







Lucene简介和怎样创建索引可以参考我前面的两篇博客Lucene全文检索基础和Lucene创建索引,索引创建以后可以使用luke(使用和Lucene版本相对应的Luke版本,比如Lucene版本是4.3,那么使用4.3 版本的Luke)查看。
索引创建
以新闻文档为例,每条新闻是一个document,新闻有news_id、news_title、news_source、news_url、news_abstract、news_keywords这6个域,添加两个news document到索引中,下面再贴一下创建索引的代码:
package ucas.ir.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.*;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class CreateIndex {
public static void main(String[] args) {
// 第一步:创建分词器
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_43);
// 第二步:创建indexWriter配置信息
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_43, analyzer);
// 第三步:设置索引的打开方式
indexWriterConfig.setOpenMode(OpenMode.CREATE);
// 第四步:设置索引第路径
Directory directory = null;
// 第五步:创建indexWriter,用于索引第增删改.
IndexWriter indexWriter = null;
try {
File indexpath = new File("/Users/yp/Documents/workspace/UCASIR/WebContent/index");
if (indexpath.exists() != true) {
indexpath.mkdirs();
}
directory = FSDirectory.open(indexpath);
if (indexWriter.isLocked(directory)) {
indexWriter.unlock(directory);
}
indexWriter = new IndexWriter(directory, indexWriterConfig);
} catch (IOException e) {
e.printStackTrace();
}
Document doc1 = new Document();
doc1.add(new IntField("news_id", 1, Store.YES));
doc1.add(new TextField("news_title", "围棋界对阿法狗集体服软 柯洁能成为人脑救星吗", Store.YES));
doc1.add(new TextField("news_source", "搜狐体育", Store.YES));
doc1.add(new TextField("news_url", "http://sports.sohu.com/20160316/n440533081.shtml", Store.YES));
doc1.add(new TextField("news_abstract",
"2016年3月16日 - 阿法狗4比1大胜李世石,它的表现几乎征服了整个围棋界,世界冠军级棋手们纷纷表示自己不是阿法狗的对手", Store.YES));
doc1.add(new TextField("news_keywords", "阿法狗,李世石,柯洁", Store.YES));
Document doc2 = new Document();
doc2.add(new IntField("news_id", 2, Store.YES));
doc2.add(new TextField("news_title", "任志强违纪究竟违反了什么?内幕惊动党中央", Store.YES));
doc2.add(new TextField("news_source", "西陆频道", Store.YES));
doc2.add(new TextField("news_url", "http://www.xilu.com/20160302/1000010000932707.html", Store.YES));
doc2.add(new TextField("news_abstract",
"2016年3月2日 - 核心:任志强在公开场合发表坚持资产阶级自由化立场、反对四项基本原则、反对党的改革开放决策的言论,妄议中央大政方针,公开与中央唱反调,背离了党的根本宗...",
Store.YES));
doc2.add(new TextField("news_keywords", "任志强,微博,被关", Store.YES));
try {
indexWriter.addDocument(doc1);
indexWriter.addDocument(doc2);
indexWriter.commit();
indexWriter.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("index create success!");
}
}
再luke中查看:
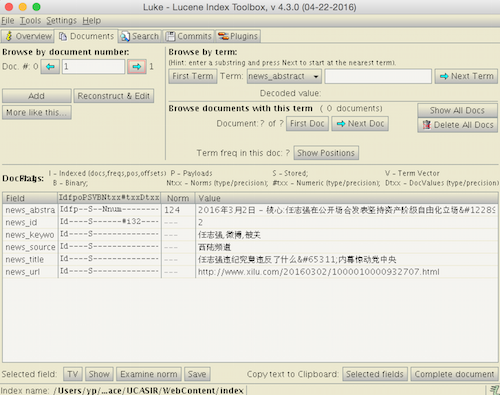
检索索引
索引创建好以后,查询可分为以下几个步骤:
1.设置查询索引的目录(这里就是上面创建索引的目录).
2.创建indexSearcher.
3.设置query的分词方式
4.设置查询域(比如查询域为”news_title”,那么就到新闻标题域去比对)
5.设置查询字符串,也就是要查询的关键词.
6.返回结果是一个文档集合,放在TopDocs中,通过循环TopDocs数组输出查询结果.
package ucas.ir.lucene;
import java.io.File;
import java.io.IOException;
import javax.print.Doc;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.core.KeywordAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class IndexSearch {
public static void main(String[] args) {
Directory directory = null;
try {
File indexpath = new File("/Users/yp/Documents/workspace/UCASIR/WebContent/index");
if (indexpath.exists() != true) {
indexpath.mkdirs();
}
//设置要查询的索引目录
directory = FSDirectory.open(indexpath);
//创建indexSearcher
DirectoryReader dReader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(dReader);
//设置分词方式
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_43);
//设置查询域
QueryParser parser = new QueryParser(Version.LUCENE_43, "news_title", analyzer);
// 查询字符串
Query query = parser.parse("阿法狗");
System.out.println("query:"+query.toString());
// 返回前10条
TopDocs topDocs = searcher.search(query, 10);
if (topDocs != null) {
System.out.println("符合条件第文档总数:" + topDocs.totalHits);
for (int i = 0; i < topDocs.scoreDocs.length; i++) {
Document doc = searcher.doc(topDocs.scoreDocs[i].doc);
System.out.println("news_id= " + doc.get("news_id"));
System.out.println("news_title= " + doc.get("news_title"));
System.out.println("news_source=" + doc.get("news_source"));
System.out.println("news_url=" + doc.get("news_url"));
System.out.println("news_abstract=" + doc.get("news_abstract"));
System.out.println("news_keywords=" + doc.get("news_keywords"));
}
}
directory.close();
dReader.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
这个例子中设置的查询域为news_title,查询词为”阿法狗”,那么新闻标题中有”阿法狗”的就会被返回。
结果:
query:news_title:阿 news_title:法 news_title:狗
符合条件第文档总数:1
news_id= 1
news_title= 围棋界对阿法狗集体服软 柯洁能成为人脑救星吗
news_source=搜狐体育
news_url=http://sports.sohu.com/20160316/n440533081.shtml
news_abstract=2016年3月16日 - 阿法狗4比1大胜李世石,它的表现几乎征服了整个围棋界,世界冠军级棋手们纷纷表示自己不是阿法狗的对手
news_keywords=阿法狗,李世石,柯洁查询域设置为news_keywords,查询词设置为微博,检索结果:
query:news_keywords:微 news_keywords:博
符合条件第文档总数:1
news_id= 2
news_title= 任志强违纪究竟违反了什么?内幕惊动党中央
news_source=西陆频道
news_url=http://www.xilu.com/20160302/1000010000932707.html
news_abstract=2016年3月2日 - 核心:任志强在公开场合发表坚持资产阶级自由化立场、反对四项基本原则、反对党的改革开放决策的言论,妄议中央大政方针,公开与中央唱反调,背离了党的根本宗...
news_keywords=任志强,微博,被关总结
Lucene有多种分词方式和查询方式,上面的例子索引创建和索引查询都用的标准分词,后面会继续学习。
















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











