm中查询结果并存放在默认集中,随后>;一句将默认集里面的内容进行递归运算并输出。
>在查询中非常常用,因为每当我们需要方法和关系的几何图形时,就得使用它。还有一个版本将从关系一直遍历到节点:>>。
如果不使用()块而只是依次查询路线和节点,则输出将只包含有关节点的数据而丢失路径数据。这是因为>查询将覆盖默认集的内容,因此我们将丢失查询结果way。因此执行遍历时,请始终使用()进行处理,除非确实想忽略父级功能。
路径的标签
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
(
way["tourism"="attraction"];
//TRYME #1, ways that are tagged as highways. This includes roads and paths
//way["highway"];
//TRYME #2, ways that are tagged as paths
//way["highway"="path"];
//TRYME #3, ways that are marked as designated pedestrian access
//way["foot"="designated"];
//TRYME #4, ways that are tagged as disused highways
//way["disused:highway"="path"];
>;
);
out body;
查询道路时与查询节点时的语法规则几乎一致。可以用tag过滤,或者搜索其附近的元素。
路径与点组合查询
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
way;
node(around:100)["amenity"];
out body;
在上述代码中,先查询范围内的道路,随后查询这些道路附近100m包含amenity标签的所有点。查询way之后,结果存在了隐藏集中,around命令在默认情况下过滤隐藏集的数据。所有的查询结果都被最开始的范围限制着。
找到经过某点的路径
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
//this block creates a collection of ways and their nodes
(
//find the nodes
node;
//find the way of which they are members
<;
);
//output the collection of nodes and ways
out body;
前文提到,>命令符可以查询实体的成员。其实可以通过成员查询其父节点,使用<命令符就可以了。先查询点,存在默认集中,然后查询通过默认集中的点的道路。是很灵活的语法。上述代码会找到边界框中所有节点以及其所属的路径。
同样存在<<命令符,会一直遍历到包含这些节点的关系
寻找关系
关系是节点和路径的集合。它们描述对象的逻辑分组,超越了它们的基本空间关系。例如,关系可用于描述:
- 一条公交线路,连接一组公交站(节点)和道路(线路)
- 行政边界
- 多边形,例如代表单个位置的建筑物集合
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
relation["boundary"="administrative"];
out body;
关系可以用关键字relation或者其缩写rel来进行查询。注意,仍然需要括号和>>关键字来显示它们的几何形状。
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
(
relation["boundary"="administrative"];
>>;
);
out body;
类型无关查询
