







一、前期准备
- 观察网页 url 或者通过最下面的分页审查元素:
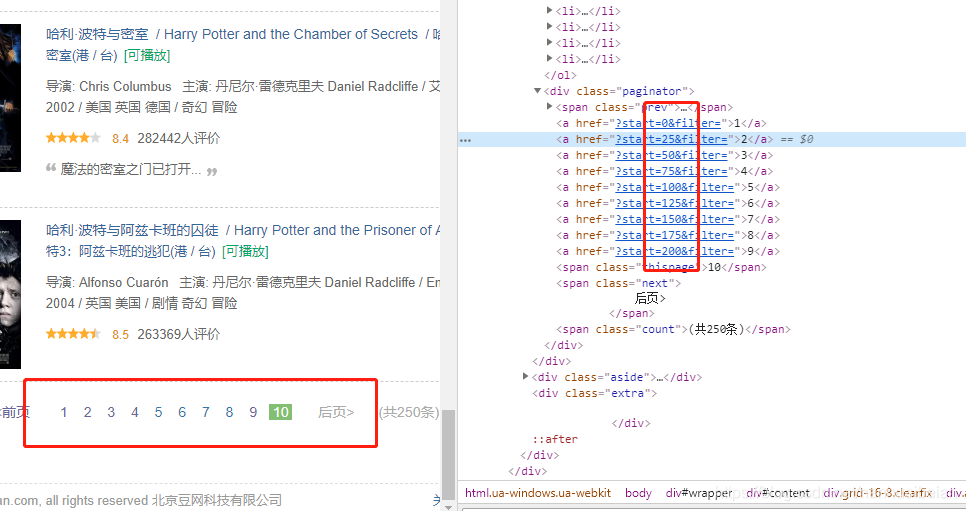
发现规律,0-25-50。。。递增,以此确定爬取 page 页码 - 确定爬取的内容
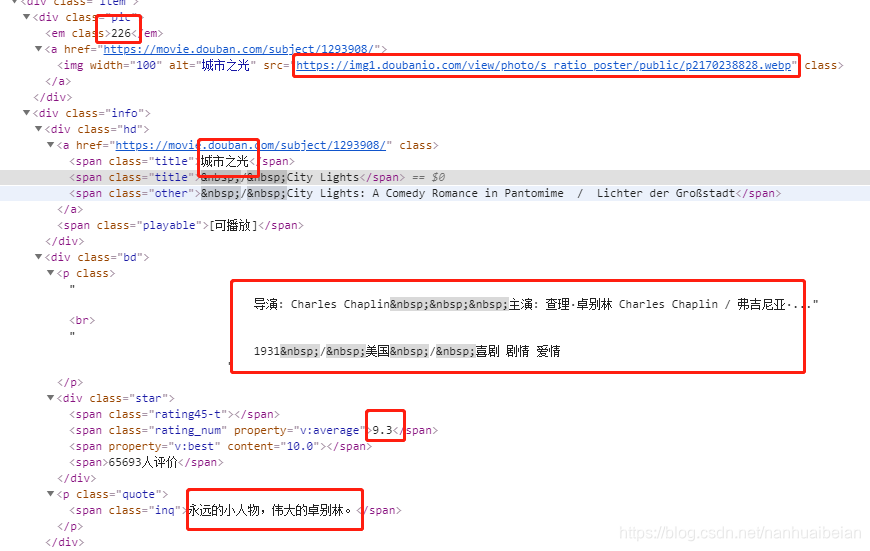
名称、图片、排名、评分、作者、简介
二、代码
- 请求网页代码:
# 请求豆瓣电影
def request_douban(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except requests.RequestException:
return None
- 对爬取的结果进行分析:
# 对爬取的结果解析
def parse_result(html):
soup = BeautifulSoup(html,'lxml')
rows = soup.find(class_='grid_view').find_all('li')
bords = []
for row in rows:
board = {}
board['name'] = row.find(class_='title').string
board['img'] = row.find('a').find('img').get('src')
board['index'] = row.find(class_='').string
board['score'] = row.find(class_='rating_num').string
board['author'] = row.find('p').text
if(row.find(class_='inq') !=None):
board['intr'] = row.find(class_='inq').string
else:
board['intr'] = '无'
bords.append(board)
return bords
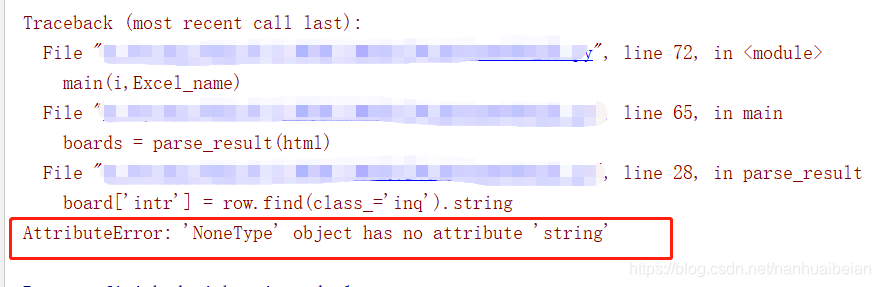
这里有个点需要注意下,有些电影无简介,所以需要对 ‘intr’ 这里判断下
不然那就会出现如下错误:
3. 初始化 Excel 表
# 初始化 Excel
def excel_write(str):
# 设置要存入的 Excel 表
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('豆瓣电影Top250')
