一、容器简介
容器是一个将多个元素组合到一个单元的对象,是代表一组对象的对象,容器中的对象成为它的元素。容器适用于处理各种类型的对象的聚集,例如存储、获取、操作聚合数据,以及聚合数据的通信。容器只保存Object型的引用,这是所有类的基类,因此容器可以保存任何类型的对象。
二、容器接口的分类
根据容器所包含的对象的不同可以将容器接口分为Collection和Map两大类,实现Collection接口的容器实现是一个包含孤立元素的对象集合,而实现Map接口的容器实现是一个包含成对元素的对象集合。
1)、Collection接口代表一组对象,这些对象称为它的元素。Collection是容器继承树中的顶层接口,作为接口它定义了15个方法,但没有提供具体的实现。
Collection接口如下:
public
interface
Collection<
E>
extends
Iterable<
E>{
//接口的基本操作
int
size();
//返回容器中元素的数目
boolean
isEmpty();
//容器中没有元素的时候返回true
boolean
contains(
Object
element);
//如果容器中已经持有参数则返回true
boolean
add(
E
elements);
//确保容器持有此参数,如果没有将此参数添加进容器则返回false
boolean
remove(
Object
element);
//如果参数在容器中,则移除此参数的一个实例,如果做了移除动作则返回true
Iterator<
E>
iterator();
//返回一个Iterator,可以用来遍历容器中的元素
boolean
equals(
Object
element)
//比较容器与给定对象是否相等,如相等则返回ture,此方法重载了Object的equals()方法
int
hashCode();
//返回对象的hash码
boolean
containsAll(
Collection<
?>
c);
//如果容器持有参数中的所有元素则返回true
boolean
addAll(
Collection<
?
extends
E>
c);
//添加参数中的所有元素,只要添加了任意元素就返回true
boolean
removeAll(
Collection<
?>
c);
//移除参数中的所有元素,只要有移除动作发生就返回true
boolean
retainAll(
Collection<
?>
c);
//只保留参数中的元素,只要Collection发生了改变就返回true
void
clear();
//移除容器中的所有元素
Object []
toArray ();
//返回一个数组,包含容器中的所有元素
<
T> T[]
toArray(
T[]
a);
//返回一个数组,包含容器中的所有的元素,其类型与数组a的类型相同,而不是单纯的Object(你必须对此数组做类型转换)
}
Collection接口方法使用示例:
import java.util.*;
class
ContainerDemo{
@SuppressWarnings(
"unchecked")
//解决编译时报错:使用了未经检查或不安全的操作,注意:要了解详细信息,请使用 -Xlint:unchecked重新编译
public
static
void
main(
String []
args){
List
c1 =
new
ArrayList(
25);
//25是初始容量的参数
c1.
add(
new
String(
"One"));
c1.
add(
new
String(
"Two"));
String
s=
"Three";
c1.
add(s);
for(
int
i=
0;i<
c1.
size();i++)
System.
out.
println(
c1.
get(i));
Object[]
array=
c1.
toArray();
//返回一个数组包含容器中所有的元素
String[]
str=(
String[])
c1.
toArray(
new
String[
0]);
//返回一个数组,包含容器中所有的元素,使用强制类型转换使返回的值为String型
System.
out.
println(
Arrays.
toString(array));
System.
out.
println(
Arrays.
toString(str));
Collection
c2 =
new
ArrayList(
2);
c2.
add(
new
String(
"Four"));
c2.
add(
new
String(
"Five"));
c1.
addAll(c2);
for(
int
i=
0;i<
c1.
size();i++)
System.
out.
println(
c1.
get(i));
Collection
c3 =
new
ArrayList(
2);
c3.
add(
new
String(
"Two"));
c3.
add(
new
String(
"Five"));
c1.
removeAll(c3);
for(
int
i=
0;i<
c1.
size();i++)
System.
out.
println(
c1.
get(i));
c1.
retainAll(c2);
for(
int
i=
0;i<
c1.
size();i++)
System.