有时候,我们只知道节点的标签,但是不知道节点的类型。例如,一家商店最初可能被添加为一个节点(一个点位置),后来改为用一条路径来表示。如果制图员为该企业所在的建筑物添加了轮廓,就可能会发生这种情况。如果想搜索所有的节点/关系/路径,当然可以构造以下语句进行:
( node["amenity"]; way["amenity"]; rel["amenity"]; );
但这是重复的。 我们可以使用更简洁的查询方法:
nw- 寻找节点和路径nr- 查找节点和关系wr- 寻找路径和关系nwr- 寻找节点、路径和关系
过滤器也是正常使用
区域Area
//find any area with this name
area["name"="Uluru-Kata Tjuta National Park"];
(
//find any ways and relations that are WITHIN that area, filtering them by their tag
wr(area)["natural"="bare_rock"];
>;
);
out body;
area在一开始进行定义,可以像bbox那样通过括号运算符来进行过滤器的应用。此查询查找乌鲁鲁-卡塔丘塔国家公园内的所有天然岩层。
area之所以有趣,是因为它们不是 OSM 数据模型的正式组成部分。它们是已自动添加到支持 Overpass API 的数据库中的功能。这意味着它们可以通过 API 进行查询和操作,但您无法对其进行编辑。
系统会自动为一系列不同类型的方式和关系创建区域,其中包括:(这些不翻译看着更直白)
- any relation with a
typeofmultipolygonand aname - any relation with a
typeofboundaryand aname - any relation that has an
admin_levelandnameattribute - any relation with a
postal_codeoraddr:postcode - a wide range of different named ways including buildings, highways, natural features, leisure areas, places, historic and tourism areas
说到底,区域就是从更广泛数据库中存在的方式和关系的子集派生出的一组特征。从查询的角度来看,可以将它们视为其他元素,并使用标准范围的过滤器找到它们。例如在这个查询中,我们根据名称查找一个区域。随后,过滤器area将我们感兴趣的路径(或节点或关系)限制为我们已经找到的区域内的路径。这种类型的空间查询通常不适用于路径和关系。
如果使用命名集,可能看起来更加清晰一些:
area["name"="Uluru-Kata Tjuta National Park"]->.ourArea;
(
way(area.ourArea)["natural"="bare_rock"];
;
);
如果我们想查找节点或关系,那么我们可以使用以下任一方法:
node(area.ourArea);
relation(area.ourArea);
查询包含特征的区域
(
//查询乌鲁鲁山,存在summit集中
node["name:pjt"="Uluṟu"]->.summit;
//在summit集中,找到它们所属区域并存在命名集someArea中
.summit is_in ->.someArea;
//过滤出someArea集中的所有道路。
way(pivot.someArea);
>;
);
out body;
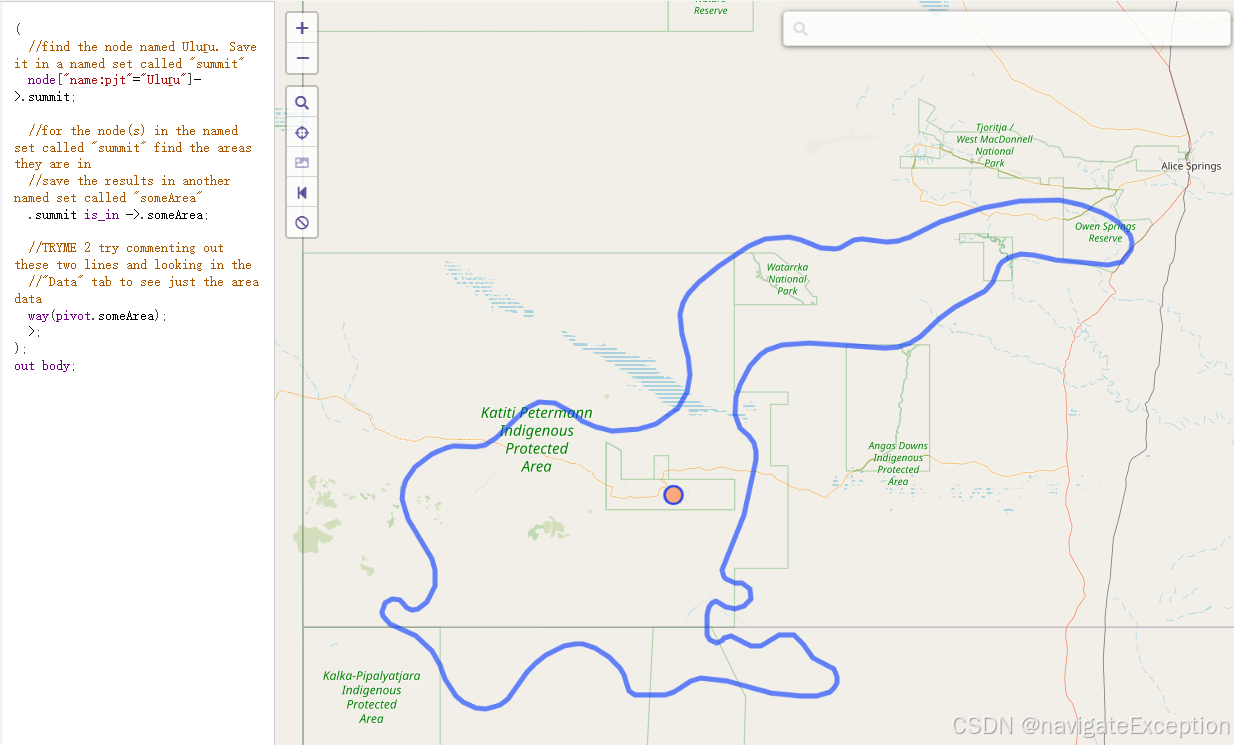
有时我们想找到包含一些感兴趣特征的区域。例如,找到消防站的行政区域。或者包含游乐区的公园。
is_in语句允许我们根据一些先前发现的节点、方式或关系来查找区域。在本例中,用is_in来查找哪些区域包含这些元素。这将是覆盖该点的所有区域。不仅是乌鲁鲁的边界,还包括乌鲁鲁-卡塔丘塔国家公园、彼得曼、麦克唐奈地区等一直到澳大利亚的边界。
