







1. Robots协议
robots是网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。
当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有的页面。
2. 样例
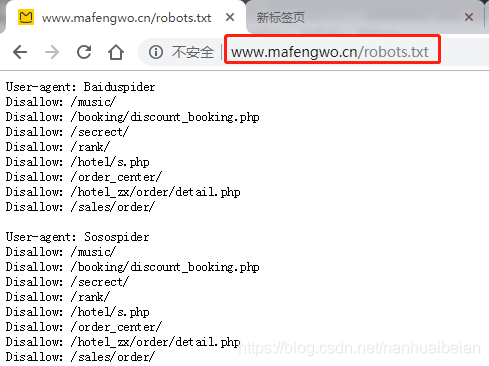
User-agent:描述了搜索爬虫的名称,例如User-agent: Baiduspider表示只对百度爬虫有效
Disallow:指定了不允许抓取的目录
Allow:允许抓取的目录
允许所有爬虫访问任何目录代码:
User-name:*
Disallow:
禁止所有爬虫访问任何目录代码:
User-name:*
Disallow:/
3.常见爬虫的名称
| 爬虫名称 | 名称 | 网站 |
|---|---|---|
| BaiduSpider | 百度 | www.baidu.com |
| Googlebot | 谷歌 | www.google.com |
| 360Spider | 360搜索 | www.so.com |
| YodaoBot | 有道 | www.youdao.com |
| ia_archiver | Alexa | www.alexa.cn |
| Scooter | altavista | www.altavista.com |


















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