out.
println(
c1.
get(i));
}
}
2)Map接口定义与应用
Map是一个将键映射到值的对象,映射不能包含重复的键,即每个键最多可以映射到一个值。
Map接口如下:
public
interface
Map<
K,
V>{
int
size();
// 返回容器中元素的数目
boolean
isEmpty();
// 容器中没有元素的时候返回true
boolean
containsKey(
Object
key);
//如果容器中已经持有参数键值则返回true
boolean
containsValue(
Object
value);
//如果容器已经持有参数值则返回true
V
get(
Object
key);
//取得键值所对应的值
V
put(
V
key,
K
value);
//向容器中添加一个键值对
V
remove(
Object
key);
//如果键值参数在容器中,则移除此参数键值对应的键值对实例
void
putAll(
Map
t);
//添加参数中的所有的键值对实例
void
clear();
public
Set<
K>
keySet();
//返回Map中包含的键值Set。返回的是一个实现Set接口的对象,对该对象的操作就是对映射的操作。这样的集合称为视图
public
Collection<
V>
values();
//返回Map中所有的值的Collection
public
Set<
Map.
Entry<
K,
V>>
entrySet();
//返回Map中包含的键值对的Set
public
interface
Entry{
K
getKey();
V
getValue();
V
setValue(
V
value)
}
//Map接口提供的一个小小的嵌套接口
}
3) 集合容器Set
Set是不包含重复元素的Collection。Set对于包含非重复,且无排序要求的数据结构非常合适。Set接口如下:
public
interface
Set<
E>
extends
Collection<
E>{
int
size();
boolean
isEmpty();
boolean
contains(
Object
element);
boolean
add(
E
elements);
boolean
remove(
Object
element);
Iterator<
E>
iterator();
boolean
equals(
Object
element);
int
hashCode();
boolean
containsAll(
Collection<
?>
c);
boolean
addAll(
Collection<
?
extend
E>
c);
boolean
removeAll(
Collection<
?>
c);
boolean
retainAll(
Collection<
?>
c);
void
clear();
Object[]
toArray();
<
T>
T[]
toArray(
t[]
a);
}
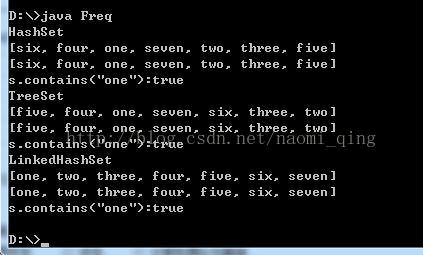
Set接口元素非重复性演示
import java.util.*;
public
class
Freq{
public
static
void
main(
String
args[]){
test(
new
HashSet<
String>());
test(
new
TreeSet<
String>());
test(
new
LinkedHashSet<
String>());
}
static
void
fill(
Set<
String>
s){
s.
addAll(
Arrays.
asList(
"one two three four five six seven".
split(
" ")
));
}
public
static
void
test(
Set<
String>
s){
System.
out.
println(
s.
getClass().
getName().
replaceAll(
"\\w+\\.",
"")
);
fill(s);
fill(s);
fill(s);
System.
out.
println(s);
s.
addAll(s);
s.
add(
"one");
s.
add(
"one");
s.
add(
"one");
System.
out.
println(s);
System.
out.
println(
"s.contains(\"one\"):"+
s.
contains(
"one"));
}
}
结果是:
SortedSet接口的附加功能:
Comparator comparator() //返回当前Set使用的Comparator,或者返回null,表示自然方式排序
Object first() //返回容器中的第一个元素
Object last() //返回容器中的最末一个元素
SortedSet subSet(fromElement,toElement) //生成此Set的子集,范围从fromElement(包含)到toElement(不包含)
SortedSet headSet(toElement)//生成此set的子集,由小于toElement的元素组成
SorttedSet tailSet(fromElement)//生成此set的子集,由大于或等于fromElement的元素组成
sortedSet接口附加功能演示
import java.util.*;
public
class
Freq{
@SuppressWarnings(
"unchecked")
public
static
void
main(
String
args[]){
SortedSet
sortedSet =
new
TreeSet(
Arrays.