Overpass API 将为我们提供与区域相关的标签,但不提供其几何形状。想要几何形状,则需要找到创建该区域的原始方式或关系。pivot过滤器会在结果集中找到区域对应的OSM数据库特征。
这其实很好理解,前文所述,区域这个东西并不是OSM数据库里面的,而是overpass api提供的。因此需要一个单独的语句来提取数据库特征。
查找特征相关的区域
[bbox:-25.38653, 130.99883, -25.31478, 131.08938];
(
relation["name"="Mutitjulu"] ->.rel;
.rel map_to_area ->.mutitjulu;
nwr["leisure"](area.mutitjulu);
>;
nwr["building"](area.mutitjulu);
>;
);
out body;
map_to_area关键字用于将查询得到的多边形元素(通常是闭合的路或关系)转换成一个区域(area)对象。这个关键字在处理由多个部分组成的复杂区域时非常有用,比如城市、湖泊或多边形的路。
pivot与map_to_area的区别
pivot是关于元素的转换,通常是从一个元素类型转换到另一个与之相关的元素类型。map_to_area是特定于将多边形元素转换成区域对象。
简而言之,如果你需要将查询结果从一种类型转换为另一种类
使用Nominatim搜索区域
{{geocodeArea:"Uluṟu-Kata Tjuta National Park"}}->.searchArea;
(
//find all nodes tagged as caves within the area we found
node["natural"="cave_entrance"](area.searchArea);
);
out body;
Overpass Turbo IDE为核心 OverpassQL 语言提供了多种扩展。
我们在教程的早期就遇到了其中一种情况。我们过去常常{{bbox}}根据 IDE 中的地图当前视图自动定义边界框。
另一个有用的扩展是geocodeArea,它在本查询中得到了演示。
该扩展接受一个搜索参数,用于使用 Nominatim API 进行自由文本搜索以查找第一个匹配区域。
这是一种更灵活的区域匹配方式。否则,我们只能使用正则表达式匹配标签值。
(这是 Overpass Turbo 独有的功能)
设置超时
[out:csv(::id, ::lat, ::lon, name; true; ",")][timeout:60];
node(-25.38653, 130.99883, -25.31478, 131.08938)["natural"="cave_entrance"];
out body;
指定超时时间以秒为单位
举个例子
up主地图侦探的一期视频:风车与桥梁
这个例子可以说是我看过的最精彩的推理过程之一。挑战的难度极高,如果没有overpass api的使用,挑战的难度会更难,基本不可能完成。
牢骚
许久没有更新博客,一是去旅游了,二是开学军训。其实手边压了几个稿件迟迟没发,每天心力交瘁,只能看看这种地图侦探游戏,回顾回顾往日的峥嵘岁月,学点看起来无关紧要的知识了,现在的时间实在太碎片了。
这篇博客也是作为我后期学习的一个指南,基本都是在翻译国外的一个教程,并没有深入研究。或许这种囫囵吞枣的学习是不对的吧,但是学一点总比不学强。
下次再更新类似的东西,我打算将图片搜索地理位置的所有知识点和方法做个汇总,看看自己能不能玩转这东西,也去当个地图侦探博主玩玩。
临了有感,有道是:
游历山河心已远,军训归来笔未闲。
稿件堆积情难抑,地图侦探忆往昔。
碎片时光学无疆,翻译教程探新知。
囫囵吞枣非良策,但求知途不言弃。

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









