







一、聚合函数
多行函数 (聚合函数):作用于多行,返回一个值。
--这里的1表示主键那一列
select count(1) from emp;---查询总数量
select sum(sal) from emp;---工资总和
select max(sal) from emp;---最大工资
select min(sal) from emp;---最低工资
select avg(sal) from emp;---平均工资
二、分组统计
分组统计需要使用 GROUP BY 来分组
语法:
SELECT * |列名 FROM 表名 {WEHRE 查询条件} {GROUP BY 分组字段} ORDER BY 列名 1 ASC|DESC,
列名 2...ASC|DESC
分组查询中,出现在 group by 后面的原始列,才能出现在select后面
没有出现在 group by 后面的列,想在 select 后面,必须加上聚合函数。
聚合函数有一个特性,可以把多行记录变成一个值
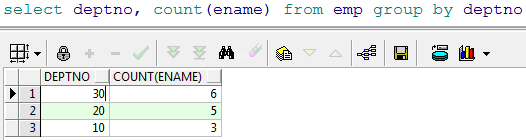
- 查询每个部门的人数
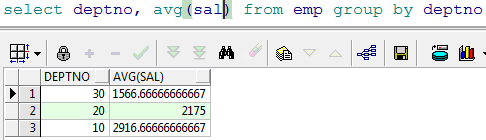
- 查询出每个部门的平均工资
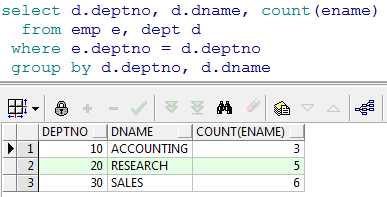
- 如果我们想查询出来部门编号,和部门下的人数

- 按部门分组,查询出部门名称和部门的员工数量
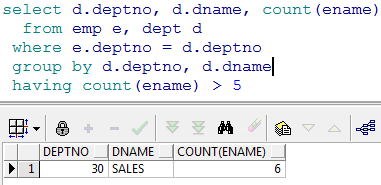
- 查询出部门人数大于 5 人的部门
分析:需要给 count(ename)加条件,此时在本查询中不能使用 where,可以使用 HAVING
- 查询出部门平均工资大于 2000 的部门
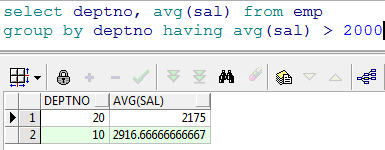
---查询出平均工资高于2000的部门信息
select e.deptno, avg(e.sal) asal
from emp e
group by e.deptno
having avg(e.sal)>2000;
---所有条件都不能使用别名来判断,因为条件的优先级大于select,所以运行where时,别名还未成立
--比如下面的条件语句也不能使用别名当条件
select ename, sal s from emp where sal>1500;
---查询出每个部门工资高于800的员工的平均工资
select e.deptno, avg(e.sal) asal
from emp e
where e.sal>800
group by e.deptno;
----where是过滤分组前的数据,having是过滤分组后的数据。
---表现形式:where必须在group by之前,having是在group by之后。
---查询出每个部门工资高于800的员工的平均工资
---然后再查询出平均工资高于2000的部门
select e.deptno, avg(e.sal) asal
from emp e
where e.sal>800
group by e.deptno
having avg(e.sal)>2000;
















 4773
4773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