asList(
"one two three four five six seven eigth".
split(
" ")));
System.
out.
println(sortedSet);
Object
low =
sortedSet.
first();
Object
high=
sortedSet.
last();
System.
out.
println(low);
System.
out.
println(high);
Iterator
it=
sortedSet.
iterator();
for(
int
i=
0;i<=
6;i++){
if(i==
3) low=
it.
next();
if(i==
6) high=
it.
next();
else
it.
next();
}
System.
out.
println(low);
System.
out.
println(high);
System.
out.
println(
sortedSet.
subSet(low,high));
System.
out.
println(
sortedSet.
headSet(high));
System.
out.
println(
sortedSet.
tailSet(low));
}
}
4)Set实现
Set实现分为通用实现和专用实现。通用实现包括HashSet、TreeSet和LinkedSet;专用实现包括EnumSet和CopyonWriteArraySet.
(1)HashSet
HashSet比TreeSet要快的多。但是HashSet不提供排序保障。HashSet中迭代时间与元素数量和存储桶数量的总和成正比。系统默认的HashSet
的初始容量是16。我们可以使用int构造器指定初始容量,下面一行代码就是分配一个初始容量为64的HashSet:
Set<String> s = new HashSet<String>(64);
一般设置的HashSet的初始容量应该是你预期集合会增长到的尺寸的两倍。HashSet的底层是由HashMap构建的。
对于HashSet,我们要为存放在散列表的各个对象定义hashCode()和equals()
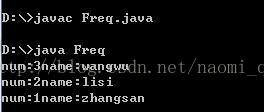
HashSet的应用实例:
import java.util.*;
public
class
Freq{
@SuppressWarnings(
"unchecked")
public
static
void
main(
String
args[]){
HashSet
hs =
new
HashSet();
hs.
add(
new
Student(
1,
"zhangsan"));
hs.
add(
new
Student(
2,
"lisi"));
hs.
add(
new
Student(
3,
"wangwu"));
hs.
add(
new
Student(
1,
"zhangsan"));
Iterator
it =
hs.
iterator();
while(
it.
hasNext()){
System.
out.
println(
it.
next());
}
}
}
class
Student{
int
num;
String
name;
Student(
int
num,
String
name)
{
this.
num=num;
this.
name=name;
}
public
String
toString(){
return
"num:"+num+
"name:"+name;
}
public
int
hashCode(){
//重载了hashCode()方法
return num*
name.
hashCode();
}
public
boolean
equals(
Object
o){
//重载了equals()方法
Student
s = (
Student)o;
return num==
s.
num&&
name.
equals(
s.
name);
}
}
结果是:
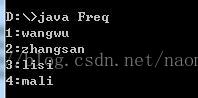
(2)TreeSet
TreeSet是SortedSet的唯一实现形式,采用红黑树的数据结构进行排序元素,当需要按值排序迭代时,那么需要使用TreeSet。TreeSet由
TreeMap实例支持,TreeSet保证排序后的Set按照升序排列元素,根据使用的构造方法的不同,可能会按照元素的自然顺序进行排序,或按照在
创建Set时所提供的比较器进行排序,这个Set是一个有序集合,默认是按照自然顺序进行排序,意味着
TreeSet中元素要实现Comparable接口,
所以我们可以
在构造TreeSet对象时,传递实现Comparator接口的比较器对象。
范例:
import java.util.*;
public
class
Freq{
@SuppressWarnings(
"unchecked")
public
static
void
main(
String
args[]){
TreeSet
ts =
new
TreeSet();
ts.
add(
new
Student(
2,
"zhangsan"));
ts.
add(
new
Student(
3,
"lisi"));
ts.
add(
new
Student(
1,
"wangwu"));
ts.
add(
new
Student(
4,
"mali"));
Iterator
it =
ts.
iterator();
while(
it.
hasNext()){
System.
out.
println(
it.
next());
}
}
}
class
Student
implements
Comparable {
int
num;
String
name;
Student(
int
num,
String
name)
{
this.
num=num;
this.
name=name;
}
static
class
compareToStudent
implements
Comparator{
public
int
compare(
Object
o1,
Object
o2){
Student
s1=(
Student) o1;
Student
s2=(
Student) o2;
int
rulst=
s1.
num>
s2.
num
?
