







先说 Trie树
Trie树,又称字典树,单词查找树或者前缀树,是一个用于快速检索的多叉树. 典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计(@july)。如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树.
Trie利用字符串的公共前缀来节省存储空间,并且能够以空间换时间.
盗用别人的一张图, 给出一组单词,inn, int, at, age, adv, ant, 我们可以得到下面的Trie:
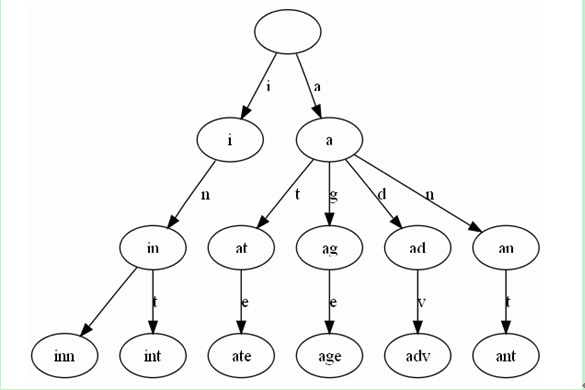
根据上面的trie,我们可以
1. 计算任意某两个单词的最长公共前缀,就是我们待会要详细说明的LCA算法.
2. 快速计算某个单词的出现次数.也就是我们上面说的以空间换时间的方法,建树与查询同时进行,每次根据单词查询或新建节点,计数.时间复杂度为O(N*length),length表示字符串的平均长度.
我们再通过trie,即前缀树,来引出
后缀树.
后缀的含义:
对于字符串XMADAMYX,他的后缀是从后往前数的任意连续序列,如X,YX,MYX...XMADAMYX等都是其后缀,我们记作S[i],表示从第i个到最后的后缀.
S[1], XMADAMYX, 也就是字符串本身,起始位置为1
S[2], MADAMYX,起始位置为2
S[3], ADAMYX,起始位置为3
S[4], DAMYX,起始位置为4
S[5], AMYX,起始位置为5
S[6], MYX,起始位置为6
S[7], YX,起始位置为7
S[8], X,起始位置为8
接着,我们用上面trie的方法,把一个字符串的所有后缀建立trie.再盗用一张图.如下:
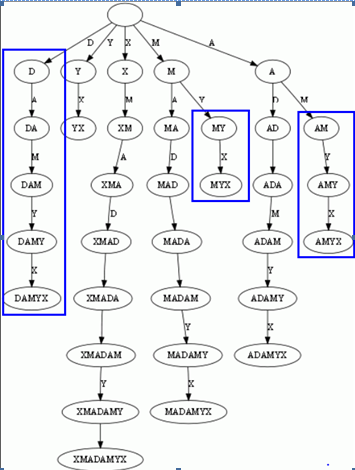
正如我们上面说的,一般trie是许多字符串生成的前缀树,而这里我们用一个字符串生成N个后缀子串,再用后缀子串生成trie.
上图中,有许多中间节点是多余的,我们要用最少的节点来表示,并且所有的后缀都是叶子节点,那么就做如下的压缩:
1. 每个节点可以存储多个字母.
2. 字符串后加一个结尾,如’$’,那么就不会有任意后缀是其他后缀的前缀,压缩的时候就不会有后缀被压缩掉.
于是,我们得到了压缩的后缀树:
继续盗图:
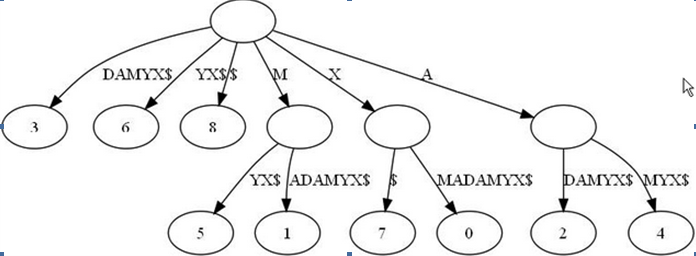
于是我们概括为 ( 后缀树=后缀子串们+ trie ).
最长回文字串与后缀树
那么后缀子串的trie与最长回文有什么关系呢?
S1=XMADAMYX反过来是S2=XYMADAMX,S1(4)=DAMYX,S2(5)=DAMX,他们的最长公共前缀是DAM,也就是最长回文子串的MADAM的半径.
于是,我们得到了解决最长回文子串的方法.
S1 和翻转 S2,生成的所有后缀子串压入到trie中,计算S1(i)与S2(n-i+1)节点的最低公共祖先,即其最长公共前缀,再得到最长回文子串.
如下图,用S1+’$’ 即翻转后的S2+’#’建立后缀树,得到如下的树.

根据我们上面的描述,我们现在的任务是计算S1(i)和S2(n-i+1)节点的最低公共祖先.如上图1$与8#,2$与7#...等的LCA,最后得出最长的.
具体应用:
1. 查找字符串o是否在字符串S中。
方案:用S构造后缀树,按在trie中搜索字串的方法搜索o即可。
原理:若o在S中,则o必然是S的某个后缀的前缀。
听起来有点拗口,举个例子。例如S: leconte,查找o: con是否在S中
则o(con)必然是S(leconte)的后缀之一conte的前缀
有了这个前提,采用trie搜索的方法就不难理解了。
2. 指定字符串T在字符串S中的重复次数。
方案:用S+’$'构造后缀树,搜索T节点下的叶节点数目即为重复次数
原理:如果T在S中重复了两次,则S应有两个后缀以T为前缀,重复次数就自然统计出来了。
3. 字符串S中的最长重复子串
方案:原理同2,具体做法就是找到最深的非叶节点。
这个深是指从root所经历过的字符个数,最深非叶节点所经历的字符串起来就是最长重复子串。
为什么要非叶节点呢?因为既然是要重复,当然叶节点个数要>=2。
4. 两个字符串S1,S2的最长公共部分
方案:将S1#S2$作为字符串压入后缀树,找到最深的非叶节点,且该节点的叶节点既有#也有$(无#)。
大体原理同3















 2407
2407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