into = ['名称','图片','排名','评分','作者','简介']
for i in range(len(into)):
sheet.write(0,i,into[i])
book.save(str)
- 存储数据到 Excel 表中
def write_excel(boards,name):
workbook = xlrd.open_workbook(name)
sheets = workbook.sheet_names()
worksheet = workbook.sheet_by_name(sheets[0])
rows_old = worksheet.nrows
new_workbook = copy(workbook)
new_worksheet = new_workbook.get_sheet(0)
i = 0
for borad in boards:
n = i + rows_old
new_worksheet.write(n,0,borad['name'])
new_worksheet.write(n,1,borad['img'])
new_worksheet.write(n,2, borad['index'])
new_worksheet.write(n,3,borad['score'])
new_worksheet.write(n,4,borad['author'])
new_worksheet.write(n,5,borad['intr'])
i +=1
new_workbook.save(name)
- 定义主函数
def main(page,name):
url = 'https://movie.douban.com/top250?start={}&filter='.format(page*25)
html = request_douban(url)
boards = parse_result(html)
write_excel(boards,name)
if __name__ == '__main__':
Excel_name = '豆瓣最受欢迎的250部电影.xls'
excel_write(Excel_name)
# 爬取 10 页的数据
for i in range(10):
main(i,Excel_name)
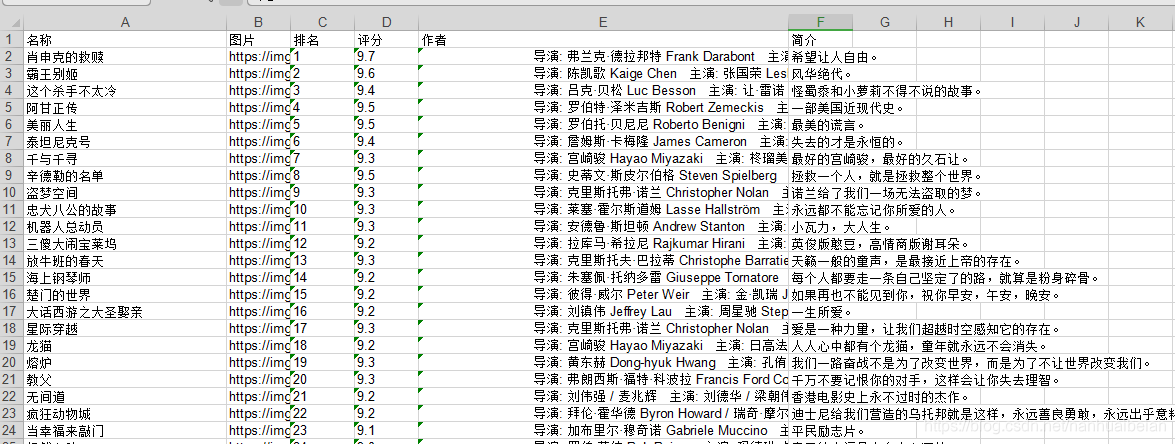
成功图:


















 3705
3705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