1
:(
s1.
num==
s2.
num
?
0
:-
1);
if(rulst==
0){
rulst=
s1.
name.
compareTo(
s2.
name);
}
return rulst;
}
}
public
int
compareTo(
Object
o){
int
result;
Student
s=(
Student)o;
result = num>
s.
num
?
1
:(num==
s.
num
?
0
:-
1);
if(result ==
0){
result =
name.
compareTo(
s.
name);
}
return result;
}
public
String
toString(){
return
Integer.
toString(num)+
":"+name;
}
}
结果是:
(3)LinkedHashSet
LinkedHashSet在某种程度上介于HashSet和TreeSet之间,此链接列表定义了迭代顺序,即按照将元素插入到集合中的顺序进行迭代,而运行速度和
HashSet一样快。
(4)EnumSet
EnumSet是用于枚举类型的高性能Set实现。枚举集的所有成员都必须是相同的枚举类型。在内部,它表示为向量,典型情况下是单一的long值。枚举
集支持对枚举类型范围的迭代
(5)CopyOnWriteArraySet
CopyOnWriteArraySet是通过复制数组支持的实现。所有导致变化的操作(比如add、set和remove)都通过制作数组的新副本而实现,从不需要加锁,即
使迭代也可以与元素插入和删除安全的并发进行。这个实现只适用于很少修改但是频繁迭代的集。
5)列表容器List
List是一个有序的Collection接口,它有时被称为序列。次序是List最重要的特点。它确保维护元素特定的顺序。List非常适合实现有顺序要求
的数据结构,例如堆栈和队列。
List接口如下:
public
interface List<
E>
extends Collection<
E>{
E get(
int index);
//取特定元素。返回给定地址index的元素
E set(
int index);
//用给定的对象替换List中指定位置的元素,并且返回被替换的元素
boolean add(
E elements);
//插入一个给定的对象
boolean add(
int index,
E elements);
//在指定位置插入一个给定的对象,而原先在此位置的元素,以及其后续的元素依次右移
E remove(
int index);
//在List中删除指定位置index的元素,并将其后续的元素依次左移,返回被删除的元素
boolean addAll(
int index ,
Collection<
?
extend
E> c);
//将给定容器c中的所有的元素加入到本集合中index位置,而原先位置及其后面的元素依次往后移动
int indexOf(object o);
//查找。返回对象在List中第一次出现的索引值,如果对象不是List的一个元素则返回-1
int LastIndexOf(object o);
//返回对象在List中最后一次出现的索引值,如果对象不是List的一个元素则返回-1
ListIterator<
E> ListIterator();
//迭代器。按照一定顺序返回List中的元素的一个列表迭代器
ListIterator<
E> ListIterator(
int index);
//按照一定顺序返回List中的元素的一个列表迭代器,从给定的位置index开始
List<
E> subList(
int from,
int to);
//范围视图。返回该List中从fromindex到toindex指定元素组成的一个List
}
List接口方法演示
package LianXi;
import java.util.*;
public class ListDemo {
public static List fill(List fill_a){
fill_a.add("a");
fill_a.add("b");
fill_a.add("c");
return fill_a;
}
private static boolean b;
private static Object o;
private static int i;
private static Iterator it;
private static ListIterator lit;
public static void basicTest(List a){
a.add(0,"x");
a.add("8");
System.out.println("初始List A为:"+a);
a.addAll(fill(new ArrayList()));//追加新的List
System.out.println("追加新的List后,List A为:"+a);
b=a.contains("c");
if(b){
