






overpass turbo的query语言分为QL和XML两种,所获得的结果是一样的。
XML语言需要以<osm-script></osm-script>包围,<osm-script output="json">可以定义输出数据的格式。
—— query
任何检索都要以query开始,<query></query>,通过<query type="node/way/relatipn/area">定义搜索数据的类型。
如果<query></query>缺失,则默认为<query type="node"></query>
—— bbox
<query><!-- replace by an effective query type; if this element is missing, a default <query type="node"> is assumed -->
<bbox-query s="51.0" w="7.0" n="52.0" e="8.0"/>
</query>
通过定义bounding box选择了这个范围内的所有地理信息, w=left | e=right | n=top | s=bottom
<osm-script>
<query type="way">
<bbox-query e="7.157" n="50.748" s="50.746" w="7.154"/>
</query>
<print/>
</osm-script>
完整query代码,选择了bounding box下所有way的数据, node, way, relation, area都可以通过这种方式获取
—— tags
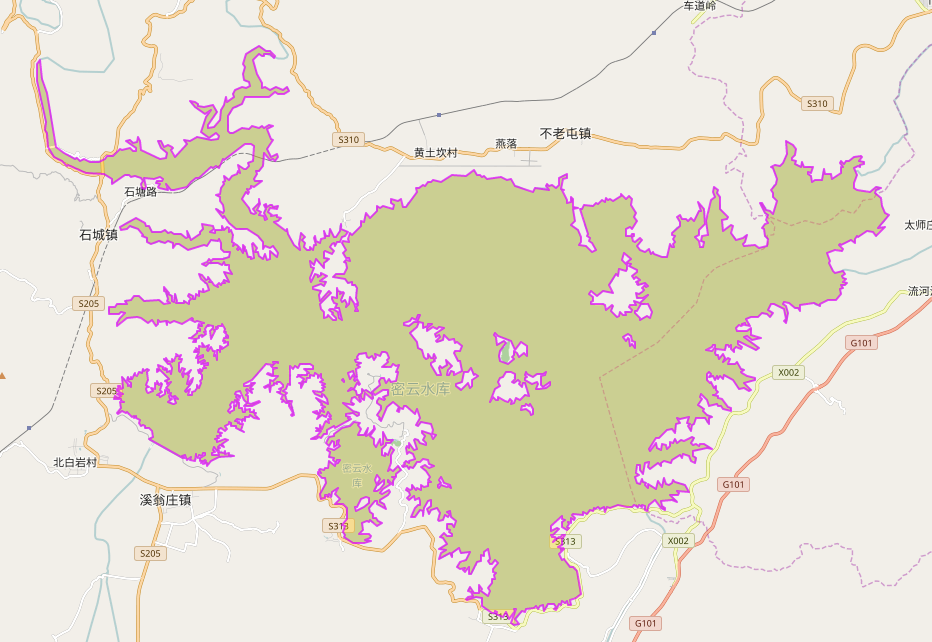
有时候我们不想通过bbox查找,而想通过一些我们已知的属性(property)进行查找,必须我们要搜索整个密云水库( 不造为啥选了这里当试验点XD)的相关数据:

通过openstreetmap我们知道密云水库是一个relation,并且知道它的一些关键属性,比如name="密云水库", natural="water"等,下面我们喜欢通过这些属性搜索到密云水库的相关数据。
<osm-script>
<query type="relation">
<has-kv k="name" v="密云水库"/>
</query>
<print/></osm-script>
这样我们提取了密云水库这个relation下的所有数据,但是查看结果发现数据全是way的,没有node(这也是浪费了几天时间折腾爬虫的原因),这个时候我们需要一个recurse的过程,具体方法下面再讲。
当然,也可以同时使用bbox和tag作为条件进行检索:
<osm-script>
<query type="relation">
<has-kv k="name" v="密云水库"/>
<bbox-query e="116.9254" n="40.5111" s="40.4851" w="116.8770"/>
</query>
<print/>
</osm-script>
以及多个tag作为条件的检索:
<osm-script>
<query type="node">
<has-kv k="highway" v="bus_stop"/>
<has-kv k="shelter" v="yes"/>
<bbox-query e="7.25" n="50.8" s="50.7" w="7.1"/>
</query>
<print/></osm-script>反向选择:
<osm-script>
<query type="way">
<has-kv k="highway" modv="not" regv="."/>
<bbox-query e="7.18" n="50.75" s="50.74" w="7.17"/>
</query>
</osm-script>选择了不包含highway tag的way数据
—— tags特别篇,关于针对name的检索
有时候并不清楚某个地点的确切名称,这时候需要使用模糊检索的功能(其实就是正则表达式啦):
<has-kv k="name" regv="holtorf"/>
选择了包含holtorf的所有结果。
<has-kv k="name" regv="^Holtorf"/>选择了holtorf作为名字开头的所有结果。
<has-kv k="name" regv="Holtorf$"/>
holtorf作为名字结尾。
<has-kv k="name" regv="holtorf|Gielgen"/>
名为holtorf或gielgen的都符合搜索条件。
—— union operator
union顾名思义,起到的是集合的作用。我们使用<query></query>进行检索的时候,一次只能选择一种数据类型:
<query
type=
"node"
>
,union的作用就是将多个query集合起来。
<osm-script>
<union>
<query type="node">
<has-kv k="amenity" v="fire_station"/>
<bbox-query e="7.3" n="50.8" s="50.6" w="7.0"/>
</query>
<query type="way">
<has-kv k="amenity" modv="" v="fire_station"/>
<bbox-query e="7.3" n="50.8" s="50.6" w="7.0"/>
</query>
<query type="relation">
<has-kv k="amenity" modv="" v="fire_station"/>
<bbox-query e="7.3" n="50.8" s="50.6" w="7.0"/>
</query>
</union>
<union>
<item/>
<recurse type="down"/>
</union>
<print/>
</osm-script>
注意第一个union中三个query的排列顺序,这和第二个union有关。
在第二个union中定义了递归
(recurse)
,即将node、way和relation的数据根据层级相互绑定,并规定了递归的模式为down,意为从顶部开始递归。
——————————————————————————————
<osm-script>
<union>
<query type="node">
<has-kv k="name" v="密云水库"/>
</query>
<query type="way">
<has-kv k="name" v="密云水库"/>
</query>
<query type="relation">
<has-kv k="name" v="密云水库"/>
</query>
</union>
<union>
<item/>
<recurse type="down"/>
</union>
<print/>
</osm-script>
——————————————————————————————














 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