System.out.println("元素c包含在List A中");
}
else{
System.out.println("元素c没有包含在List A中");
}
//判断子List<a,b,c>是否在ListA中
b=a.containsAll(fill(new ArrayList()));
if(b){
System.out.println("List<a,b,c>包含在ListA中");
}
else{
System.out.println("List<a,b,c>没有包含在ListA中");
}
o= a.get(1);//得到位置1处的元素
System.out.println("位置1元素为:"+o);
i=a.indexOf("c");//指定元素c第一次出现的位置
System.out.println("元素c第一次出现的位置为:"+i);
b= a.isEmpty();
if(b){
System.out.println("List A是空的");
}
else{
System.out.println("List A不是空的");
}
a.remove(1);
System.out.println("位置1元素被删除后,List A为:"+a);
a.remove("c");//删除第一个“c”元素
a.set(1, "y");//将位置1的元素替换为y
System.out.println("位置1的元素被替换为y,List A为:"+a);
}
public static void main(String[] args) {
// TODO Auto-generated method stub
basicTest(new LinkedList());
}
}
运行结果:
初始List A为:[x, 8]
追加新的List后,List A为:[x, 8, a, b, c]
元素c包含在List A中
List<a,b,c>包含在ListA中
位置1元素为:8
元素c第一次出现的位置为:4
List A不是空的
位置1元素被删除后,List A为:[x, a, b, c]
位置1的元素被替换为y,List A为:[x, y, b]
6)List实现
List有两个通用的List实现:ArraList和LinkedList.一个专用的List实现时CopyOnWriteArrayList
(1)ArrayList
ArrayList是由数组实现的List,是最常用的List实现。它提供常量时间的位置访问,而且速度很快,它不必为List中的每个元素分配一个节点对象。
而且在同时移动多个元素时它可以利用System.arrayCopy,可以把ArrayList看做没有同步开销的Vector。但是向List中间插入和移动元素的速度
很慢,ListIterator只应该用来由后向前遍历ArrayList,而不是用来插入和移除元素,因为那比LinkedList开销要大很多。
ArrayList有一个调优参数--初始容量,它是指在ArrayList被迫增长之前其可以容纳的元素数量。
(2)LinkedList
如果我们采用的数据结构经常需要将元素添加到List开头,或者迭代List以便从其内部删除元素,那么LinkedList是首要考虑的选择因为这些
操作在LinkedList上需要常量时间,而在ArrayList中需要线性时间。而位置操作在LinkedList中需要线性时间,在ArrayList上需要常量时间
,LinkedList没有用于调优的参数,但它有7个可选方法,分别是Clone、AddFirst、removeFirst、addLast、getLast和removeLast
(3)CopyOnWriteArrayList
CopyOnWriteArrayList是通过复制数组支持的List,这个实现在性质上和CopyOnWriteArraySet类似,不必进行同步,并且确保迭代器不抛出
ConcurrentModificationexception异常。这个实现非常适合这样的情况:遍历很频繁,而且可能很消耗时间。
(4)ArrayList、LinkedList和CopyOnWriteArrayList三者的区别
ArrayList的底层是由数组实现的,LinkedList的底层是由链表实现的。所以,对于随机访问get和set,ArrayList要优于LinkedList因为
LinkedList要移动指针。对于新增和删除add和remove,LinkedList要优于ArrayList,因为ArrayList要移动数据
ArrayList和LinkedList都是线程不安全的,CopyOnWrteArrayList是线程安全的
7)使用List实现堆栈和队列
(1)堆栈
堆栈(stack)又名叠堆,是一种简单的数据结构,它是用后进先出的方式来描述数据的存取方式。
堆栈的定义:限定只能在固定一端进行插入和删除操作的线性表,允许进行插入和删除操作的一端称为栈顶,另一端称为栈底。向栈中插入数据的操作
称为压入(Push),从栈中删除数据称为弹出(Pop).
LinkedList实现堆栈:
package LianXi;
import java.util.LinkedList;
public class ListDemo {
private LinkedList list = new LinkedList();
public void push(Object v){
list.addFirst(v);
}
public Object top(){ //压栈
return list.getFirst();
}
public Object pop(){ //弹栈
return list.removeFirst();
}
public static void main(String[] args) {
ListDemo stack = new ListDemo();
for (int i=0;i<10;i++){
stack.push(new Integer(i));
//打印当前的栈顶
System.out.print(stack.top()+" ");
}
System.out.println();
System.out.print(stack.top()+" ");
//弹栈,并打印当前弹出的元素
System.out.print(stack.pop()+" ");
System.out.print(stack.pop()+" ");
System.out.print(stack.pop()+" ");
System.out.print(stack.pop()+" ");
}
}
运行结果:
0 1 2 3 4 5 6 7 8 9
9 9 8 7 6
(2)队列
队列作为另一种数据结构,它用先进先出的方式来描述数据的存取方式。
定义:只能在表的一端进行插入操作,在表的另一端进行删除操作的线性表。
8)Map容器
Map是一个键值映射的对象,而且键不能相同,不能包含重复的就按,每个键最多映射到一个值。
Map通用实现包括:HashMap、TreeMap、LinkedHashMap;
专用实现包括:EnumMap、WeakHashMap、IdentityHashMap
(1)HashMap是基于散列表的实现。插入和查询“键值对”的开销是固定的,可以通过构造器设置容量和负载因子,以调整容器的性能,如果希望获取
最大的速度而不关心迭代的顺序,可以采用HashMap
HashMap演示:
package LianXi;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
public class ListDemo {
public static void main(String[] args) {
HashMap hm = new HashMap();
hm.put(new Integer(1),"A");
hm.put(new Integer(2), "B");
hm.put(new Integer(3), "C");
hm.put(new Integer(4), "D");
hm.put(new Integer(5), "E");
Set s=hm.keySet();
Iterator i=s.iterator();
while(i.hasNext()){
Object k=i.next();
Object v=hm.get(k);
System.out.println(" "+k+"="+v);
}
}
}
运行结果:
1=A
2=B
3=C
4=D
5=E
代码说明:
输出的结果的顺序与加入键值对的顺序没有必然的联系。我们先获取Key的一个Set,然后用迭代器访问Set取出Key。再用Key去得到value
,这是访问Map所有元素的一种方法。
(2)TreeMap
TreeMap继承于AbstractMap,同时实现了SortedMap接口,这与前面提到的TreeSet相似,而且在处理由TreeMap的keySet()方法得到的集合与TreeSet相同。TreeMap的访问
方法与HashMap相同,而且不管元素加入的顺序如何,最后输出的结果总是按照键(Key)从小到大排列的,因此要求Key实现Comparable接口,并且更重要的是相互之间
是可比的。
TreeMap示例:
package LianXi;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeMap;
public class ListDemo {
public static void main(String[] args) {
TreeMap tm1= new TreeMap();
TreeMap tm2=new TreeMap();
//tm1和tm2元素的输入顺序不同
tm1.put(new Integer(1), "A");
tm1.put(new Integer(2), "B");
tm1.put(new Integer(3), "C");
tm1.put(new Integer(4), "D");
tm1.put(new Integer(5), "E");
tm2.put(new Integer(5), "E");
tm2.put(new Integer(3), "C");
tm2.put(new Integer(4), "D");
tm2.put(new Integer(1), "A");
tm2.put(new Integer(2), "B");
//通过集合+迭代器的方法来遍历TreeMap对象tm1
Set s1=tm1.keySet();
Iterator i1= s1.iterator();
while(i1.hasNext()){
Object k= i1.next();
Object v= tm1.get(k);
System.out.print(" "+k+"="+v);
}
System.out.println();
//通过集合+迭代器的方法来遍历TreeMap对象tm2
Set s2=tm2.keySet();
Iterator i2= s2.iterator();
while(i2.hasNext()){
Object k= i2.next();
Object v= tm2.get(k);
System.out.print(" "+k+"="+v);
}
}
}
//运行结果
1=A 2=B 3=C 4=D 5=E
1=A 2=B 3=C 4=D 5=E
(3)LinkedHashMap
LinkedHashMap提供了LinkedHashSet不具备的两个功能:第一,当创建LinkedHashMap时可以按照键访问进行排序,即与被很少查看的值关联的键被安排到Map的末尾;
第二,LinkedHashMap提供removeEldestEntry方法(),可以覆盖这个方法,以便在新的映射对加入到Map时自动强制地删除旧映射对的策略。
LinkedHashMap演示实例:
package LianXi;
import java.util.LinkedHashMap;
import java.util.Map;
public class MyLinkedHashMap extends LinkedHashMap {
private final int Capacity;
//ListDemo构造函数
public MyLinkedHashMap(int maxCapacity){
super(maxCapacity,0.75f,true);
//LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
//构造一个带指定初始容量、加载因子和排序模式的空 LinkedHashMap 实例。
Capacity=maxCapacity;
}
//重载removeEldestEntry()方法,使ListDemo的实例最多容纳Capacity个元素
protected boolean removeEldestEntry(Map.Entry eldest){
return this.size()>Capacity;
}
}
package LianXi;
public class ListDemo{
public static void main(String ags[]){
MyLinkedHashMap mym=new MyLinkedHashMap(5);
//初始化MyLinkedHashMap
mym.put(new Integer(1), "A");
mym.put(new Integer(2), "B");
mym.put(new Integer(3), "C");
mym.put(new Integer(4), "D");
mym.put(new Integer(5), "E");
System.out.println("初始化Map序列:"+mym);
//通过get操作将前3个元素依次放到Map头部,最后被放在头部的是第3个元素
for(int i=1;i<4;i++){
mym.get(new Integer(i));
}
System.out.println("移动队尾3个元素后的Map序列:"+mym);
//添加第6个元素,但是mym的最大值为5
//所以删除最不“常用”的元素,即尾部的元素“D”
mym.put(6, "F");
System.out.println("添加新元素替换队尾元素后的序列"+mym);
}
}
(4)EnumMap
EnumMap在内部实现为Array,它是用于枚举键的高性能Map实现。这个实现结合了Map接口的丰富功能和安全性以及数组的高速访问。如果我们希望把枚举映射到值,就应该
使用EnumMap,而不是数组。
(5)WeakHashMap
WeakHashMap是值存储对其键的弱引用的Map接口实现。
(6)IdentityHashMap
IdentityHashMap是散列表基于标识的Map实现。
8)hashCode()方法
(1)散列码
散列码就是一种通过不可逆的散列(Hash)算法对一个键(数据)进行计算获得一个“唯一”的值,并将这个值放入散列表中。这个值可以对这个键(数据)进行标识。在
查找键(数据)的时候,可以通过散列表中的此值来快速定位键(数据),从而有效减少开销
散列算法就是一种用于实现散列的方法,它接受一个查找键(数据),计算出该键(数据)的散列码,然后再将此散列码压缩到散列表的范围内。总之,使用散列的目的在于:
想要使用一个对象查找另一个对象。
(2)Java中的hashCode()方法
对于HashMap,Java将键-值中的“键”作为输入数据进行散列,并形成散列表。Java中的对象都继承于基类Object,Object类有一个方法hashCode(),它默认是使用对象的地址作为散列算法的输入,返回一个整数散列码,所以Java中每个类都有此方法。
hashCode()方法是根据对象的内存地址来返回一个散列码,这样内容不同的对象实例就会返回不同的散列码,一般我们在构建自己的类时需要重写此方法。重载hashCode()
方法的同时需要重载Object类中另一个方法equals()。HashMap使用equals()判断当前的“键”是否与表中存在的“键”相同。重载hashCode()方法需要遵循以下原则:
《1》如果某个类覆盖了hashCode(),那么它也应该覆盖equals(),反之亦然。
《2》如果equals()返回相同的值,那么hashCode()也应该返回相同的值
《3》在同一个程序的两次执行中,对象的散列码可以不同
(3)重载hashCode()方法的常用散列算法
对于字符串散列码的计算一般采用如下方法:将每个字符的Unicode值乘以一个该字符在字符串的位置的因子,散列码就是所有这些乘积的和。Java中的String的hashCode()
就是用常数31作为因子。
对于基本类型的散列码的计算,一般都是转化为int型。在Java中对于long型的数据,一般是用移位操作将64位的值转换为32位的int值。对于double和float类型,一般用其
封装类的Double.doubleToLongBits(key)或者Float.floatToLongBits(key),然后通过移位和异或来完成
重载hashCode()方法演示:
package LianXi;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
public class ListDemo{
private static List created = new ArrayList();//创建一个ArrayList对象created
private String s;
private int id=0;
ListDemo(String str){
s=str;
created.add(s);
Iterator it = created.iterator();
while(it.hasNext()){
if(it.next().equals(s))
id++;
}
}
public String toString(){ //定义toString方法
return "String: "+s+"id: "+id+"hashCode():"+hashCode();
}
public int hashCode(){//重载hashCode()方法
int result=17;
result=37*result+s.hashCode();
result=37*result+id;
return result;
}
public boolean equals(Object o){//重载equals()方法
return (o instanceof ListDemo)&&s.equals(((ListDemo)o).s)&&id==((ListDemo)o).id;
//instanceof通过返回一个布尔值来指出,这个对象是否是这个特定类或者是它的子类的一个实例。
}
public static void main(String ags[]){
Map map =new HashMap();
ListDemo[] ld=new ListDemo[10];
for(int i=0;i<ld.length;i++){
//实例化10个CountedString对象,且其String值是一样的,而id值不一样
ld[i]=new ListDemo("hi");
//利用ListDemo作为hashMap的键
//在填充hashMap容器的时候,自动调用hashCode(),计算散列码
map.put(ld[i], new Integer(i));
}
//输出map,输出结果不是按输入顺序进行输出的
System.out.println(map);
for(int i=0;i<ld.length;i++){
System.out.print("Looking up"+ld[i]+"value==");
System.out.println(map.get(ld[i]));
}
}
}
9)迭代器
迭代器(Iterator)是一个对象,它的工作是遍历并选择序列中的对象,它提供一种方法访问一个容器(Container)对象中各个元素,而又不需要暴露该对象的内部细节。
此外,迭代器通常被称为“轻量级”对象,因为创建它的代价小。因此经常见到对迭代器有限制,例如:某些迭代器只能单向移动
(1)迭代器的使用
使用方法Iterator(),容器返回一个Iterator的next()方法时,它返回序列的第一个元素。
用next()获取序列中的下一个元素,并将游标(Cursor)向后移动
使用hasNext()检查序列中是否还有元素
使用remove()将上次返回的元素从迭代器中移除
ListIterator从Iterator继承了next()、hasnext()和remove()3个方法,hasPrevious()和previous()模拟了hasnext()和next(),只是方向不同。hashnext()和next()指向游标之后
的元素,而hasPrevious()和Prevous()指向游标之前的元素
(2)迭代器的主要用法:
首先用hasNext()作为循环条件,再用next()方法得到每个元素,最后再进行相关的操作。
10)HashMap和HashTable的区别
(1)HashTable的方法是同步的,HashMap不能同步
(2)HashTable不允许null值(key和value都不可以),HashMap允许null值(key和value都可以)
(3)HashTable有一个contains()方法,功能和containsValue()功能一样
(4)HashTable使用Enumeration,HashMap使用Iterator
(5)hash数组的初始化大小及其增长方式不同
(6)哈希值的使用不同,HashTable直接使用对象的hashCode,而HashMap会重新计算hash值























 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









